Temporal Shift Module(TSM) 部署在自己电脑上并训练自己的数据集
引言:
本小白第一次写博客,如有不妥请多多包含。
能接触到TSM还是因为毕设的原因。本小白今年本科大四,在毕设的时候选择了 “用事件相机进行人体动作的识别” 这个项目。该项目旨在应用事件相机能很好的应对光线变化产生的影响,来为独居老年人提供发生医学事故的检测,如在晚上黑暗的环境下摔倒,发生心脏病而倒下,头痛而晕倒等。我当时所负责的是应用转换后的事件数据(事件相机产生的事件数据转换为frame类型的数据)来进行人体动作识别模型的训练。
所以当时跟导师讨论之后,就决定使用TSM。TSM 是一门先进的视频理解的技术,加入了时空特征的信息学习,既能有3D-CNN的良好性能,又能保持有2D-CNN的运算量简单。接下来我们来一一介绍如何在自己的电脑上训练自己的数据集。
前提
在github上下载TSM源码,以下是我训练TSM之前所需要的:
- Pytorch 1.10.0;TSM 源码是基于pytorch写的,所以pytorch框架得有。
- Ffmpeg;由于我们要处理视频文件,所以视频处理工具也得有。
我简单描述一下我所理解的TSM训基本工作流程:
- 准备好视频数据集;
- 从视频数据集里面提取帧;
- 给提取的帧生成标签;
- 传入帧和标签进行模型训练。
所以我就是按照这个流程来一步步的开展TSM训练即可。
视频数据集准备:
我们当时因为先用UCF101这个数据集先进行了测试,成功进行TSM训练后,再进行我们自己数据的训练。所以构建我们自己的数据集时,是按照UCF101数据集的格式来进行构造的。我们的event dataset的目录层级是这样的:
- Event dataset
- videos
- AskForHelp
- v_AskForHelp_g01_c01.avi(每一个视频小片段对应一个动作)
- v_AskForHelp_g01_c02.avi
- ....
- FallDown
- v_FallDown_g01_c01.avi
- v_FallDown_g01_c02.avi
- ...
- ...
- AskForHelp
- videos
数据集的准备可能就比较麻烦一点,因为需要人手去剪辑。当时我们用事件相机去录制好几个动作的长视频,每个长视频都包含不同方向的动作录制,所以后期需要我们一个个去剪辑每个动作成v_动作名_g0x_c0x.avi的片段。
这里再解释一下视频小片段的命名规则,g0x表明该动作的第几个长视频,c0x表明在g0x的长视频中的第几个动作片段。
帧提取:
准备好视频数据集之后,就到帧的提取。TSM源码中已有帧的提取和标签的生成的相关代码,我们只要会调用它们就可以了。帧的提取主要运行的是temporal-shift-module-master\tools 目录下的vid2img_ucf101.py 这篇代码 (这篇代码借鉴了csdn上另一位大佬的博客,算是TSM启蒙的一篇了)。
在终端运行代码: python vid2img_ucf101.py 视频文件的总路径 提取帧后存放的路径;
记得后面跟两个路径的参数。
ffmpeg的用处就是在这里了。一开始关于ffmpeg还有个小bug的出现:我确认安装好了ffmpeg但在提取帧的时候确说我找不到ffmpeg调用不到。通过万能的csdn,还是解决了这个小bug的:就是在ffmpeg调用语句上指明bin目录,修改代码如下:
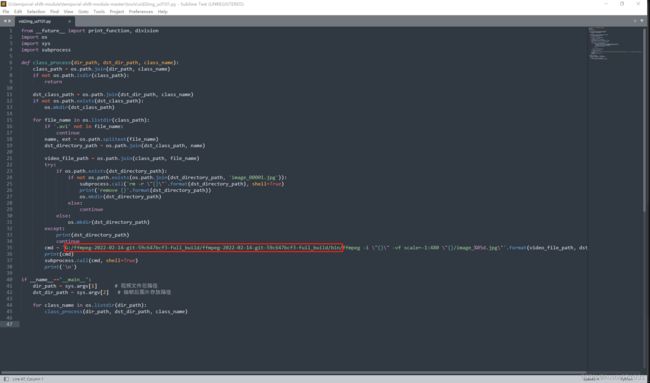
标签生成:
标签的生成也是调用源码为我们准备好的代码,主要运行的是temporal-shift-module-master\tools 目录下的gen_label_ucf101.py 这篇代码(这篇代码也是借鉴了上面所提到的博客)。
在此之前,我们得先把我们的视频数据分成训练集和测试集。因为我们是按照UCF101数据集来构造我们的数据集并准备训练,所以训练集和测试集的准备也按照UCF101的来。准备如下图所示: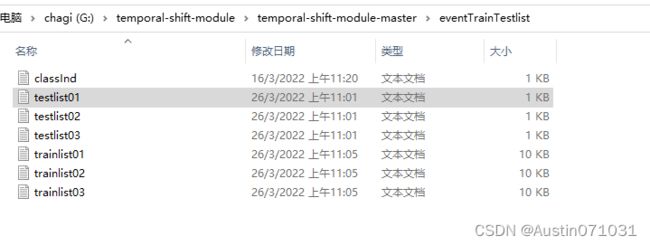
可以看到,classInd.txt文件里有我们数据集的类:

然后分别有3个测试集和3个训练集。记得分训练测试集是拿视频数据去分,而不是提取的帧去分。可以在网上搜索分训练测试集的脚本来进行划分,因为划分都是随机的,所以我是跑3次脚本就得到3个测试训练集来。
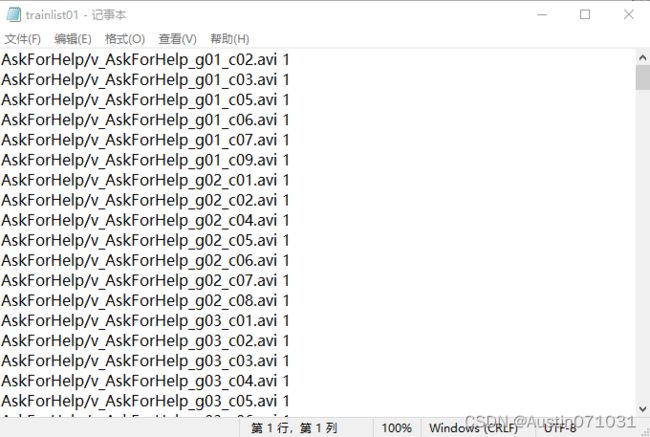
训练集.txt 里的内容:
测试集.txt里的内容:
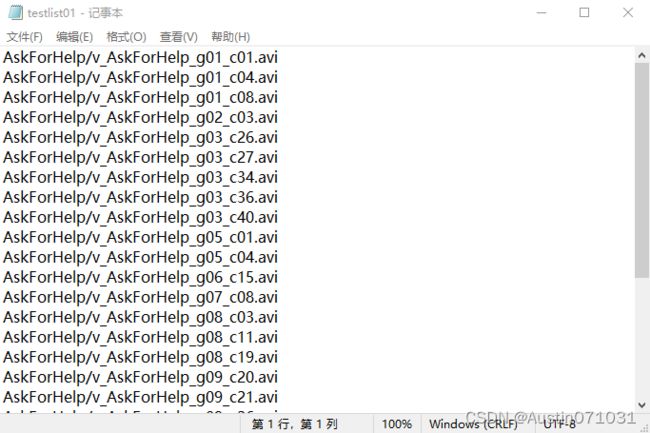
脚本的划分通常只会有视频小片段的文件名,但我们需要的是如上图所示的格式,训练集.txt里的每一行最后的数字是对应动作的类别,可以在classInd.txt里一一对应。测试集.txt每一行的最后是没有类别号的。所以划分后需要我们自己编写简单的编辑文件脚本来进行修改,可以在网上进行搜索现成的然后按自己的需求进行修改即可。
准备好训练测试集后,需要对gen_label_ucf101.py 进行几处修改:
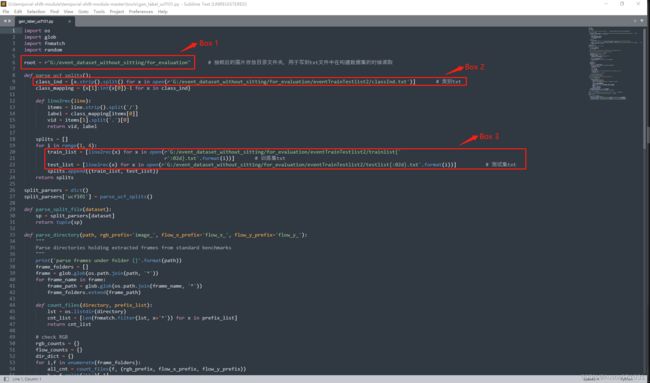
 Box 1:修改为数据集的主目录,如:G:\temporal-shift-module-master\event_dataset;
Box 1:修改为数据集的主目录,如:G:\temporal-shift-module-master\event_dataset;
Box 2:修改为数据集中训练测试集文件夹中的classInd.txt文件路径;
Box 3:修改为修改为数据集中训练测试集文件夹中的训练集和测试集的路径;
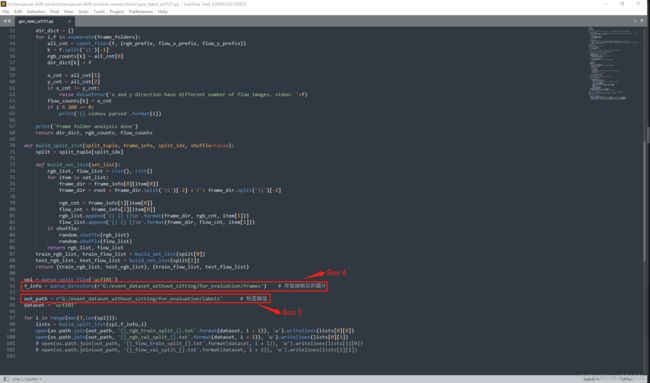
Box 4:修改为数据集中的提取帧的存放文件夹路径;
Box 5:修改为数据集中存放标签的路径;
修改完成后在终端运行代码:python gen_label_ucf101.py
在生成的标签文件中,大家要多注意每一行的视频文件路径是否正确,很多时候需要我们通过编写脚本来进行修补的。
模型训练
终于来到最终环节——训练模型。
首先最重要的一步,传入我们的数据集:修改 temporal-shift-module-master\ops 目录下的dataset_config.py。

Box 1:修改为TSM源码的主目录,如:G:/temporal-shift-module-master;
Box 2:修改为classInd.txt文件的目录,可以在标签文件夹下复制一份过来存放;
Box 3:为ROOT_DATASET(Box 1的目录)+ 提取帧文件的目录信息。主要修改+号后半段的目录信息;
Box 4:分别修改为训练集的标签文件路径以及测试集的标签文件路径。指明某一个标签文件即可,不是指明一整个标签文件夹;
Box 5:这是一个坑....一开始没主要这里的Box 5,训练时候一直说找不到提取帧来训练,困惑了好久....还是因为一个命名错误导致。所以要主要你提取的帧图片的命名格式是什么,是img_00001.jpg 还是image_00001.jpg。这里做相应的修改即可。
传入好数据集后,可以开始训练。
在终端运行代码:python main.py event5 RGB --arch resnet50 --num_segments 8 --gd 20 --lr 0.01 --wd 1e-4 --lr_steps 20 40 --epochs 300 --batch-size 64 -j 16 --dropout 0.5 --consensus_type=avg --eval-freq=1 --shift --shift_div=8 --shift_place=blockres –npb
根据自己电脑的能力,适当修改batch-size,lr_steps和num-segments。
至此TSM 训练可以开始啦。训练期间遇到的bug不算难,大都可以通过网上搜索的经验来解决。
AI,计算机视觉领域在本科阶段接触的真的不多,大四才开始学习一两门AI 和 ML 的课程,对于TSM网络的构造具体理解还是受限于我的能力.....不过能成功开始训练TSM模型还是值得纪念一下的吧。搞完毕设有心思想写自己的第一篇博客来纪念一下我的毕设吧哈哈哈哈哈。
如有错误还请大家多多指点包含。
=========================================================================
更新一波(2022/10/19)
- 有小伙伴想附上训练的代码,安排上了。其实我记得我训练的时候对main.py的改动并不是很大,有可能是我不记得了......
# Code for "TSM: Temporal Shift Module for Efficient Video Understanding"
# arXiv:1811.08383
# Ji Lin*, Chuang Gan, Song Han
# {jilin, songhan}@mit.edu, [email protected]
import os
import time
import shutil
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
from torch.nn.utils import clip_grad_norm_
from ops.dataset import TSNDataSet
from ops.models import TSN
from ops.transforms import *
from opts import parser
from ops import dataset_config
from ops.utils import AverageMeter, accuracy
from ops.temporal_shift import make_temporal_pool
from tensorboardX import SummaryWriter
best_prec1 = 0
def main():
global args, best_prec1
args = parser.parse_args()
num_class, args.train_list, args.val_list, args.root_path, prefix = dataset_config.return_dataset(args.dataset,
args.modality)
full_arch_name = args.arch
if args.shift:
full_arch_name += '_shift{}_{}'.format(args.shift_div, args.shift_place)
if args.temporal_pool:
full_arch_name += '_tpool'
args.store_name = '_'.join(
['TSM', args.dataset, args.modality, full_arch_name, args.consensus_type, 'segment%d' % args.num_segments,
'e{}'.format(args.epochs)])
if args.pretrain != 'imagenet':
args.store_name += '_{}'.format(args.pretrain)
if args.lr_type != 'step':
args.store_name += '_{}'.format(args.lr_type)
if args.dense_sample:
args.store_name += '_dense'
if args.non_local > 0:
args.store_name += '_nl'
if args.suffix is not None:
args.store_name += '_{}'.format(args.suffix)
print('storing name: ' + args.store_name)
check_rootfolders()
model = TSN(num_class, args.num_segments, args.modality,
base_model=args.arch,
consensus_type=args.consensus_type,
dropout=args.dropout,
img_feature_dim=args.img_feature_dim,
partial_bn=not args.no_partialbn,
pretrain=args.pretrain,
is_shift=args.shift, shift_div=args.shift_div, shift_place=args.shift_place,
fc_lr5=not (args.tune_from and args.dataset in args.tune_from),
temporal_pool=args.temporal_pool,
non_local=args.non_local)
crop_size = model.crop_size
scale_size = model.scale_size
input_mean = model.input_mean
input_std = model.input_std
policies = model.get_optim_policies()
train_augmentation = model.get_augmentation(flip=False if 'something' in args.dataset or 'jester' in args.dataset else True)
model = torch.nn.DataParallel(model, device_ids=args.gpus).cuda()
optimizer = torch.optim.SGD(policies,
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
if args.resume:
if args.temporal_pool: # early temporal pool so that we can load the state_dict
make_temporal_pool(model.module.base_model, args.num_segments)
if os.path.isfile(args.resume):
print(("=> loading checkpoint '{}'".format(args.resume)))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print(("=> loaded checkpoint '{}' (epoch {})"
.format(args.evaluate, checkpoint['epoch'])))
else:
print(("=> no checkpoint found at '{}'".format(args.resume)))
if args.tune_from:
print(("=> fine-tuning from '{}'".format(args.tune_from)))
sd = torch.load(args.tune_from)
sd = sd['state_dict']
model_dict = model.state_dict()
replace_dict = []
for k, v in sd.items():
if k not in model_dict and k.replace('.net', '') in model_dict:
print('=> Load after remove .net: ', k)
replace_dict.append((k, k.replace('.net', '')))
for k, v in model_dict.items():
if k not in sd and k.replace('.net', '') in sd:
print('=> Load after adding .net: ', k)
replace_dict.append((k.replace('.net', ''), k))
for k, k_new in replace_dict:
sd[k_new] = sd.pop(k)
keys1 = set(list(sd.keys()))
keys2 = set(list(model_dict.keys()))
set_diff = (keys1 - keys2) | (keys2 - keys1)
print('#### Notice: keys that failed to load: {}'.format(set_diff))
if args.dataset not in args.tune_from: # new dataset
print('=> New dataset, do not load fc weights')
sd = {k: v for k, v in sd.items() if 'fc' not in k}
if args.modality == 'Flow' and 'Flow' not in args.tune_from:
sd = {k: v for k, v in sd.items() if 'conv1.weight' not in k}
model_dict.update(sd)
model.load_state_dict(model_dict)
if args.temporal_pool and not args.resume:
make_temporal_pool(model.module.base_model, args.num_segments)
cudnn.benchmark = True
# Data loading code
if args.modality != 'RGBDiff':
normalize = GroupNormalize(input_mean, input_std)
else:
normalize = IdentityTransform()
if args.modality == 'RGB':
data_length = 1
elif args.modality in ['Flow', 'RGBDiff']:
data_length = 5
train_loader = torch.utils.data.DataLoader(
TSNDataSet(args.root_path, args.train_list, num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl=prefix,
transform=torchvision.transforms.Compose([
train_augmentation,
Stack(roll=(args.arch in ['BNInception', 'InceptionV3'])),
ToTorchFormatTensor(div=(args.arch not in ['BNInception', 'InceptionV3'])),
normalize,
]), dense_sample=args.dense_sample),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True,
drop_last=True) # prevent something not % n_GPU
val_loader = torch.utils.data.DataLoader(
TSNDataSet(args.root_path, args.val_list, num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl=prefix,
random_shift=False,
transform=torchvision.transforms.Compose([
GroupScale(int(scale_size)),
GroupCenterCrop(crop_size),
Stack(roll=(args.arch in ['BNInception', 'InceptionV3'])),
ToTorchFormatTensor(div=(args.arch not in ['BNInception', 'InceptionV3'])),
normalize,
]), dense_sample=args.dense_sample),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
# define loss function (criterion) and optimizer
if args.loss_type == 'nll':
criterion = torch.nn.CrossEntropyLoss().cuda()
else:
raise ValueError("Unknown loss type")
for group in policies:
print(('group: {} has {} params, lr_mult: {}, decay_mult: {}'.format(
group['name'], len(group['params']), group['lr_mult'], group['decay_mult'])))
if args.evaluate:
validate(val_loader, model, criterion, 0)
return
log_training = open(os.path.join(args.root_log, args.store_name, 'log.csv'), 'w')
with open(os.path.join(args.root_log, args.store_name, 'args.txt'), 'w') as f:
f.write(str(args))
tf_writer = SummaryWriter(log_dir=os.path.join(args.root_log, args.store_name))
for epoch in range(args.start_epoch, args.epochs):
adjust_learning_rate(optimizer, epoch, args.lr_type, args.lr_steps)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, log_training, tf_writer)
# evaluate on validation set
if (epoch + 1) % args.eval_freq == 0 or epoch == args.epochs - 1:
prec1 = validate(val_loader, model, criterion, epoch, log_training, tf_writer)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
tf_writer.add_scalar('acc/test_top1_best', best_prec1, epoch)
output_best = 'Best Prec@1: %.3f\n' % (best_prec1)
print(output_best)
log_training.write(output_best + '\n')
log_training.flush()
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'best_prec1': best_prec1,
}, is_best)
def train(train_loader, model, criterion, optimizer, epoch, log, tf_writer):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
if args.no_partialbn:
model.module.partialBN(False)
else:
model.module.partialBN(True)
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
target = target.cuda()
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# compute gradient and do SGD step
loss.backward()
if args.clip_gradient is not None:
total_norm = clip_grad_norm_(model.parameters(), args.clip_gradient)
optimizer.step()
optimizer.zero_grad()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
output = ('Epoch: [{0}][{1}/{2}], lr: {lr:.5f}\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5, lr=optimizer.param_groups[-1]['lr'] * 0.1)) # TODO
print(output)
log.write(output + '\n')
log.flush()
tf_writer.add_scalar('loss/train', losses.avg, epoch)
tf_writer.add_scalar('acc/train_top1', top1.avg, epoch)
tf_writer.add_scalar('acc/train_top5', top5.avg, epoch)
tf_writer.add_scalar('lr', optimizer.param_groups[-1]['lr'], epoch)
def validate(val_loader, model, criterion, epoch, log=None, tf_writer=None):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
output = ('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1, top5=top5))
print(output)
if log is not None:
log.write(output + '\n')
log.flush()
output = ('Testing Results: Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f} Loss {loss.avg:.5f}'
.format(top1=top1, top5=top5, loss=losses))
print(output)
if log is not None:
log.write(output + '\n')
log.flush()
if tf_writer is not None:
tf_writer.add_scalar('loss/test', losses.avg, epoch)
tf_writer.add_scalar('acc/test_top1', top1.avg, epoch)
tf_writer.add_scalar('acc/test_top5', top5.avg, epoch)
return top1.avg
def save_checkpoint(state, is_best):
filename = '%s/%s/ckpt.pth.tar' % (args.root_model, args.store_name)
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, filename.replace('pth.tar', 'best.pth.tar'))
def adjust_learning_rate(optimizer, epoch, lr_type, lr_steps):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
if lr_type == 'step':
decay = 0.1 ** (sum(epoch >= np.array(lr_steps)))
lr = args.lr * decay
decay = args.weight_decay
elif lr_type == 'cos':
import math
lr = 0.5 * args.lr * (1 + math.cos(math.pi * epoch / args.epochs))
decay = args.weight_decay
else:
raise NotImplementedError
for param_group in optimizer.param_groups:
param_group['lr'] = lr * param_group['lr_mult']
param_group['weight_decay'] = decay * param_group['decay_mult']
def check_rootfolders():
"""Create log and model folder"""
folders_util = [args.root_log, args.root_model,
os.path.join(args.root_log, args.store_name),
os.path.join(args.root_model, args.store_name)]
for folder in folders_util:
if not os.path.exists(folder):
print('creating folder ' + folder)
os.mkdir(folder)
if __name__ == '__main__':
main()
Reference
-
Lin, J., Gan, C., & Han, S. (2019). Contributors to mit-han-lab/temporal-shift-module. GitHub. Retrieved October 19, 2022, from https://github.com/mit-han-lab/temporal-shift-module/graphs/contributors