近10年数据仓库演进之路,以及数据库学习建议
数据仓库
是面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
从数据角度,数据仓库更适合传统的数据库,离线采集,数据一般为结构化的,每天处理数据量不易超过TB集,数据仓库一般在数十T到几百T以内,数据仓库一般为满足内生的应用,满足内部决策支持分析需求。缺点就是海量数据存储计算存在瓶颈,无法支撑非结构化数据、实时数据计算;硬件设备成本也过高。
数据仓库的架构
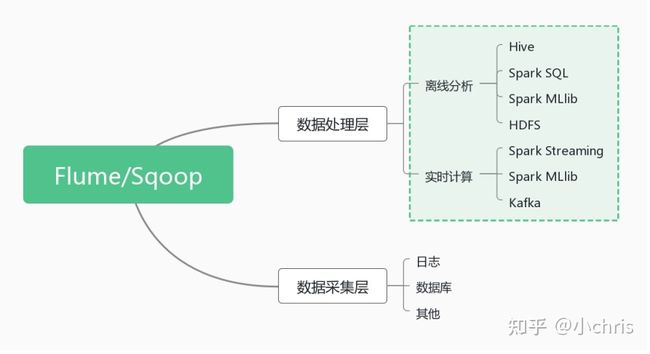
从整体上来看,数据仓库体系架构可分为:数据采集层、数据计算层、数据服务层和数据应用层
数据采集层
数据采集层的任务就是把数据从各种数据源中采集和存储到数据库上,期间有可能会做一些 ETL(即抽取、转换、装载)操作。其中,日志所占份额最大,存储在备份服务器上的业务数据库中,如 Mysql 中的数据。其他数据的话,如 Excel 等需要手工录入的数据。
实时采集不是一条一条采集,而是根据一些限制条件,一般是数据大小限制(如 512KB 写一批)、时间阈值限制(如 30 秒写一批)。采集的数据需要数据采集系统分发给下游,一般选取 Flume、Sqoop 等。
数据处理层
从数据采集系统出来的数据,分发给下游的数据处理平台,一般有 Hive、MapReduce、Spark Streaming、Storm 以及新兴的 Flink 等,阿里巴巴内部使用的是 StreamCompute。
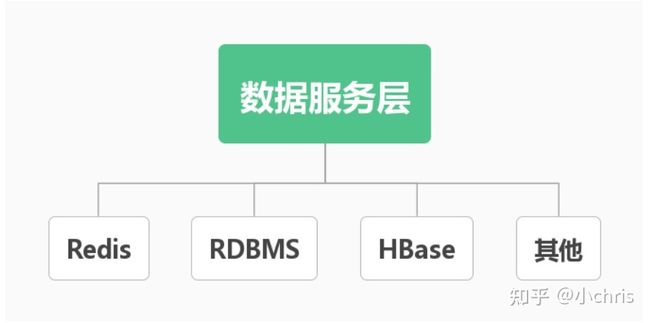
数据服务层
数据服务层,通过接口服务化方式对外提供数据服务,以保证更好的性能和体验。针对不同的需求和数据应用场景,数据服务层的数据源架构在不同的数据库上,如 Mysql、HBase、MongoDB 等。实时的存储且需要支持高并发的话,就选择 HBase。数据服务层可以使应用对底层数据存储透明,将海量数据方便高效地开放给各业务使用。
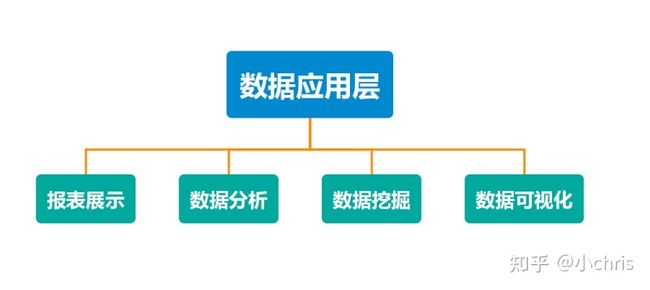
数据应用层
数据已经准备好,需要通过合适的应用提供给用户,让数据最大化地发挥价值。数据应用表现在各个方面,如报表展示、数据分析、数据挖掘、数据可视化等。
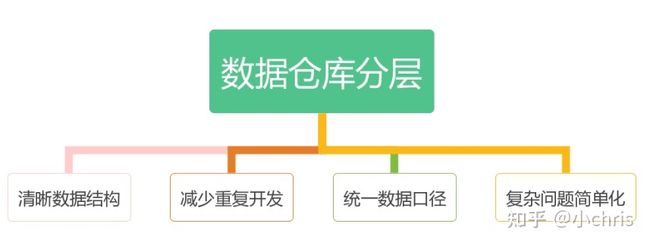
数据仓库分层
随着业务的发展,频繁迭代和跨部门的业务变得越来越多。这就容易导致数据仓库出现如下问题:
1)缺乏统一的业务和技术标准,如:开发规范、指标口径不统一。
2)缺乏统一数据质量监控,如:字段数据不完整和不准确等。
3)业务知识体系散乱,导致数据研发人员开发成本增加。
4)数据架构不合理,数据层之间分工不明显,数据流向混乱。
5)缺失统一维度和指标管理。
演进阶段
2010-2015年,大数据平台阶段
移动互联网的飞速发展带动 Bigdata (大数据)的发展。其中 Hadoop 生态技术开始逐步在国内大范围使用,企业只要基于 Hadoop 分布式的计算框架,使用相对廉价的PC服务器就能搭建起大数据集群。
数据湖的概念也是这个阶段诞生(主要是为降低传统数仓较为复杂的中间建模过程,通过接入业务系统的原始数据,包括结构化、非结构数据,借助hadoop生态强大计算引擎,将数据直接服务于应用)。这个阶段不只是金融、电信这些行业,国内主流互联网企业也纷纷搭建起大数据平台。
大数据应用更为丰富,不仅限于决策分析,基于APP/门户站点的搜索推荐、以及通过A/B Test来对产品进行升级迭代等是这个阶段常规的应用点,用户画像在这个阶段也得到重视,主要应用于企业的营销、运营等场景。
当前阶段
2015-2022 年,数据中台以及云上大数据阶段
通过前10多年不断的技术积累,大数据在方法和组织的变革上也有了新的沉淀,主要体现在几个方面:
1)数据统一化
其核心思想是数据流转的所有环节进行统一化,如从采集到存储到加工等过程,在这些过程中通过建立统一的公共数据模型体系、统一的指标与标签体系,提高数据的标准性、易用性,让数据本身更好地连通,提升使用效率。
2)工具组件化
数据在采集、计算、存储、应用过程中涉及多业务线条,多场景,将这些场景与工具(采集工具、管道工具、计算&调度工具、数据服务工具,数据管理工具、可视化工具等)进行沉淀,研发出通用、高效的组件化工具,避免重复开发,降低研发成本。
3)应用服务化
之前大数据应用的数据调用比较混杂,有些直接访问数仓数据表,有些调用临时接口等。通过数据中台应用服务化建设,提供标准的应用服务,以数据可视化产品、数据API工具等服务,支撑应用的灵活调用。
4)组织清晰化
数据中台团队专注于数据内容&数据平台开发,提供各种基于数据的能力模块,而其他部门人员如业务产品、运营、分析等角色,只需要借助工具/产品有效地使用数据,发挥其价值,无需关注数据加工的过程,做到各尽其职,充分发挥各自专长,同样也能达到降本提效目的。大数据团队内部本身组织和职责也倾于清晰化,比如按照职责分为平台(工具)研发、数据研发、数据产品、数据分析等不同组织。
列式存储NOSQL数据库历史演进
NOSQL的概念博大精深,有键值(Key-Value)数据库、面向文档(Document-Oriented)数据库、列存储(Wide Column Store/Column-Family)数据库、图(Graph-Oriented)数据库等,本章节主要讲述列存储数据库中最流行的HBase及其替代品Lindorm。
HBase是一个基于HDFS的、分布式的、面向列(列族)的非关系型数据库(NOSQL)。HBase巧妙地将大而稀疏的表放在商用的服务器集群上,单表可以有十亿行百万列,而且可以通过线性方式从下到上增加节点来进行横向扩展,读写性能优秀,支持批量导入,无需分库分表,存储计算分离,成本低,弹性好。
Lindorm是新一代面向在线海量数据处理的分布式数据库,适用于任何规模、多种模型的云原生数据库服务,其基于存储计算分离、多模共享融合的云原生架构设计,具备弹性、低成本、稳定可靠、简单易用、开放、生态友好等优势。
总体来说,Lindorm是HBase的升级版本,性能和稳定性等等通通优于HBase,如果需要使用海量数据提供在线服务,可以考虑Lindorm。
学习数据库的建议
其实学习大数据技术的顺序不重要
至少《 数据库》这门课学习顺序不重要,
因为各类数据库互相之间没有一个是另一个的绝对前提,
你在学一个的时候把其他课程知识提供的内容当『抽象』就好了。
但是,怎样能学好?
说简单也简单,多动手实践。
学《数据库》当然要建几个表塞很多数据进去看看性能。
抽象+实践,就是学习数据库永远不变的真理。