百面机器学习 之 优化算法+标准化+正则化+损失函数
先来聊聊损失函数,然后是优化算法,接着额是正则化和标准化
1. 背景
优化算法做的事就是在 模型表征空间中找到模型评估指标最好的模型。这里就引出了什么是模型的表征空间,以及什么是评估指标了。只有正确地应用表征空间以及评估指标,才可以更好地优化模型
譬如SVM的模型表征空间就是线性分类模型,然后评估指标就是最大间隔
逻辑回归的模型表征空间就是线性分类模型,然后评估指标就是交叉熵
我自己理解模型表征空间就是表明这个模型要处理什么问题,评估指标就是比较出真实值和模型估计值之间的差异。
还有一个很重要的感觉就是我感觉自己对于激活函数,损失函数,优化器之间是没有打通联系的!这一篇还会全部重新讲一次。所以篇幅可能有点长。
2. 有哪些损失函数以及他们的特点
为了刻画模型输出与样本标签的匹配程度,定义损失函数 ![]()
我们先看回归的损失函数
2.1 回归有关的损失函数
2.1.1 均方损失函数Mean Squared Error Loss
MSE的数学形式是这样子的: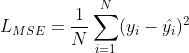
MSE的图形是这样子的:
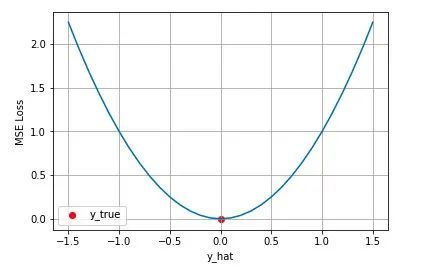
MSE为什么长这样,其实它是基于一个假设推出来的,也就是假设预测值和真实值之间的误差(残差)服从标准的正态分布(方差=0,均值=1)。然后我们把这个误差用正态分布CDF(概率密度函数)来推导出来:
然后我们假设每个样本之间的相互独立的,上面的式子是给定一个样本,现在给定所有x模型输出所有的真实值y的概率,就是残差,也就是所有样本对应的正态分布概率密度函数的乘积:
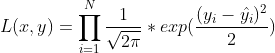
然后我们求最大似然都是加上对数和负号,于是就有下面的变形:

然后看前面是一个常数,后面才是可以动手的地方,于是最大化这个![]() 就等同于最小化
就等同于最小化 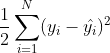 ,这个表达式,就是MSE的表达式了。
,这个表达式,就是MSE的表达式了。
所以咱们就是在假设残差(误差)服从高斯分布的情况下推出了MSE出来,所以当我们知道一个场景的误差可能符合这个假设,那这个损失函数就很好用了,这也是推出了为什么MSE不适用于分类的原因了。
2.1.2 平均绝对误差损失函数 Mean Absolute Error Loss
同理呀,就像MSE一样,我们一样可以从某个假设去推出MAE的表达式出来:
MAE的表达式: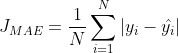
MAE的图形:
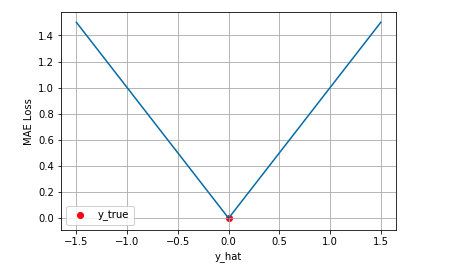
我们假设残差是服从拉普拉斯分布的(位置参数=0.尺度参数=1)
拉普拉斯的概率密度函数是:
![]()
于是给定一个样本,模型输出真实值y的概率:
![]()
同MSE,这次就变成了负对数似然了,然后也是用累乘积的方式得到:
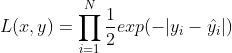

最大化这个似然咱们就要最小化最右项: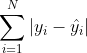
这个表达式不也是MAE的表达式嘛,所以咱们也可以通过损失的分布来推导出MAE的公式来,同理,当残差(损失)如果很符合这个分布,那么效果也会很不错。
下面就是MAE和MSE的对比了,重点
1. MSE比MAE对离群值会更加敏感
我们光从表达式都可以看出来,一个是做平方,一个是做差,离群值通常和真实值的差都比较大,所以平方后的数值会更大,于是就对离群值更加敏感了。所以MAE对异常点,离群值的鲁棒性更强点。
2. MSE比MAE收敛得更快
这也是从表达式可以观察出来,我们分别对两个式子对y求导,MSE得到的是 ,但是MAE得到的是
,但是MAE得到的是 ,MSE的前进的步伐通常都会比MAE大,所以他可以更快地找到全局最优的地方,下降得更快。
,MSE的前进的步伐通常都会比MAE大,所以他可以更快地找到全局最优的地方,下降得更快。
3. MAE在极值点处不可导
即使很小的损失值也会产生很大的误差(滑到另外一边了),不利于模型参数的学习。为了解决这个问题,需要在解决极值点的过程中动态减小学习率,但这会降低模型的收敛速度。动态的学习率表达式:
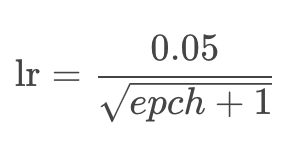
2.1.3 Huber损失函数(Smooth Mean Absolute Error Loss )
因为MSE的收敛更快,但是对异常值敏感,MAE对异常值不那么敏感,但是在x=0处不可倒(从上面MAE的样子图可以看出,x=0处不光滑),所以咱们就引出一个Huber损失来集合MAE和MSE两个的优点。
Huber损失的表达式: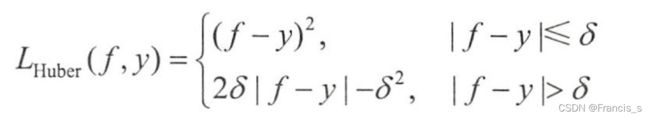
Huber长这个样子:
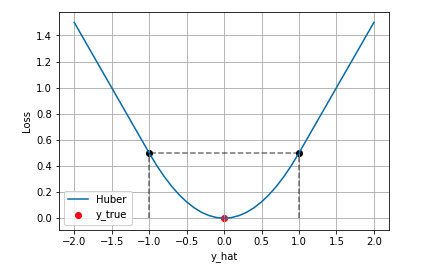
可以看出呀,Huber就是取了下段的MSE,取了上段的MAE,然后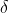 就是这个损失函数的一个超参了,可以自己控制,用来控制连接两段函数的
就是这个损失函数的一个超参了,可以自己控制,用来控制连接两段函数的
Huber结合了 MSE 和 MAE 损失,在误差接近 0 时使用 MSE,使损失函数可导并且梯度更加稳定;在误差较大时使用 MAE 可以降低 outlier 的影响,使训练对 outlier 更加健壮。
缺点是需要额外地设置一个 超参数
2.2 分类的损失函数
下面开始讲分类有关的损失函数,其中里面就有交叉熵 Cross Entropy
这个鬼东西一只困扰了我非常久非常久,以至于我到现在一看到他就恐惧...说不上原因,就是因为这个交叉熵导致我连不起来知识点的.....ORZ
2.2.1 0-1损失函数
0-1损失函数的表达式:![]()
当这个指示函数![]() 的下标为真,就取值为1,某则就取0。该损失函数就非常耿直,要么是0,要么是1,不含糊。大伯事故由于它不是凸函数,而且也不是光滑的,所以算法就很难直接进行优化
的下标为真,就取值为1,某则就取0。该损失函数就非常耿直,要么是0,要么是1,不含糊。大伯事故由于它不是凸函数,而且也不是光滑的,所以算法就很难直接进行优化
2.2.2 合页(Hinge)损失函数
Hinge就是用来解决0-1损失函数的问题的,
Hinge的表达式:![]()
Hinge的样子:

Hinge表示如果分类正确,那么损失就是0,如果分类错误,那损失就是![]() .
.
当f(x)*y >= 1的时候,该函数不对其做任何惩罚。所以Hinge在fy=1的时候是不可导的,因为不是光滑
2.2.3 交叉熵
大哥来了,小的让路
二分类(逻辑回归):
之前就在逻辑回归里面写过,二分类是怎么推出他的损失函数的,这里再说一次,加深印象但就跳过了一开始那个将两个表达式合成一个的过程了:
多样本下独立,所以我们可以直接累乘积:![]()
这一步就其实蕴含很多信息啦,等式的右边就是因为独立,所以咱们连乘起来代表预测某一类的概率(其实类别的概率就是一个概率分布了:概率分布是指用于表述随机变量取值的概率规律。事件的概率表示了一次试验中某一个结果发生的可能性大小。在二分类这里就是分到a类的概率是x,分到b类的概率是1-x,这就是一个概率分布)也就是等式的左边,在模型参数 下,
下, 预测为 的概率。
预测为 的概率。
其实这就是一个似然函数了,我们把似然理解为概率。这里引出对数似然损失,它是对预测概率的似然估计,其最小化的本质是利用样本中的已知分布,求解导致这种分布的最佳模型参数,使这种分布出现概率最大。它衡量的是预测概率分布和真实概率分布的差异性,取值越小越好。
对数似然的标准形式是:![]()
这里的 就是
就是 ![]() 了。所以我们对其做负数和log变换,最后就是这个样子了:
了。所以我们对其做负数和log变换,最后就是这个样子了:
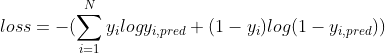
那这里哪里用到了交叉熵呀???哈哈哈我一开始就非常好奇,一只联系不上就是因为这个:
现在我们给定样本 X,Y的真实概率分布为[y, 1-y],预测概率分布为![]() ,交叉熵的标准形式:
,交叉熵的标准形式:
![]()
因为交叉熵是衡量分布的差异的期望呀,然后它要对每一个样本的信息熵都加起来,才能去衡量差异呀。下面公式我们先看单个样本:
![]()
然后多个样本:
知道了吗!这就是为什么对数似然损失函数在二分类时可以化简为交叉熵损失函数。这就是把交叉熵和二分类给联系起来了。上面 我们说了交叉熵就是用来衡量分布的差异,所以我们需要将这个差异降到最小,所以要最小化loss。
多分类:
其实就是二分类的拓展开来了,怎么说呢?上面的二分类是最后是通过一个sigmod激活函数来将结果映射到[0,1]的区间上了,所以求得一个概率,另外一个就用1-它就好了。到了多分类,我们就要把每个类别的概率给计算出来了,这里就用到了softmax激活函数了。它会将结果映射到也是0和1之间,然后概率和是1,用我之前一篇文章来说就是这样子,假如有四个类别
这是softmax的输出:[0.1,0.5,0.2,0.2]
然后咱们会把真实结果给onehot一下:[0,0,1,0]
这里的两个向量其实就是一个概率分布了(概率分布是指用于表述随机变量取值的概率规律。大白话就是事件的发生概率表示了一次试验中某一个结果发生的可能性大小)
然后继续和二分类一样,二分类的所有结果的表示是这样![]()
咱们多分类就变成这样:
然后变成多样本(变成似然函数,所以加对数和负号):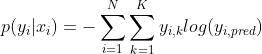
然后由于咱们 ![]() 是一个onehot变量,所以其实就是目标那一类会是1,其余都是0(累加那么多个K就是有一个是真实值,其余都是0)
是一个onehot变量,所以其实就是目标那一类会是1,其余都是0(累加那么多个K就是有一个是真实值,其余都是0)
所以咱们可以写成另外一个形式: 这里的k就是直接拿那个类的y,以及对应类的模型预测输出来做处理了
这里的k就是直接拿那个类的y,以及对应类的模型预测输出来做处理了
2.2.4 为什么分类中不用MSE去做loss
之前我们也说了,MSE是假设损失满足高斯分布的,MAE是满足拉普拉斯分布的,而我们这分类的损失,明显就是不服从这些分布的呀,所以用了效果也非常不好。
2.2.5 为什么偏需要用交叉熵来做分类呢
因为分类的loss是要比较具体的概率分布,所以我们就要用交叉熵来做了,下面来证明:
继续用上面上面提到的两个分布:
这是softmax的输出:[0.1,0.5,0.2,0.2]
然后咱们会把真实结果给onehot一下:[0,0,1,0]
现在我们手里就用两个分布了,那我们怎么衡量他们之间的损失呢?其实还是用到了信息论的KL散度去解释:
KL散度的定义:对于同一个随机变量X有两个单独的概率分布P(x)和Q(x)(就是咱们上面提到的softmax输出和onehot变量两个概率分布)我们可以使用KL散来衡量这两个分布的差异。
KL散度的value越小,代表两个概率分布越相似,这个在EM和EM到VAE的文章里面也提到。
![]()
将这个式子摊开:
![]()
第一项是信息熵,也就是模型的真实分布,咱们是改不了的
第二项就是交叉熵了
所以我们需要让整个KL散度越来越大,于是就需要交叉熵尽可能地最小,而这第二项的表达形式不就是单个样本下的表达形式吗?
换到多样本: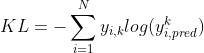 ,这里的k也是像上面推到一样,直接把对K个类别求和给去掉,直接换成对应的第k类了。
,这里的k也是像上面推到一样,直接把对K个类别求和给去掉,直接换成对应的第k类了。
所以通过最小化交叉熵的角度推导出来的结果和使用最大化似然得到的结果是一致的
3. 凸优化
我们为什么需要找到凸函数?
因为凸函数局部最优等于全局最优,而找局部最优的方法就有很多啦,所以大家都喜欢凸函数(这就是凸函数这么重要的原因了)
下一步就是了解什么是凸函数?
函数L是凸函数当且仅当对定义域中的任意两点x,y和任意实数![]() ,都会有
,都会有
![]()

换成网上一般的解释就是:这个函数就是在说在函数的x xx轴上任取两个点 x和y,他们之间连线上的任何一点的函数值都小于或者等于f(x)和f(y)两点连线之后线上的某一点的值。
凸优化问题:SVM,线性回归等线性模型
非凸优化问题:PCA里的矩阵分解,DNN
书上还提到了一个知识点就是:优化算法的大纲,这里粗略说一下关于无约束优化问题的优化方法有哪些?
优化算法其实可以分为直接法和迭代法两大类:
其中直接法就是咱们考研那样,直接通过求导求得这个函数的一阶导等于0的点,这个点就是全局最优的点了,也就是我们要找的点,但是他要满足两个条件,第一个肯定就是这个函数是一个凸函数呀,不保证凸函数咱们也不保证能找到一阶导等于0的点呀,第二个条件就是这个一阶导的公式呀必须得有闭式解。同时满足这两个条件,才可以用直接法去用一阶导做优化
正式因为直接发的限制条件很多,所以我们才换成用迭代法去做优化:
迭代法的本质其实就是一个迭代地修正对最优解的估计。迭代法又区分为一阶法和二阶法
设当前对最优解的估计值为![]() ,希望求解优化问题:
,希望求解优化问题:![]()

一阶法就是梯度下降法,他是由优化函数的一阶泰勒展开演变而来的
下面来看二阶法:

二阶法就是更加精准地靠近了优化函数,所以迭代速度是比一阶法快的。但是在高维的情况下,海森矩阵的计算复杂度非常大,而且当目标函数是非凸函数的时候,二阶法还可能收敛到鞍点去了。

鞍点和极值点都是一阶导等于0
4. 真的优化算法要来了
前面说了一大堆,都是在铺垫,我感觉面试问的几率也不多呀
4.1 梯度下降
当这个目标函数是一个无约束的凸函数时,就可以用梯度下降法来求最优了
根据导数的定义,目标函数 F(x) 的导函数就是目标函数在X上的变化率,那么在多元情况下,目标函数F(X,Y,Z)在某一点梯度 是一个由各个分量的偏导数构成的向量,![]() ,其中负梯度就是这个目标函数减小最快的方向。
,其中负梯度就是这个目标函数减小最快的方向。
上面这段话提到了凸函数,导数,以及负梯度就是这个目标函数的减小最快的方向。
凸函数已经在上面解释过了,下面就来说导数,导数其实在大学里面就已经学过了,在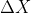 趋近于0的时候极限仍然存在:
趋近于0的时候极限仍然存在:
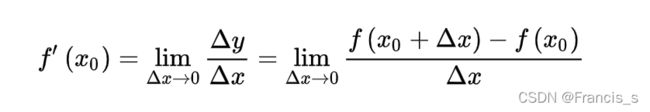
导数其实就是这个点的变化率嘛,可以理解为一个标量(这是在一个一元函数上的表达)
然后梯度就是一个向量, 每个元素就是函数f对每个自变量的偏导数。
所以可以用沿梯度方向的方向导数来描述是函数最大变化率,即梯度方向是函数变化率最大的方向,在梯度定义的时候就已经赋予了它这个特性。但是, 为什么会有这样的一个特性呢?
然后就是解决为什么负梯度方向是下降得最快的原因了
网上的解释非常多,都是用一阶泰勒展开来解释的,这和之前的笔记“一阶法对应是梯度下降”,“二阶法对应牛顿法”的说法是对应上的。具体参考博主:局部下降最快的方向是梯度的负方向
核心就是局部下降的目的是希望每次θ更新,都能让函数值变小,从而让后面两个矢量相乘小于零,而两个矢量相乘小于零,就是要他们的夹角是大于90度的,我们都是知道cos的取值是-1到1,现在我们想求下降得最快,那干脆让两个矢量的方向是相反得了,也就是减得更多,最终函数值就会下降得更快。
4.2 随机梯度下降 Stochastic Gradient Descent, SGD
提出的原因是因为我们如果用全量的样本去更新,计算量非常大,要遍历所有样本,于是咱们改进一下,使用一个样本进行参数的更新(如果有十个样本,那就更新10次参数)
但是因为只用单一样本去做更新,所以梯度的方差会比较大,也就是不怎么稳定,下降方向不集中
SGD是一个挺常用的优化算法,但是也有失效的时候
首先就是上面提到的,梯度的方差会比较大,换句话话说,如果运气好,那么它还是会找到最终的局部最优点的,但就是过程非常曲折,下降的方向非常不明确,走了很多弯路
随机梯度就是放弃了对梯度准确性的追求来追求计算速度高效,也造成了目标函数收敛得不稳定的结果
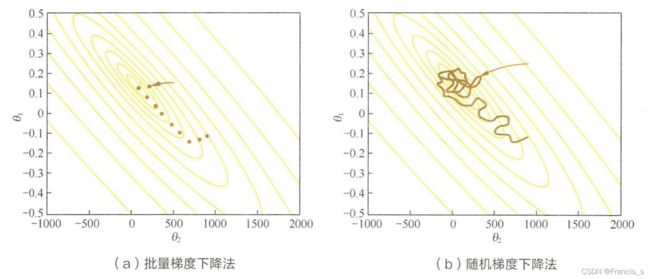
除此之外,让SGD最怕 的其实还是山谷 和 鞍点 这两种地形:
山谷最佳方向就是沿着山道向下,但是因为SGD的方向不稳就来回碰撞
鞍点中,SGD会进入一个局部的平坦之地(此时离最低点还很远)在这里因为坡度非常平坦,SGD感受不出来梯度的变化,所以就一直停留在鞍点不出来了。
4.3 小批量梯度下降法 Mini-Batch Gradient Descent,MBGD
提出这种方法是为了解决用全量数据跑又太慢但效果好,随机梯度下降方向不稳定但速度快
的问题,就是在更新每一参数时都使用一部分样本来进行更新,也就是批处理方程(全量)中的n的值大于1小于所有样本的数量。
但是要注意三个问题:
1. 通常咱们这个n取值都是2的幂次,这样能充分利用矩阵元算操作
2. 然后这n个数据在做训练数据之前,都会先random处理一下,然后再按顺序去挑选n个出来,直到遍历完所有数据
3. MBGD 涉及到M的选择,所以不能抱着个比较好的收敛性,如果学习率太小,收敛速度会很慢,如果太大,损失函数就会在极小值出不停的震荡甚至偏离,所以通常用衰减学习率的方案: 一开始采用较大学习率,当误差曲线进入平台期后,减小学习率做更精细的调整。 最优的学习速率也通常需要调参。
这样就可以兼容批处理(全量)更新的方向准确,以及随机梯度下降的速度快的优点了。实际中也大多数用这个
下面的改进方法主要有两个方向,第一个是惯性保持方向,第二个是环境感知方向
4.4 动量方法(Momentum)(惯性保持方向)
这个方法的提出是用来改进SGD的山谷和鞍点问题的
直接上公式:
![]()
![]()
首先第一条式子, *
* 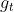 就是学习率乘当前的梯度,然后左边
就是学习率乘当前的梯度,然后左边 就是一个衰减因子,
就是一个衰减因子,![]() 就是上一次步伐。
就是上一次步伐。
第二条式子就是更新当前的梯度方向
这里面就体现了再对上一次步伐信息的重利用了,当前梯度好比当前时刻的受力产生的加速度,前一次步伐好比前一时刻的速度,当前步伐就是当前时刻的速度。于是当前速度就等于前一时刻的速度和当前加速度共同作用的记过,因此 ![]() 直接依赖于
直接依赖于![]() 以及,而不仅仅是,而衰减因子就相当于一个阻力的存在。
以及,而不仅仅是,而衰减因子就相当于一个阻力的存在。
这个衰减因子一般都设置比较小,0.9,0.5类似的样子,让旧的步伐慢慢随着时间的变化而减少对现在步伐的影响。

4.5 Nesterov Accelerated Gradient (NAG)(惯性保持方向)
这是⼀个针对动量算法的改进措施。动量算法是把历史的梯度和当前的梯度进进行合并,来计算下降的⽅向。
这个NAG则是让迭代点先按照历史梯度(就是上一个梯度的方向)走⼀步,然后再合并
公式:
![]()
![]()

也就是先让原始点,走一下历史梯度,就是从B走到C(根据A点到B点的方向),然后在C点上走B的梯度方向,然后两者再相加,变成实际B点梯度方向,也就是到达了D点(实际下降点)PS:图引用这里
4.6 自适应梯度 Adapted Gradient(环境感知)
先说一下环境感知是怎么一回事,就是随机梯度下降在参数空间中,根据不同参数的一些经验性判断,自适应地确定参数的学习速率嘛,不同参数的更新步幅是不同的。拿书上的例子来说明

直接给出公式:
![]()
![]()
r就是一个累积平方梯度,学习率从以前的 变成现在的
变成现在的 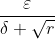 ,然后 是一个小常数,为了数值稳定大约设置为 10^(-7)。学习率其实差不多是由步长所决定的,对于更新不频繁的参数,单次步长会更大。对于更新频繁的参数,步长较小,使得学习到的参数更加稳定。整体一开始,r都是很小的,到了后面r积累起来了,学习率就开始下降了变慢了,这也是自适应的来源
,然后 是一个小常数,为了数值稳定大约设置为 10^(-7)。学习率其实差不多是由步长所决定的,对于更新不频繁的参数,单次步长会更大。对于更新频繁的参数,步长较小,使得学习到的参数更加稳定。整体一开始,r都是很小的,到了后面r积累起来了,学习率就开始下降了变慢了,这也是自适应的来源
4.7 RmSprop
这个鬼东西是为了解决AdaGrad学习率过度衰减的问题呀,AdaGrad 根据平方梯度的整个历史来收缩学习率,可能使得学习率在达到局部最小值之前就变得太小而难以继续训练。
RmSpro不像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少(也有一个说法是用指数衰减的移动平均以丢弃遥远的过去历史)
先上公式:
![]()
![]()
其中,p就是这个算法引入的衰减系数
在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
4.8 Adam
Adam算法的引入是为了综合Momentum和RMSprop两个算法的,按照书上的解释:
1. Adam记录梯度的一阶矩,即过往梯度与当前梯度的平均,体现了保持惯性—历史梯度的指数衰减平均
2. Adam记录梯度的二阶矩, 即过往梯度平方与当前梯度平方的平均,RMSProp的方式,体现了环境感知的能力
下面直接看公式:
![]()
![]()
![]()
![]()
![]()
![]()
我们先看r和s的更新公式是什么意思,r采用的是一阶矩,体现了保持惯性,而s就是采用了二阶矩,体现环境感知。那这两个公式有什么含义呢?
其实它们两都是指数加权(滑动)平均:指数加权平均在时间序列中经常用于求取平均值的一个方法,我们要求取当前时刻的平均值,距离当前时刻越近的那些参数值,它的参考性越大,所占的权重就越大,这个权重是随时间间隔的增大呈指数下降,所以叫做指数滑动平均。
那具体他是怎么控制离我当前时间(距离)近的就权重变大,远的就权重变小呢?其实就是通过那个p1和p2来控制的。这里控制着记忆周期的长短(要计算过去多少天的数据)变换一下这个天数就是 ![]() ,通常咱们这个p都是设置成0.9的,也就是计算过去10天的数据。
,通常咱们这个p都是设置成0.9的,也就是计算过去10天的数据。
然后看下面两个公式:![]() 和
和 ![]() ,这两个公式其实是在修正咱们r和s从0开始往后计算头几次的误差,具体怎么产生误差就手动计算一下就好了,这里咱们就直接看公式为什么只计算前面几次?我们的p通常都是设置小于1的,随着时间的推移,迭代次数的叠加,分母从0慢慢转移到1,也就是后面那项会变成0,所以到了后期,
,这两个公式其实是在修正咱们r和s从0开始往后计算头几次的误差,具体怎么产生误差就手动计算一下就好了,这里咱们就直接看公式为什么只计算前面几次?我们的p通常都是设置小于1的,随着时间的推移,迭代次数的叠加,分母从0慢慢转移到1,也就是后面那项会变成0,所以到了后期,![]() 和
和![]() 都是r和s本身了。
都是r和s本身了。
然后最后一个公式的![]() 是一个常数,用来保持Adam稳定。常常设置为10^-7。
是一个常数,用来保持Adam稳定。常常设置为10^-7。
用知乎大佬的一句话总结这一节:模型的梯度是一个随机变量,一阶矩表示梯度均值,二阶矩表示其方差,一阶矩来控制模型更新的方向,二阶矩控制步长(学习率)。用moveing average来对一阶矩和二阶矩进行估计。bias correct是为了缓解初始一阶矩和二阶矩初始为0带来的moving average的影响。
5. 正则化和标准化
5.1 正则化之L1,L2
为啥要引入正则化,就是因为减少模型参数大小或者参数的数量,来达到防止过拟合的目的,正则化其实就是在原来的目标函数的基础上又加了一项关于模型参数w非负项。
具体的公式就是:
![]()
其中:
![]()
![]()
L1和L2的思想就是我在整体的loss里面加入了有关w的函数,然后咱们是想整体的loss更低,所以模型为了达到最终目标(整体loss更低)会降低w的大小(虽然第一项会跟着提高,但这就是让模型自找到平衡点了)从而达到防止过拟合的目的了。
这里面有两个问题,L1为什么会导致权重稀疏,L2为什么被称为权重衰退?一个个来解决
第一个,L1为什么会导致权重稀疏?在网上看了很多资料,也看了百面书上的解释,但是从优化的角度我是真的看不懂0 0,所以下面就决定从求导的角度去解释了。
为什么选择求导?因为咱们是想求loss的最小值,那按照普通函数的求最值/极值的方法,就是对整体求导,然后令导数等于零,就可以得出让loss取最小值的参数了。
我们直接对比一下L2和L1,为啥L2就不会导致稀疏,首先我们对两个loss求导:
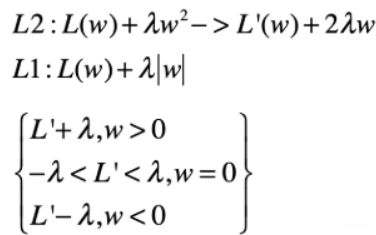
引入L2正则化后,求导后的样子是![]() ,如果这时候想L2产生稀疏,也就是w等于0,然后再综合上我们想这个等式等于0,我们会得出
,如果这时候想L2产生稀疏,也就是w等于0,然后再综合上我们想这个等式等于0,我们会得出![]() 也要等于零才行,就是必须让loss的导数刚好等于0才会发生稀疏的情况,而loss的导数刚好等于0也是比较有难度的,发生概率比较低
也要等于零才行,就是必须让loss的导数刚好等于0才会发生稀疏的情况,而loss的导数刚好等于0也是比较有难度的,发生概率比较低
我们再看对L1求导,因为w是一个绝对值,所以我们需要分类讨论,也就是上面公式的当w大于0,小于0,等于0.
我们先看大于0和小于0的情况,求导后分别是![]() 和
和 ![]() ,要想这两个情况下发生权稀疏,不可能嘛,已经说了w是大于0和小于0了...况且我们的目的是让整个loss达到最小,也就是让
,要想这两个情况下发生权稀疏,不可能嘛,已经说了w是大于0和小于0了...况且我们的目的是让整个loss达到最小,也就是让![]() 等于
等于![]() ,让一个网络的结果等于一个值,还是非常有难度的
,让一个网络的结果等于一个值,还是非常有难度的
所以继续看w=0的情况,其实这时候,整个函数是不可导的,但是不妨碍我们分析。我们要想让整个损失函数取到最小值,所以必须得保证原损失函数的导数![]() 是在
是在![]() 之间的,为啥呢?
之间的,为啥呢?
重点来了,当![]() ,
,![]() ,当
,当![]() ,
,![]() ,也就是在w=0的时候,函数可以取到极小值,这时候对于原损失函数导数的要求是落在一个区间里面,这个是非常有可能的。 所以才容易稀疏解。
,也就是在w=0的时候,函数可以取到极小值,这时候对于原损失函数导数的要求是落在一个区间里面,这个是非常有可能的。 所以才容易稀疏解。
第二个问题就是,L2为什么被称为权重衰退?
原始的权重更新公式是这个样子的:![]()
现在引入了L2正则项后:
然后同样对w求导,变成:
![]()
咱们的lambda取值都是0-1的,也就是每一次迭代,w本身都会发生一个衰减,注意是本身啊,然后再减去梯度更新的valule。这就是为什么L2被称为权重衰退的原因了。
5.2 Dropout
就是做随机失活的操作,给一个概率,然后让这一层的有百分之多少是失活的,也就是去那种话为0,注意噢,是这一层而已(写过pytorch的应该都知道)前面加了dropout,只是前面drop而已。和后面没有半毛钱关系。
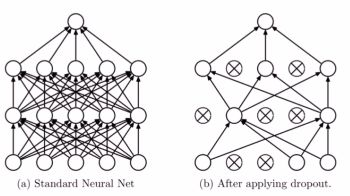
然后我们用一个例子来加深理解:
这个类似于我们期末考试的时候有没有,老师总是会给我们画出一个重点,但是由于我们不知道这些重点哪些会真的出现在试卷上,所以就得把精力分的均匀一些,都得看看, 这样保险一些,也能泛化一点,至少只要是这些类型的题都会做。 而如果我们不把精力分的均匀一些,只关注某种题型, 那么准糊一波。
然后有一个要注意的点是训练的时候 ,咱们是开启了Dropout,但是测试的时候就不用Drop了,也就是测试的时候是用所有的神经元,所以会出现一个尺度不匹配的问题,解决办法就是测试的时候权重✖️(1-drop_prob),就解决了。
5.3 标准化之BatchNormalization
论文的作者这里提出一个概念:Internal Covariate Shift,怎么解释呢?
随着训练的进行,网络中的参数也随着梯度下降在不停更新。
一方面,当底层网络中参数发生微弱变化时,由于每一层中的线性变换与非线性激活映射,这些微弱变化随着网络层数的加深而被放大;
另一方面,参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难。
所以他定义了:由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
这个ICS鬼东西会带来什么问题呢?其实开头已经说了点:
1. 高层的网络在接收到下面穿上来值后,要适应输入数据分布的变化,导致网络学习速度大大降低,因为其那面的网络每一层的线性与非线性计算结果的分布都会产生变化。
2. 网络训练过程容易陷入梯度饱和区,从而减少网络的收敛速度。也就是当我们用一些饱和的激活函数时候,我们会发现有时候会出现梯度消失的情况,参数的更新速度大大降低,这是因为映射到了激活函数的饱和区域,导致变化非常小。
所以对应的解决办法就是白化(Whitening)处理,机器学习里面常用的一种规范化数据分布的方法,主要是PCA白化与ZCA白化。
但是会有下面两个问题出现:
- 白化过程计算成本太高
- 白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。底层网络学习到的参数信息会被白化操作丢失掉。
于是作者就给出一个解决办法,为了统一分布,我们如果对整个batch一起做处理,那计算量会非常大,于是作者觉得单独对每个特征进行normalizaiton就可以了,让每个特征都有均值为0,方差为1的分布就OK。这样既可以让每一个特征都在同一个分布上计算,也能减少计算量。这个是应对第一个问题。
第二个问题的解决办法:就再加个线性变换操作恢复这批数据原来的表达能力。先看例子:引用知乎大佬的图和文案
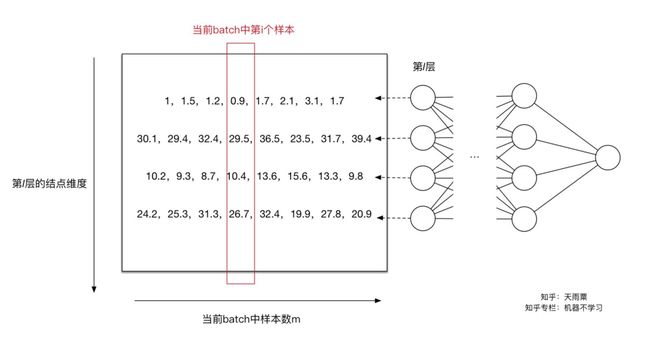
这个是一批样本哈,每一列代表一个样本,每一行代表样本的一个属性,所以这一个样本有4个属性。这有8个样本。
然后我们根据上面说到的第一个问题的解决办法,就是单独对每个特征进行normalizaiton。于是就有了下面这个图,下面的每一行都做了归一化处理了

通过上面的变换,我们解决了第一个问题,即用更加简化的方式来对数据进行规范化,使得第L层的输入每个特征的分布均值为0,方差为1。
训练和测试时候的区别:训练的过程中,可以用指数滑动平均法(就是上面Adam里面提到的)来更新和保存均值和方差,训练结束的时候,当前BN层中的均值和方差也就固定了,然后就可以应用于测试的时候了。
然后解决第二个问题:作者在这里引入了两个需要网络自己学习的参数 和
和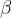 ,这两个参数的引入是为了恢复数据本身的表达能力。具体就是做一个线性变换:就是乘上这一层的权重和加上bias:(Z就是做完normalization后的样子,就是上图)
,这两个参数的引入是为了恢复数据本身的表达能力。具体就是做一个线性变换:就是乘上这一层的权重和加上bias:(Z就是做完normalization后的样子,就是上图)
![]()
当![]() 的时候,就是实现了把normalization消掉,就是恢复原来数据分布的动作了。也就是变不变回以前那样是根据模型自己决定,自己评估的。
的时候,就是实现了把normalization消掉,就是恢复原来数据分布的动作了。也就是变不变回以前那样是根据模型自己决定,自己评估的。
通过这一步,我们就在一定程度上保证了输入数据的表达能力。
还是要给出公式要说明一下的:
Z就是做完和权重相乘+bias,A就是激活后的:
![]()
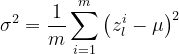

![]()
![]()
以上就是Batch Normalization的训练部分怎么改进了
总结一下啊:
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
其次BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了线性变换的操作(
),每个神经元增加了两个参数
核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢
BN的优势:
1. BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过normalize操作可以让激活函数的输入数据落在梯度非饱和区,缓解梯度消失的问题;另外通过自适应学习 与 又让数据保留更多的原始信息。
2. BN具有一定的正则化效果(这里我有点看不懂)
在Batch Normalization中,由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
3. BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
BN通过规范化与线性变换使得每一层网络的输入数据的均值与方差都在一定范围内,使得后一层网络不必不断去适应底层网络中输入的变化,从而实现了网络中层与层之间的解耦,允许每一层进行独立学习,有利于提高整个神经网络的学习速度。
4. BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
当学习率设置太高,回事的参数更新步伐过大,出现震荡恶化不熟练的现象,但是BN使得网络将不收到参数数值大小的影响。

我们可以看到,经过BN操作以后,权重的缩放值会被“抹去”,因此保证了输入数据分布稳定在一定范围内。所以不用怕学习率过大而导致模型不收敛的情况了。
优点这一部分也是参考知乎大哥的!PS注明!
6. 后面可能把激活函数,权重初始化也给补上,但估计会放在另外一篇,这篇太长了....看得眼睛疼,目前几大板块,激活,损失,正则化,优化算法,权重初始化还剩两个了