EnlightenGAN:Deep Light Enhancement Without Paired Supervision阅读札记
EnlightenGAN:Deep Light Enhancement Without Paired Supervision阅读札记
论文发表于2021年的TIP。
Abstract
本文提出了一个高效的无监督生成对抗网络EnlightenGAN,可以在没有弱光/正常光图像对的情况下进行训练。本文从输入本身提取的信息来规范unpaired训练,而不是使用ground truth数据来监督学习,并对低光图像增强问题采用一系列创新技术,包括全局-局部鉴别器结构、自正则化感知损失融合,以及注意力机制。
贡献:
(1)EnlightenGAN是第一个成功地将unpaired训练引入低光图像增强的工作。这种训练消除了对paired训练数据的依赖,于是可以使用来自不同领域的更多种类的图像进行训练,此外还避免了paired训练数据带来的过拟合问题。
(2)EnlightenGAN通过施加(i) 全局-局部鉴别器结构处理输入图像中空间变化的光照条件;(ii)自正则化的思想,由自特征保持损失和自正则化注意力机制共同实现。
Method
算法框架图
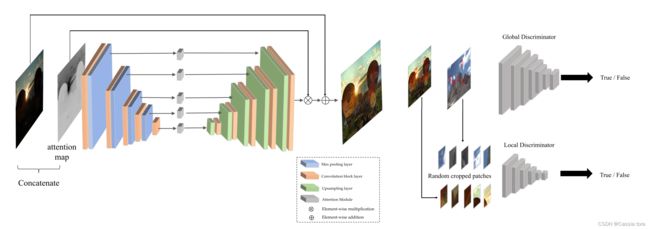
本文方法采用注意力引导的U-Net作为生成器,并使用双鉴别器来引导全局和局部信息,还使用自特征保留损失来指导训练过程并保持纹理和结构。
1、 Global-Local Discriminators
考虑到图像中亮度分布并不均匀,因此所需增强的程度也不相同,为了自适应地增强局部区域,本文提出了一种新颖的全局-局部鉴别器结构,两者都使用PatchGAN进行真假鉴别。即除了图像级全局鉴别器外,还添加了一个局部鉴别器,方法是从输出图像和真实正常光图像中随机裁剪局部块,并学习区分它们是真实的(来自真实图像)还是虚假的(来自输出的增强图像)。
对于全局鉴别器,本文利用相对鉴别器结构[1],它估计真实数据比假数据更真实的概率,并指导生成器合成比真实图像更真实的假图像。相对鉴别器的标准函数是:

C C C:鉴别器网络
x r , x f x_r,x_f xr,xf:从真假分布中采样的真实样本和虚假样本
σ σ σ: s i g m o i d sigmoid sigmoid函数二乘GAN (LSGAN)[2]损失
本文稍微修改了相对鉴别器,用最小二乘GAN (LSGAN) [39]损失替换 s i g m o i d sigmoid sigmoid函数,得到全局判别器 D D D和生成器 G G G的损失函数为:

对于局部鉴别器,本文每次从输出图像和真实图像随机裁剪5个patch,采用原始LSGAN作为对抗损失,如下:

2、 Self Feature Preserving Loss
对于全局鉴别器,针对unpaired的设置,本文通过采用预训练的VGG对图像之间的特征空间距离进行建模的感知损失,来限制输入低光与其增强的正常光输出之间的VGG特征距离。本文称之为自特征保留损失 L S F P L_{SFP} LSFP,定义为:

I L I^L IL:输入的低光图像
G ( I L ) G(I^L) G(IL):生成器的增强输出
Φ ( i , j ) Φ_{(i,j)} Φ(i,j):从在ImageNet上预先训练的VGG-16模型中提取的特征图, i i i表示其第 i i i个最大池化层, j j j表示第 i i i个最大池化层之后的第 j j j个卷积层
W ( i , j ) , H ( i , j ) W_{(i,j)},H_{(i,j)} W(i,j),H(i,j):提取的特征图的维度
⭐默认情况下,本文选择 i = 5 i=5 i=5, j = 1 j=1 j=1。
对于局部鉴别器,对输入和输出图像的裁剪局部patch也通过类似定义的自我特征保留损失 L S F P L o c a l L_{SFP}^{Local} LSFPLocal进行正则化。
此外,本文在VGG特征图之后添加实例归一化层,然后再输入 L S F P L_{SFP} LSFP和 L S F P L o c a l L_{SFP}^{Local} LSFPLocal以稳定训练。训练EnlightenGAN的整体损失函数因此写成:

3、U-Net Generator Guided With Self-Regularized Attention

通过从不同深度层提取多级特征,U-Net保留了丰富的纹理信息,并使用多尺度上下文信息合成了高质量的图像,故本文采用U-Net作为生成器主干。
本文进一步为U-Net生成器提出了一种易于使用的注意力机制。对于弱光图像,总是希望增强暗区域而不是亮区域,从而使得输出的图像不会过度曝光也不会曝光不足。注意力机制步骤如下:
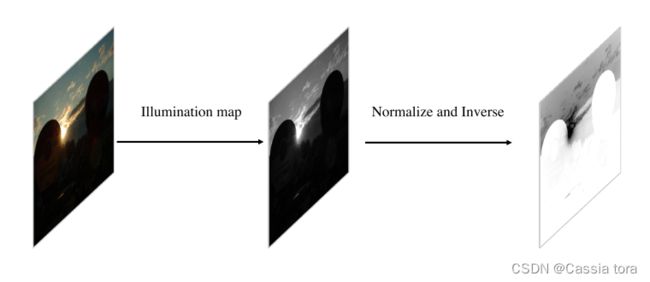
(1)取输入RGB图像的照明通道 I I I,将其归一化为 [ 0 , 1 ] [0,1] [0,1],然后使用 1 − I 1-I 1−I(元素差异)作为自正则化注意力图。
(2)调整注意力图的大小以适应每个特征图,并将其与所有中间特征图以及输出图像相乘。
自正则化注意力图生成过程如下:
本文注意力引导U-Net生成器是用10个Convolution block layer实现的,(Convolution block layer = ConvBlock+ConvBlock,ConvBlock = Conv+LeakyReLu+BatchNorm)
在上采样阶段,将标准的反卷积层替换为一个双线性上采样层和一个卷积层,以减轻棋盘伪影。
Experiment
1、Implementation Details
EnlightenGAN首先从头开始训练100个epoch,学习率为 1 e ( − 4 ) 1e^{(-4)} 1e(−4),然后再进行100个epoch,学习率线性衰减为0。使用Adam优化器,batch size设置为32。由于单路径GAN的轻量级设计不使用循环一致性,训练时间比基于循环的方法短得多。整个训练过程在3块Nvidia 1080Ti GPU 上耗时3小时。
2、Ablation Study
3、Comparison With State-of-the-Arts
1)Visual Quality Comparison
2) No-Referenced Image Quality Assessment
本文采用自然图像质量评估器(NIQE)图像的增强效果(较低的NIQE值表示更好的视觉质量),表I报告了以前工作使用的五个公开可用图像集(MEF、NPE、LIME、VV和DICM)的NIQE结果:

3)Human Subjective Evaluation
本文从测试集中随机选择23张图像,对每张图像通过LIME、RetinexNet、NPE、SRIE和EnlightenGAN进行增强,再选9名受试者对增强图像打分,打分结果如下:

4)Adaptation on Real-World Images
本文从BBD-100k集合中选取950张夜间照片(平均像素强度值小于45)作为弱光训练图像,再加上50张弱光图像进行延时测试。然后比较了在不同正常光图像集上训练的两个EnlightenGAN版本,包括1) EnlightenGAN:未对BBD-100k进行任何适应的预训练模型;2) EnlightenGAN-N:EnlightenGAN的域适应版本,它使用来自BBD-100k数据集的BBD-100k低光图像进行训练,正常光图像与EnlightenGAN相同。下图为各种方法的结果比较:
由于unpaired训练,EnlightenGAN可以很容易地适应EnlightenGAN-N,而不需要新域中的任何监督/配对数据,这极大地促进了其在现实世界中的泛化。
5)Pre-Processing for Improving Classification
本文选择ExDark数据集的2563张测试集图像,将预训练的EnlightenGAN作为预处理步骤,然后通过另一个ImageNet预训练的ResNet-50分类器。在低光测试集中,使用EnlightenGAN作为预处理将分类准确率从 22.02%(top-1)和39.46%(top-5)提高到23.94%(top-1)和40.92%(top-5)增强后。这提供了一个侧面证据,即EnlightenGAN除了产生视觉上令人愉悦的结果外,还保留了语义细节。
References
[1] A. Jolicoeur-Martineau, “The relativistic discriminator: A key element missing from standard GAN,” 2018, arXiv:1807.00734. [Online]. Available: http://arxiv.org/abs/1807.00734.
[2]X. Mao, Q. Li, H.Xie, R.Y. K. Lau,Z.Wang, and S.P.Smolley, “Least squares generative adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2813–2821.