Tensorflow迁移学习实现猫狗大战
前言:本人初涉深度学习,水平十分有限,文章错谬之处敬请告知,不胜感激。同时希望同道之人多多交流。
文章目录
- 一、项目概述
-
- 1. 项目介绍
- 2. 评价指标
- 二、项目分析
-
- 1. 数据的探索
- 2. 图片尺寸可视化
- 3. 算法与技术
- 三、代码实现
-
- 1. 数据预处理
-
- (1) 数据集转TFRecords文件
- (2) 批次获取训练数据
- 2. 模型构建
- 3. 模型训练
- 4. 测试单张图片
- 5. 预测测试集
- 四、结果展示
-
- 1. 模型训练结果
- 2. 单张图片预测结果
- 3. 测试集预测结果
- 五、项目总结
一、项目概述
1. 项目介绍
本项目是机器学习竞赛平台kaggle上的一个图片分类项目Cats vs Dogs – 猫狗大战,项目要解决的问题是一个计算机视觉领域的图像二分类问题。项目提供了用于训练、测试的两部分数据,要求使用算法程序在训练集上对已分类的猫狗图片进行建模,然后利用建立的模型对测试集上多张打乱顺序的未标记猫和狗的图片进行推断。
2. 评价指标
使用交叉熵损失loss值作为评估指标,交叉熵损失函数是神经网络分类算法中常用的损失函数,其值越小说明模型拟合的分布约接近真实分布,模型表现越好。交叉熵损失函数公式定义如下:
L o g L o s s = − 1 n ∑ k = 1 n [ y k l o g ( y ^ k ) + ( 1 − y k ) l o g ( 1 − y ^ k ) ] LogLoss = \frac{-1}{n}\sum_{k=1}^n[y_klog(\widehat{y}_k)+(1-y_k)log(1-\widehat{y}_k)] LogLoss=n−1k=1∑n[yklog(y k)+(1−yk)log(1−y k)]
二、项目分析
1. 数据的探索
数据集包含训练集、测试集两部分,图片格式为JPEG。
训练集:包含25000张已标记的图片文件,文件名格式为“类别.图片id.jpg”,类别为cat或dog,图片id为数字,如cat.1.jpg、dog.2.jpg。
测试集:包含12500张未标记的图片文件,文件名格式为“图片id.jpg”, 图片id为数字,如1.jpg、2.jpg。
训练集数据中标记为猫、狗的图片分别有12500张,比例1:1,训练集、测试集比例为2:1。
数据集中图片尺寸大小不一,训练集、测试集图片尺寸分别有8513和4888种,在训练和预测时需要统一尺寸。根据模型输入数据尺寸要求reizse图片,比如AlexNet模型输入图片尺寸为227*227,本次运用的VGG19迁移学习模型输入图片尺寸为224*224。

2. 图片尺寸可视化
训练集、测试集如果尺寸分布差异很大,训练出来的模型可能在预测时表现不佳。为了确认这一点,对训练集、测试集图片尺寸分布进行了可视化,如图(左图为训练集,右图为测试集)。由可视化结果可见同一个集合里图片尺寸差异非常大,各尺寸分布比较平衡,训练集中存在两个离群点。训练集和测试集尺寸分布形状是相似的,并且除离群点外尺寸分布区间也是一致的,图片宽和高约在[30,500]像素之间,因此训练集训练出的模型是可以用于测试集的。


3. 算法与技术
图像分类目前最流行的解决方案是CNN(卷积神经网络),CNN是一种多层神经网络,使用多个卷积层、池化层堆叠提取图片特征,末端用多个全连接层堆叠得到概率,使用softmax归一化输出最终概率。常见的CNN有很多,如InceptionNet、VGG、ResNet、Inception-ResNet等,本次迁移学习使用的是VGG19模型。
在训练前,需对训练数据进行图像增强,即对图像进行随机上下左右翻转,亮度、色度、对比度和饱和度等调节,以此提高模型的泛化能力。
三、代码实现
注:tensorflow版本为1.12.0
1. 数据预处理
本项目数据预处理主要包含数据集转TFRecords文件格式,异常数据清理、训练集划分验证集、图片数据读取、标签独热编码、图像增强、数值归一化、分批、打乱顺序。
(1) 数据集转TFRecords文件
对应代码文件为 convert_to_tfrecords.py
import os
import cv2 as cv
import numpy as np
import tensorflow as tf
from skimage import io
def rebuild_data(file_dir, save_dir):
""" 将图片尺寸resize为224*224 """
print('Start to resize images...')
for file in os.listdir(file_dir):
file_path = os.path.join(file_dir, file)
try:
image = cv.imread(file_path)
image_resized = cv.resize(image, (224, 224))
save_path = save_dir + file
cv.imwrite(save_path, image_resized)
except:
print(file_path)
os.remove(file_path)
print('Finished!')
def read_data(file_dir):
""" 将训练数据分为训练集和验证集,并将其顺序打乱 """
cats, label_cats = [], []
dogs, label_dogs = [], []
# 异常图片的编号(非猫狗图片以及同时含有猫狗图片)
abnorm_img = {'cat': ['4338', '5351', '5418', '7377', '7564', '8100', '8456', '10029',
'10712', '11184', '12272', '724', '3822', '4688', '5355', '5583',
'7194', '7920', '9250', '9444', '10266', '10863', '11222', '11724'],
'dog': ['1773', '1259', '2614', '4367', '5604', '8736', '9517', '10237',
'10747', '10801', '11299', '2461', '8507', '1308', '1895', '4690',
'8898', '10161', '10190']}
label_reversed = {'cat': ["4085"],
'dog': ["2877", "4334", "10401", "10797", "11731"]}
# 读取标记好的图片和加入标签
for file in os.listdir(file_dir):
name = file.split(sep='.') # 照片的格式是cat.1.jpg
if (name[0] == 'cat' and name[1] not in abnorm_img['cat']) or \
(name[0] == 'dog' and name[1] not in abnorm_img['dog']):
if (name[0] == 'cat' and name[1] not in label_reversed['cat']) or \
(name[0] == 'dog' and name[1] in label_reversed['dog']):
cats.append(os.path.join(file_dir, file))
label_cats.append(0)
elif (name[0] == 'dog' and name[1] not in label_reversed['dog']) or \
(name[0] == 'cat' and name[1] in label_reversed['cat']):
dogs.append(os.path.join(file_dir, file))
label_dogs.append(1)
print('There are %d cats\nThere are %d dogs' % (len(cats), len(dogs)))
# 打乱猫狗两类别的顺序
cats_temp = np.c_[np.array(cats), np.array(label_cats)]
dogs_temp = np.c_[np.array(dogs), np.array(label_dogs)]
np.random.shuffle(cats_temp)
np.random.shuffle(dogs_temp)
# 训练集与验证集比例为4:1
div_num = int(len(cats) * 0.8)
train_cats = cats_temp[:div_num, :]
valid_cats = cats_temp[div_num:, :]
train_dogs = dogs_temp[:div_num, :]
valid_dogs = dogs_temp[div_num:, :]
# 打乱训练集与验证集顺序
train_data = np.r_[train_cats, train_dogs]
valid_data = np.r_[valid_cats, valid_dogs]
np.random.shuffle(train_data)
np.random.shuffle(valid_data)
# 生成训练集/验证集的图片和标签列表
train_img_list = train_data[:, 0]
train_lbl_list = train_data[:, 1].astype(np.int)
valid_img_list = valid_data[:, 0]
valid_lbl_list = valid_data[:, 1].astype(np.int)
return train_img_list, train_lbl_list, valid_img_list, valid_lbl_list
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convert_to_tfrecords(image_list, label_list, save_dir, name):
""" 将图片地址列表和标签列表存成TFRecords文件格式 """
filename = os.path.join(save_dir, name + '.tfrecords')
n_samples = len(label_list)
writer = tf.python_io.TFRecordWriter(filename) # 实例化并传入保存文件路径
print('\nStart to transform...')
for i in np.arange(0, n_samples):
try:
image = io.imread(image_list[i])
image_raw = image.tostring()
label = int(label_list[i])
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw': bytes_feature(image_raw),
'label': int64_feature(label)
}))
writer.write(example.SerializeToString())
except IOError:
print('Could not read:', image_list[i])
writer.close()
print('Finished!')
# 将训练与测试图片resize至224*224,并将训练图片划分为训练集与验证集,将图片与标签存成TFRecods文件
rebuild_data('..\\data\\train', '..\\data\\train_image_resized\\')
rebuild_data('..\\data\\test', '..\\data\\test_image_resized\\')
train_img_list, train_lbl_list, valid_img_list, valid_lbl_list = read_data('..\\data\\train_image_resized')
convert_to_tfrecords(train_img_list, train_lbl_list, '..\\data\\tfrecords', 'train_img_lbl')
convert_to_tfrecords(valid_img_list, valid_lbl_list, '..\\data\\tfrecords', 'valid_img_lbl')
(2) 批次获取训练数据
对应代码文件为 input_data.py
import tensorflow as tf
import numpy as np
import cv2 as cv
def _parse_record(example_proto):
""" 解析tfrecords文件 """
features = {
'image_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)
}
parsed_features = tf.parse_single_example(example_proto, features=features)
return parsed_features
def data_processing(dataset):
"""
图片:解码,图像增强(随机左右翻转,色度/对比度/亮度/饱和度调节),归一化
标签:独热编码
"""
image = tf.decode_raw(dataset['image_raw'], tf.uint8)
image = tf.reshape(image, [224, 224, 3])
image = tf.image.random_flip_left_right(image)
image = tf.image.random_hue(image, max_delta=0.05)
image = tf.image.random_contrast(image, lower=0.3, upper=1.0)
image = tf.image.random_brightness(image, max_delta=0.2)
image = tf.image.random_saturation(image, lower=0.0, upper=2.0)
image = tf.image.per_image_standardization(image)
label = tf.cast(dataset['label'], tf.int32)
label = tf.one_hot(label, 2)
return image, label
def get_batch(tfrecords_file, batch_size):
""" 从tfrecords文件中取出批次数据 """
# 读取tfrecords文件,创建dataset实例
dataset = tf.data.TFRecordDataset(tfrecords_file)
# 针对dataset中每一组图片/标签数据进行解析和处理
dataset = dataset.map(_parse_record)
dataset = dataset.map(data_processing)
# 无限重复数据集
dataset = dataset.repeat()
# 设置dataset中batch大小,并打乱顺序
dataset = dataset.shuffle(100)
dataset = dataset.batch(batch_size=batch_size)
# 从迭代器中迭代batch数据
iterator = dataset.make_one_shot_iterator()
img_batch, lbl_batch = iterator.get_next()
return img_batch, lbl_batch
'''
# 测试代码
batch_size = 8
img_batch, lbl_batch = get_batch('..\\data\\tfrecords\\train_img_lbl.tfrecords', batch_size)
with tf.Session() as sess:
images, labels = sess.run([img_batch, lbl_batch])
# 注意:如果img_batch和lbl_batch不是同时sess.run,图片与标签便不是同一批次
# images = sess.run(img_batch)
# labels = sess.run(lbl_batch)
print(images.shape)
print(labels)
for i in np.arange(batch_size):
image = images[i].astype(np.uint8)
label = '%d is ' % i + str(labels[i])
cv.imshow(label, image)
cv.waitKey()
'''
2. 模型构建
导入VGG19模型参数,文件为“imagenet-vgg-verydeep-19.mat”,最后添加全连接层fc_layer进行分类
对应代码文件为 model.py
import numpy as np
import tensorflow as tf
import scipy.io as scio
def batch_norm(inputs, is_training, is_conv_out=True, decay=0.999):
""" 正则化处理数据集,减小输入数据属性分布带来的影响 """
scale = tf.Variable(tf.ones([inputs.get_shape()[-1]]))
beta = tf.Variable(tf.zeros([inputs.get_shape()[-1]]))
pop_mean = tf.Variable(tf.zeros([inputs.get_shape()[-1]]), trainable=False)
pop_var = tf.Variable(tf.ones([inputs.get_shape()[-1]]), trainable=False)
if is_training:
if is_conv_out:
batch_mean, batch_var = tf.nn.moments(inputs, [0, 1, 2])
else:
batch_mean, batch_var = tf.nn.moments(inputs, [0])
train_mean = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay))
train_var = tf.assign(pop_var, pop_var * decay + batch_var * (1 - decay))
with tf.control_dependencies([train_mean, train_var]):
return tf.nn.batch_normalization(inputs, batch_mean, batch_var, beta, scale, 0.001)
else:
return tf.nn.batch_normalization(inputs, pop_mean, pop_var, beta, scale, 0.001)
def conv_layer(input_layer, weights, bias):
conv = tf.nn.conv2d(input_layer, tf.constant(weights), strides=[1,1,1,1], padding="SAME")
return tf.nn.bias_add(conv, bias)
def pool_layer(input_layer):
return tf.nn.max_pool(input_layer, ksize=(1,2,2,1), strides=[1,2,2,1], padding="SAME")
def vgg_net(model_path, img_batch):
layers = ('conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4'
)
# 读取VGG19模型参数
data = scio.loadmat(model_path)
weights = data['layers'][0]
net = {}
current = img_batch
for i, name in enumerate(layers):
kind = name[:4]
if kind == 'conv':
kernels, bias = weights[i][0][0][0][0]
kernels = np.transpose(kernels, [1, 0, 2, 3])
bias = bias.reshape(-1)
current = conv_layer(current, kernels, bias)
current = batch_norm(current, True)
elif kind == 'relu':
current = tf.nn.relu(current)
elif kind == 'pool':
current = pool_layer(current)
net[name] = current
assert len(net) == len(layers)
return net
def fc_layer(net, batch_size, n_classes, keep_prob):
with tf.variable_scope("fc1"):
image = tf.reshape(net["relu5_4"], [batch_size, -1])
weights = tf.Variable(tf.random_normal(shape=[14 * 14 * 512, 1024], stddev=0.1))
bias = tf.Variable(tf.zeros(shape=[1024]) + 0.1)
fc1 = tf.add(tf.matmul(image, weights), bias)
fc1 = batch_norm(fc1, True, False)
fc1 = tf.nn.tanh(fc1)
fc1 = tf.nn.dropout(fc1, keep_prob)
with tf.variable_scope("fc2"):
weights = tf.Variable(tf.random_normal(shape=[1024, n_classes], stddev=0.1))
bias = tf.Variable(tf.zeros(shape=[n_classes]) + 0.1)
logits = tf.add(tf.matmul(fc1, weights), bias)
return logits
def calc_loss(logits, lbl_batch):
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(labels=lbl_batch, logits=logits))
return loss
def train_step(loss, learning_rate_base, learning_rate_decay, epochs, decay_step):
learning_rate = tf.train.exponential_decay(
learning_rate_base, epochs, decay_step, learning_rate_decay)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss)
return train_op
def pred_model(logits, lbl_batch):
prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(lbl_batch, 1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
3. 模型训练
对应代码文件为 training.py
import os
import time
import platform
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import input_data
import model
n_classes = 2 # 猫和狗
batch_size = 32 # 训练集批次大小:32/64
valid_batch_size = 64 # 验证集批次大小
learning_rate_base = 1e-4 # 基础学习率
learning_rate_decay = 0.996 # 衰减率
decay_step = 100 # 衰减速度
epochs = 2000 # 训练次数
display_step = 50 # 结果打印间隔
plot_step = 10 # 画图点间隔
save_step = 500 # 模型保存间隔
VGG_PATH = 'Model\\imagenet-vgg-verydeep-19.mat' # VGG19模型参数路径
train_file = '..\\data\\tfrecords\\train_img_lbl.tfrecords' # tfrecords训练文件路径
valid_file = '..\\data\\tfrecords\\valid_img_lbl.tfrecords' # tfrecords验证文件路径
logs_dir = 'logs_dir\\0911' # 日志保存路径
save_dir = 'saved_model\\0911' # 模型保存路径
def draw_chart(position, title, ylabel, step_list, y_list):
plt.gcf().set_facecolor(np.ones(3) * 240 / 255)
plt.subplot(position)
plt.title(title, fontsize=18)
plt.xlabel('step', fontsize=12)
plt.ylabel(ylabel, fontsize=12)
plt.tick_params(which='both', top=False, right=True,
labelright=True, labelsize=10)
plt.grid(linestyle=':')
plt.plot(step_list, y_list, c='orangered')
def show_chart():
mng = plt.get_current_fig_manager()
if 'Windows' in platform.system():
mng.window.state('zoomed')
else:
mng.resize(*mng.window.maxsize())
plt.tight_layout()
plt.show()
def main():
# 训练模型
train_img_batch, train_lbl_batch = input_data.get_batch(train_file, batch_size)
train_net = model.vgg_net(VGG_PATH, train_img_batch)
train_logits = model.fc_layer(train_net, batch_size, n_classes, 0.8)
train_loss = model.calc_loss(train_logits, train_lbl_batch)
train_op = model.train_step(train_loss, learning_rate_base, learning_rate_decay, epochs, decay_step)
train_ac = model.pred_model(train_logits, train_lbl_batch)
# 验证模型
valid_img_batch, valid_lbl_batch = input_data.get_batch(valid_file, valid_batch_size)
valid_net = model.vgg_net(VGG_PATH, valid_img_batch)
valid_logits = model.fc_layer(valid_net, valid_batch_size, n_classes, 1)
valid_loss = model.calc_loss(valid_logits, valid_lbl_batch)
valid_ac = model.pred_model(valid_logits, valid_lbl_batch)
# 创建画图所需数据list
step_list = list(range(int(epochs / plot_step)))
train_list1, train_list2 = [], []
valid_list1, valid_list2 = [], []
tf.summary.scalar('train_loss', train_loss)
tf.summary.scalar('train_ac', train_ac)
tf.summary.scalar('valid_loss', valid_loss)
tf.summary.scalar('valid_ac', valid_ac)
summary_op = tf.summary.merge_all() # log汇总记录
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 产生一个writer来写log文件
train_writer = tf.summary.FileWriter(logs_dir, sess.graph)
# 产生一个saver来存储训练好的模型
saver = tf.train.Saver()
start_time = time.time() # 记录训练开始时间
for i in np.arange(epochs):
tra_loss, _, tra_ac = sess.run([train_loss, train_op, train_ac])
# 每隔plot_step验证一次,并记录数据点
if i % plot_step == 0:
val_loss, val_ac = sess.run([valid_loss,valid_ac])
train_list1.append(tra_loss)
train_list2.append(tra_ac)
valid_list1.append(val_loss)
valid_list2.append(val_ac)
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str, i)
# 每隔display_step打印一次结果
if i % display_step == 0:
print('Step_%d, tra_loss = %.4f, tra_ac = %.2f%%, val_loss = %.4f, val_ac = %.2f%%' %
(i, tra_loss, tra_ac * 100, val_loss, val_ac * 100.0))
# 每隔save_step保存一次模型
if i % save_step == 0 or (i + 1) == epochs:
checkpoint_path = os.path.join(save_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=i)
end_time = time.time() # 记录训练结束时间
print("Training over. It costs {:.2f} minutes".format((end_time - start_time) / 60))
draw_chart(221, 'Train Loss', 'loss', step_list, train_list1)
draw_chart(222, 'Train Accuracy', 'accuracy', step_list, train_list2)
draw_chart(223, 'Valid Loss', 'loss', step_list, valid_list1)
draw_chart(224, 'Valid Accuracy', 'accuracy', step_list, valid_list2)
show_chart()
if __name__ == '__main__':
main()
4. 测试单张图片
对应代码文件为 test_one_image.py
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import model
def get_one_image(test_dir):
""" 从指定目录中随机选取一张图片 """
files = os.listdir(test_dir)
n = len(files) # 获取长度,即总共多少张图片
rand_num = np.random.randint(0, n) # 从0到n中随机选择一个数字
print('The image is %d' % rand_num)
image_name = str(rand_num) + '.jpg'
image_path = os.path.join(test_dir, image_name)
image_path = tf.cast(image_path, tf.string)
image_str = tf.read_file(image_path)
original = tf.image.decode_jpeg(image_str, channels=3)
image = tf.image.resize_images(original, (224, 224))
image = tf.image.per_image_standardization(image)
image = tf.reshape(image, [1, 224, 224, 3])
return original, image
def main():
VGG_PATH = 'Model\\imagenet-vgg-verydeep-19.mat'
original, image = get_one_image('..\\data\\test')
image_net = model.vgg_net(VGG_PATH, image)
logit = model.fc_layer(image_net, 1, 2, 1)
logit = tf.nn.softmax(logit)
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state('saved_model\\0911')
if ckpt and ckpt.model_checkpoint_path:
global_step = ckpt.model_checkpoint_path.split('\\')[-1].split('-')[-1]
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading success, global_step is %s' % global_step)
else:
print('No checkpoint file found')
prediction = sess.run(logit)
print(prediction)
max_index = np.argmax(prediction)
if max_index == 0:
print('This is a cat with possibility %.4f%%' % (prediction[:, 0] * 100))
plt.title('This is a cat', fontsize=18)
else:
print('This is a dog with possibility %.4f%%' % (prediction[:, 1] * 100))
plt.title('This is a dog', fontsize=18)
original = sess.run(original).astype(np.uint8)
plt.imshow(original)
plt.show()
if __name__ == "__main__":
main()
5. 预测测试集
对应代码文件为 test_all.py
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import model
def read_data(file_dir):
""" 读取测试集,返回图片地址列表 """
image_list = []
for file in os.listdir(file_dir):
num = file.split('.')[0]
image_list.append([os.path.join(file_dir, file), num])
print('There are %d images' % len(image_list))
# 图片地址列表按照编号大小重新排序
sorted_indices = np.argsort(np.array(image_list)[:, 1].ravel().astype(int))
image_list = (np.array(image_list)[:, 0].ravel())[sorted_indices]
return image_list
def image_processing(image):
""" 图片解码,尺寸调整,归一化 """
image_str = tf.read_file(image)
image_decoded = tf.image.decode_jpeg(image_str, channels=3)
image_resized = tf.image.resize_images(image_decoded, (224, 224))
image_norml = tf.image.per_image_standardization(image_resized)
return image_norml
def get_batch(image_list, batch_size):
""" 获取测试集图片batch """
image_list = tf.cast(image_list, tf.string)
dataset = tf.data.Dataset.from_tensor_slices(image_list)
dataset = dataset.map(image_processing)
dataset = dataset.batch(batch_size=batch_size)
iterator = dataset.make_one_shot_iterator()
test_img_batch = iterator.get_next()
return test_img_batch
def main():
batch_size = 50
image_list = read_data('..\\data\\test')
test_img_batch = get_batch(image_list, batch_size)
test_image_net = model.vgg_net('Model\\imagenet-vgg-verydeep-19.mat', test_img_batch)
logits = model.fc_layer(test_image_net, batch_size, 2, 1)
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state('saved_model\\0911')
if ckpt and ckpt.model_checkpoint_path:
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading success, global_step is %s' % global_step)
else:
print('No checkpoint file found')
pred_list = []
# 批次预测测试集,将标签结果写入CSV文件
for i in np.arange(int(len(image_list) / batch_size)):
prediction = sess.run(logits)
max_index = np.argmax(prediction, axis=1)
for j in max_index:
pred_list.append(j)
if i % 25 == 0:
print('%d images have been predicted' % (i * 50))
dataframe = pd.DataFrame({'id': list(range(1, len(pred_list) + 1)), 'label': pred_list})
dataframe.to_csv("pred_test.csv", index=False, sep=',')
if __name__ == '__main__':
main()
四、结果展示
1. 模型训练结果
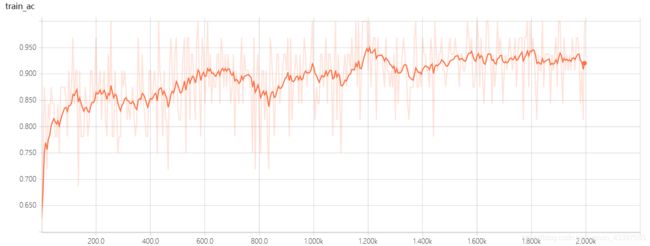
因为迁移学习loss函数收敛较快,本次模型训练次数为2000次,训练集batch大小为32,验证集batch大小为64。从训练集和验证集的accuracy图像可以看出,模型大概在1600次时就已经开始收敛,正确率达93%左右。



2. 单张图片预测结果
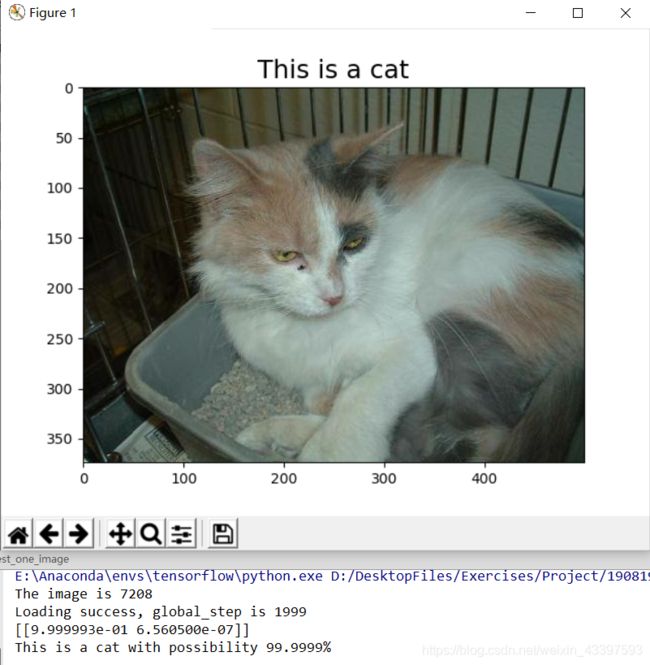
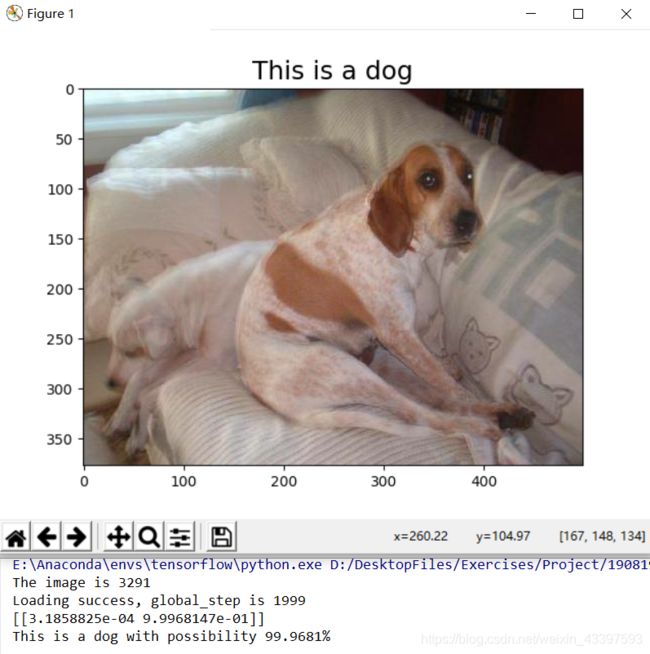
运行文件 test_one_image.py,预测测试集图片,随机测试20次,预测结果均正确,部分展示如下:


3. 测试集预测结果
运行文件 test_all.py,测试集预测结果会写入CSV文件中,将pred_test.csv文件提交至kaggle网上,得分: 2.38458。由于模型原因,loss分数并不算低,说明模型仍需优化。

五、项目总结
本次迁移学习运用的预训练模型为VGG19,此模型于2014年由牛津大学提出,本质上是在更细的粒度上实现的AlexNet,虽然CNN的模型深度有所增加,但是后来的GoogleNet、ResNet、Inception-ResNet等模型在分类上优化更好,可以使用这些模型进行进一步Finetuning。另一方面也可考虑多个预训练模型集成,集成时使用模型的预训练权重进行特征提取,提取特征后进行拼接,再dropout加全连接进行训练,这样通过不同模型学到的不同特征组合很可能获得更高的精度、更低的loss。