SR-GNN
Session-based Recommendation with Graph Neural Networks
一、论文
1、理论
SR-GNN是一种基于会话序列建模的推荐系统。会话序列专门表示一个用户过往一段时间的交互序列。
常用的会话推荐包括循环神经网络和马尔科夫链,但有两个缺点:
- 当一个会话中用户的行为数量十分有限时(就是比较少时)
- 根据以往的工作发现,物品之前的转移模式在会话推荐中是十分重要的特征,但RNN和马尔科夫过程只对相邻的两个物品的单项转移向量进行 建模,而忽略了会话中其他的物品。(意思是RNN那种方式缺乏整体大局观,只构建了单项的转移向量,对信息的表达能力不够强)
序列召回的输入输出,一般来说序列召回输入的是用户的行为序列(用户交互过的item id的列表),需要预测的是用户下一个时刻可能点击的top-k个item。那在实际操作的过程中,我们通常把用户的行为序列抽取成一个用户的表征向量,然后和Item的向量通过一些ANN的方法(ANN的方法分为三大类:基于树的方法、哈希方法、矢量量化方法)来进行快速的检索,从而筛选出和用户表征向量最相似的top-k个Item。
2、核心方法
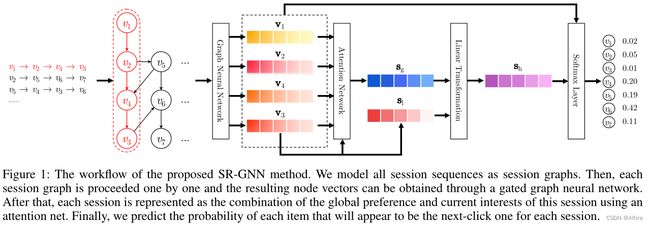
SR-GNN方法的工作流程。
- 将用户的行为序列构造成 Session Graph
- 我们通过GNN来对所得的 Session Graph进行特征提取,得到每一个Item的向量表征
- 在经过GNN提取Session Graph之后,我们需要对所有的Item的向量表征进行融合,以此得到User的向量表征 在得到了用户的向量表征之后,我们就可以按照序列召回的思路来进行模型训练/模型验证了,下面我们来探讨这三个点如何展开
2.1 Session Graph
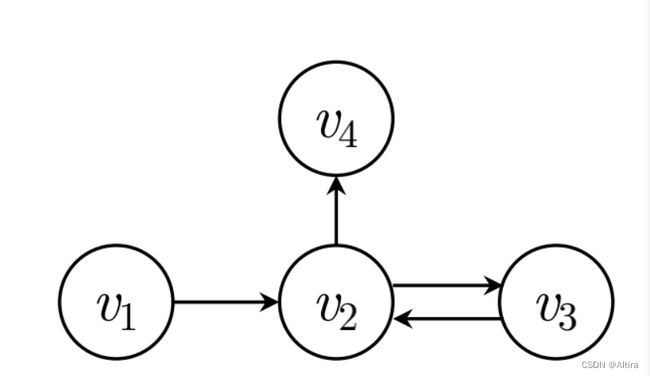
构建的矩阵为:
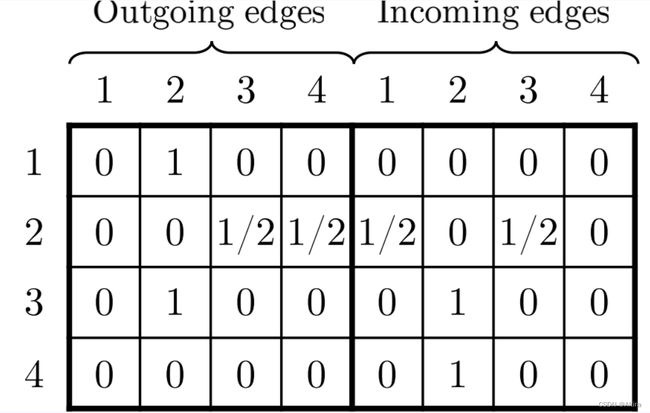
2.2 通过GNN学习Item的向量表征
这里设 v i t v_{i}^{t} vit表示在第t次GNN迭代后的item i的向量表征, A s , i ∈ R 1 × 2 n A_{s,i} \in R^{1 \times 2n} As,i∈R1×2n表示 A s A_{s} As矩阵中的第 i i i行,即代表着第 i i i个item的相关邻居信息。则我们这里通过公式(1)来对其邻居信息进行聚合,这里主要通过矩阵 A s , i A_{s,i} As,i和用户的序列 [ v 1 t − 1 , . . . , v n t − 1 ] T ∈ R n × d [v_{1}^{t-1},...,v_{n}^{t-1}]^{T} \in R^{n \times d} [v1t−1,...,vnt−1]T∈Rn×d的乘法进行聚合的,不过要注意这里的公式写的不太严谨,实际情况下两个 R 1 × 2 n 和 R n × d R^{1 \times 2n}和R^{n \times d} R1×2n和Rn×d的矩阵是无法直接做乘法的,在代码实现中,是将矩阵A分为in和out两个矩阵分别和用户的行为序列进行乘积的
a s , i t = A s , i [ v 1 t − 1 , . . . , v n t − 1 ] T H + b (1) a_{s,i}^{t}=A_{s,i}[v_{1}^{t-1},...,v_{n}^{t-1}]^{T}\textbf{H}+b \tag{1} as,it=As,i[v1t−1,...,vnt−1]TH+b(1)
A*V类似于加权求和
LSTM

GRU

在得到公式(1)中的 a s , i t a_{s,i}^{t} as,it之后,根据公式(2)(3)计算出两个中间变量 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it可以简单的类比LSTM,认为 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it分别是遗忘门和更新门
z s , i t = σ ( W z a s , i t + U z v i t − 1 ) ∈ R d (2) z_{s,i}^{t}=\sigma(W_{z}a_{s,i}^{t}+U_{z}v_{i}^{t-1}) \in R^{d} \tag{2} zs,it=σ(Wzas,it+Uzvit−1)∈Rd(2)
r s , i t = σ ( W r a s , i t + U r v i t − 1 ) ∈ R d (3) r_{s,i}^{t}=\sigma(W_{r}a_{s,i}^{t}+U_{r}v_{i}^{t-1}) \in R^{d} \tag{3} rs,it=σ(Wras,it+Urvit−1)∈Rd(3)
这里需要注意,我们在计算 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it的逻辑是完全一样的,唯一的区别就是用了不同的参数权重而已.
在得到公式(2)(3)的中间变量之后,我们通过公式(4)计算出更新门下一步更新的特征,以及根据公式(5)来得出最终结果
v i t ∼ = t a n h ( W o a s , i t + U o ( r s , i t ⊙ v i t − 1 ) ) ∈ R d (4) {v_{i}^{t}}^{\sim}=tanh(W_{o}a_{s,i}^{t}+U_{o}(r_{s,i}^{t} \odot v_{i}^{t-1})) \in R^{d}\tag{4} vit∼=tanh(Woas,it+Uo(rs,it⊙vit−1))∈Rd(4)
v i t = ( 1 − z s , i t ) ⊙ v i t − 1 + z s , i t ⊙ v i t ∼ ∈ R d (5) v_{i}^{t}=(1-z_{s,i}^{t}) \odot v_{i}^{t-1} + z_{s,i}^{t} \odot {v_{i}^{t}}^{\sim} \in R^{d} \tag{5} vit=(1−zs,it)⊙vit−1+zs,it⊙vit∼∈Rd(5)
这里我们可以看出,公式(4)实际上是计算了在第t次GNN层的时候的Update部分,也就是 v i t ∼ {v_{i}^{t}}^{\sim} vit∼,而在公式(5)中通过遗忘门 z s , i t z_{s,i}^{t} zs,it来控制第t次GNN更新时, v i t − 1 v_{i}^{t-1} vit−1和${v_{i}{t}}{\sim} $所占的比例。这样就完成了GNN部分的item的表征学习。
此处公式(2)…(5)类似于GRU的公式。
2.3 生成User 向量表征(Generating Session Embedding)
此处未看懂
在通过GNN获取了Item的嵌入表征之后,我们的工作就完成一大半了,剩下的就是讲用户序列的多个Item的嵌入表征融合成一个整体的序列的嵌入表征
这里SR-GNN首先利用了Attention机制来获取序列中每一个Item对于序列中最后一个Item v n ( s 1 ) v_{n}(s_1) vn(s1)的attention score,然后将其加权求和,其具体的计算过程如下
a i = q T σ ( W 1 v n + W 2 v i + c ) ∈ R 1 s g = ∑ i = 1 n a i v I ∈ R d (6) a_{i}=\textbf{q}^{T} \sigma(W_{1}v_{n}+W_{2}v_{i}+c) \in R^{1} \tag{6} \\ s_{g}= \sum_{i=1}^{n}a_{i}v_{I}\in R^{d} ai=qTσ(W1vn+W2vi+c)∈R1sg=i=1∑naivI∈Rd(6)
在得到 s g s_g sg之后,我们将 s g s_g sg与序列中的最后一个Item信息相结合,得到最终的序列的嵌入表征
s h = W 3 [ s 1 ; s g ] ∈ R d (7) s_h = W_{3}[ s_1 ;s_g] \in R^{d} \tag{7} sh=W3[s1;sg]∈Rd(7)
二、代码
-
数据结构
-
评价标准:hitrate@50(命中率)、ndcg@50、recall@50(召回)
torch.repeat_interleave(input, repeats, dim=None) → Tensor
重复张量的元素
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat_interleave(2)
tensor([1, 1, 2, 2, 3, 3])
# 传入多维张量,默认`展平`
>>> y = torch.tensor([[1, 2], [3, 4]])
>>> torch.repeat_interleave(y, 2)
tensor([1, 1, 2, 2, 3, 3, 4, 4])
# 指定维度
>>> torch.repeat_interleave(y,3,0)
tensor([[1, 2],
[1, 2],
[1, 2],
[3, 4],
[3, 4],
[3, 4]])
>>> torch.repeat_interleave(y, 3, dim=1)
tensor([[1, 1, 1, 2, 2, 2],
[3, 3, 3, 4, 4, 4]])
# 指定不同元素重复不同次数
>>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0)
tensor([[1, 2],
[3, 4],
[3, 4]])
#重复不同次数
>>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0)
tensor([[1, 2],
[3, 4],
[3, 4]])