京东到家评价系统存储架构演进
前言
一、业务场景
1. 评价生成
2. 评价处理
二 架构演进
1. 系统初创
2. 存储多元化
3. 架构再升级
三 展望
四 总结
前言
京东到家作为即时零售的电商平台,致力于将万千好物即时送到消费者的手中,为实体门店提供线上履约能力,竭力为传统零售商提供线上线下融合的一体化解决方案。
由于网络自身的特点,信息可以在很短的时间内,以非常低的成本,传播、被很多人接受。同样,电商交易中的卖家一旦积累了良好的信用度,就有机会吸引到更多的买家。因此我们设计并投入使用了京东到家评价系统。评价是订单完成确认收货后的重要环节。希望通过阅读本文,带你了解评价系统的存储架构演进过程。
一、业务场景
评价系统业务结构图所示,我们的业务大致分为三部分:用户端、商家端、运营端。
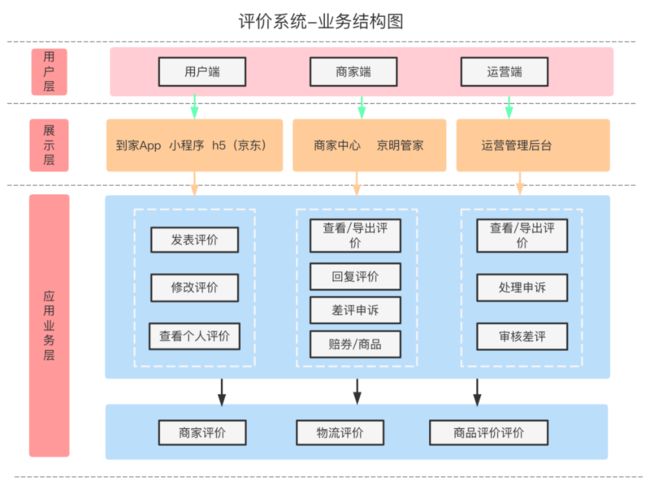
评价业务目前支持C端用户对商家服务、物流配送、商品的评价。并且为用户和商家提供了投诉、举报场景的支持。消费者的评价对商家和物流提供更好服务起到了很好的促进作用,同时对于一些恶意差评,也为商家提供了申诉的入口。
1. 评价生成
上文简单介绍了评价系统现有的业务模块,现在跟大家具体描述一下业务形态。
业务流程图:

评价生成的前置状态是订单已完成。订单完成后我们会订阅订单系统下发的MQ消息,这时候会记录一条订单数据到评价系统。用户在时效期内可以对购买的商品、商家服务、物流服务三个维度给予评价。买家的反馈也是卖家非常关注的。好评率会影响到商品排名和商家的综合评分。
2. 评价处理
评价示例:

打分指标:
| 商家服务/物流服务 |
好评 |
4星、5星 |
| 中评 |
3星 |
|
| 差评 |
1星 2星 |
|
| 单个商品 |
点赞 |
5分 |
| 点踩 |
2分 |
1. 商家端
查看/回复评价:商家可以在商家后台界面或者商家APP查看用户发布的评价信息。可以对其评价进行回复。
商家申诉:商家对用户恶意差评发起线上申诉。
赔券:商家可以对用户差评进行处理,比如与用户进行线下沟通,做赔券补偿处理。
2. 运营端
差评审核:运营客服针对物流或对商家的差评/投诉进行审核处理。推动差评问题改善。
申诉审核:商家对恶意差评的申诉,需要运营客服审核。
二 架构演进

评价系统框架采用分层设计,依据不同的功能划分模块,首先是基础服务层,服务层里又分为持久层、数据层、逻辑层,主要提供数据支持和业务逻辑处理。上层服务(应用层、表现层)比如商家Web端、运营Web、网关等调用底层服务实现业务数据转发。实现高内聚低耦合,做到应用服务间相互独立,灵活部署。使用消息中间件实现数据同步。采用统一监控和告警服务平台,实现多方位监控、服务告警、全链路跟踪、日志采集。
上下游依赖:

1. 系统初创
评价系统的基础数据来源于订单数据,每一笔订单完成之后都会通过消费MQ消息的形式将数据存储到评价系统的订单商品数据表,评价完成后会记录评价信息到订单评价表和商品评价表。一开始我们采用的存储组件是MySql。
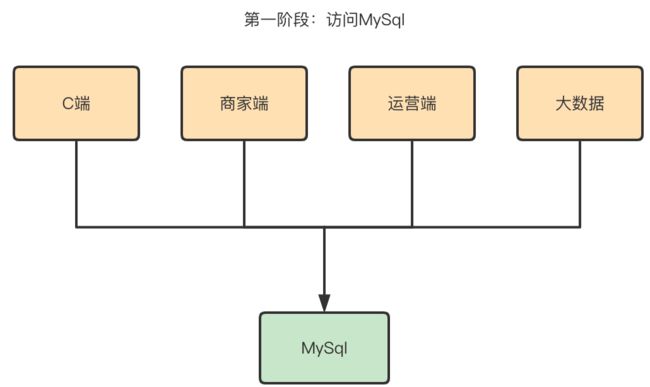
存在问题:
-
海量数据的日益增长,因为每一笔成交的订单我们都会存储,而订单的数据量单月增长量在千万量级。
-
业务多维化,最开始的业务比较简单,只围绕订单展开的评价,后期需要对商家、物流、商品多维度进行评价,评价界面也更加丰富,数据结构发生巨大变化。
-
高并发,QPS持续升高,随着业务量的增长,日访问量也在直线上涨。评价系统同时面临读和写的高并发压力。
-
无法保证系统高可用,MySql同时支撑多端(C端、运营端、商家端、大数据)的业务,一旦MySql出现问题,那将是灾难性的。
-
接口访问性能无法满足核心业务要求,对于C端和商家端来说性能要求较高,大数据一抽数就有可能影响了C端业务的响应时间。
采取措施:
一开始我们对数据库进行主从配置,进行读写分离,增删改和C端读取的时候用主库,非核心业务(运营、大数据)读取的时候用从库,这样也能有效提高数据库的读写效率;
新的问题:
主从分离一段时间后,我们发现还是有问题,有些业务需要进行一些复杂的sql(比如报表查询),随着业务的复杂性,我们发现B端与C端是相互影响的,并且随着数据量的增加、访问量的增加都会影响数据库的稳定性,我们首先想到的是给MySql进行分库。
问题分析:
-
数据特点:大文本,C端用户评价内容是非常大的,一个订单可能有20个sku,如果针对每一个sku写评价每个写1k的评价,那一个订单(包括物流评价等)的评价数据整体大小达到200k。
-
查询场景:大多数场景来说需要一次性返回评价详情,评价详情包括订单+商品的全部评价数据。
为什么没有继续使用MySql存储:
-
大文本在MySql查询的时候性能非常低,而且本身用MySql去存储大文本就是不合理的。
-
基于订单维度一次性查询用sql具有缺陷。查询可能导致IO急剧上升。
-
对于MySql语句的扩展需要连表查询,数据量又大,sql维护会越来越复杂。
考虑到维护性、容量、成本等问题,我们此时就不考虑关系型数据库了。我们聚焦到NoSQL,NoSQL选型很多,包括ES、HBase、 MongoDb、Redis等。存储组件的选型要考虑很多,重点是解决核心问题。
2 存储多元化
我们根据不同的应用场景、数据结构去分析,怎样才能解决评价存储的实际问题?
-
业务特点:评价数据具有业务强相关性,什么叫业务强相关性呢?意思就是评价大致可以划分为订单维度的评价和商品sku维度的评价,业务数据划分明确。
-
应用场景:从应用场景上来说,评价读的场景要多于写的场景。读的峰值主要出现在门店主页,门店主页主要提供门店综合评分以及门店评价数据,压测峰值可达到上百万QPS。
-
数据结构:一笔订单会有多个商品,这样在存储结构上来说就是1对多的关系。而大多数场景来说评价详情需要返回订单+所有商品的评价数据。
-
核心问题:大数据量、富文本问题、业务新属性扩展问题。
存储组件的选型:
-
假设我们用ES来解决这些问题,也不是不可行。但是ES有个致命的缺陷,它是非实时的,刷盘或者refresh延迟处理都会导致es在更新之后并不是立即可见(可查询)的,对于C端用户来说这个问题是无法容忍的,用户提交评价需要立即就能看到提交结果。
-
那Redis能不能解决这个问题?也能。但是用Redis成本太高,大对象也会造成性能/吞吐量的问题,热点门店可能产生热key问题。
-
Hbase能解决吗?可以解决。我们核心问题是:富文本、大数据量、支持实时入库和快速随机访问的问题;虽然Hbase也存在功能局限性,但是就目前来说它是最符合系统要求的。
Hbase存储组件的应用:
-
将全量的数据放入hbase,存储PB级海量数据。而且Hbase 底层使用HDFS,HDFS 本身也有备份,具有高可靠性。
-
以订单id作为全局唯一的主键(RowKey),散落存储任意数量的列(Column)。结构化的存储,数据查询key-value的形式,即订单号对应一条完整的评价详情(包括扩展信息、多个商品信息),解决富文本问题。
-
基于订单id (RowKey)的单行查询,查询只需要少数几个字段时,能大大减少读取的数据量。
其实到这里,Hbase支撑C端业务,MySql支撑商家端、运营和大数据,已经实现了读写分离。但是基于系统高可用上来说,为了进一步降低C端与商家端和运营端的相互影响,还要考虑C端实时性问题,我们选择用Redis来彻底解决C端的高可用问题。
示例:

我们先分析一下,这些数据有什么特点?
-
重复高频次的访问,读取频次远高于修改频次;
-
以门店为维度的评分统计,对象数据量不大;
-
高并发,C端服务调用,还要保证高可用、高性能。
1. 对于这些热点数据我们是怎么存储的呢?
是以门店为维度的统计,所以把相关联的多项数据存储在同一个散列中,以便对这些数据进行管理或执行相关操作。采用redis散列(Map)结构存储,Redis的散列键会将一个键和一个散列在数据库中关联起来,可以在散列中设置任意多个字符串键值对。比如商家评价5分,那么字段代表5的分值就会次数增量+1,删除评价就会次数增量 -1。

2. 商品好评度计算接口超时问题
业务场景:批量计算商品好评度需要get一批key的value,提供数据给搜索系统。
问题原因:循环向redis服务器发起请求命令导致client阻塞。
解决方案:使用管道(pipeline)查询,用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。但是打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。防止pipeline中请求过多独占链接,根据具体情况采用每20个请求用一个pipelineClient提交。
执行效果

3 架构再升级
随着业务的不断扩展,对我们有了新的挑战:用户在评价的时候可以选择多个评价标签,某些场景下要依据某个标签进行搜索、统计,统计该标签下的所有相关评价;
方案选型
-
以标签为维度去进行关联存储,存储到MySql,但是这样数据量太大,业务复杂,维护成本太高。
-
至于作为单个属性进行存储,用Like去查询统计,这个方案就不考虑了,对于C端来说性能太低。
-
用Redis解决,Redis数据结构具有局限性,无法满足业务诉求。
-
引入ElasticSearch,ES可以解决搜索问题。也能应对在高并发场景下实现接口的高可用。
实际应用
-
ES只存储需要用于检索的关键字段;
-
ES只用来搜索,利用ES查出唯一的key(即订单id),配合hbase做单行查询,获取评价详情,大大提高系统性能;
ES深分页问题
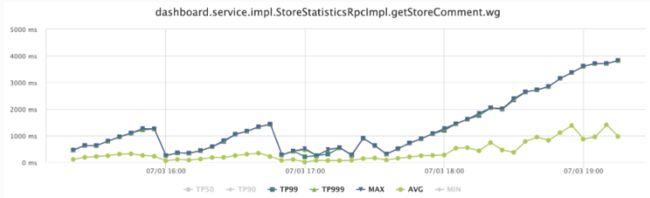
问题背景:门店评价详情查询接口监控告警(接口 TP99 和 TP999 飙升到正常情况的几十倍),定位造成接口性能异常的原因,发现是es深分页的问题导致。被刷到 1000多 页。
from&size分页为什么会出现这种情况呢?
-
在 Elasticsearch 中,查询的过程大体上分为查询(query)和取回(fetch)两个阶段。这个节点的任务是广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
-
如请求第1001页,Elasticsearch不得不取出所有分片上的第1页到第1001页的所有文档,并做排序,最终再取出from后的size条结果作最终的返回。假设你有10个分片,则需要在coordinate node汇总到 shards* (from+size)条记录,即需要10*(1001+10)记录后做一次全局排序。所以,当索引非常非常大(千万或亿),是无法使用from + size 做深分页的,分页越深则越容易OOM,即便不OOM,也很消耗CPU和内存资源。
解决方案:
-
传统方式(from&size),为了避免深分页,不允许使用分页(from&size)查询100页以后的数据。
-
Scroll 滚动游标方式,用于非实时查询场景。
-
Search After深度分页,用于实时查询场景。
处理结果:最终选用第一种方案,不允许使用分页(from&size)查询100页以后的数据。

三 展望
数据存储:

数据应用:

评价系统用了Redis、Hbase、ES、Mysql四种存储组件,在存储组件优化升级的道路上越走越宽。但是这不一定就是最合适的。因为组件越多就意味着维护成本就越高,数据一致性就越难保证。因此我们引入tidb存储组件探索替换其他存储组件的可能性,目的是做数据存储的统一收口。


引入新组件,我们先从非核心业务做起。为了降低业务风险,决定先从Mysql通过BinLog同步数据到Tidb的方式,即Tidb作为Mysql的从库。后期读Tidb,将一些非核心业务的CRUD全部切到Tidb。
Tidb落地效果:
根据检索条件查询 tidb 平均查询速率avg=5ms ;mysql 平均查询速率avg=12ms ;
性能对比:
Tidb:

Mysql:
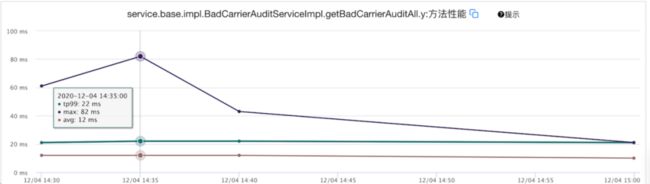
结论:
-
可以看出tidb的查询速率明显高于mysql。数据量越大性能对比越明显。
-
Tidb具有一键水平扩容或者缩容的能力、金融级高可用、实时 HTAP等特点,存储海量数据没有压力。
-
作为一个分布式的提供事务的 Key-Value 存储引擎,支持MySql协议对业务屏蔽了分库分表。
在架构设计上替换Hbase+MySql是可行的。但是就目前来说,我们的Tidb在运维方面成熟度还不够。因此我们实施灰度策略,灵活切换MySql、Tidb两个数据源。不过日后还是会在架构演进方向上继续摸索前行,利用Tidb做评价数据存储的统一收口方案。
四 总结
随着业务的发展,入驻的商家门店越来越多,万千好物百花齐放,评分对商家的复购率影响深远,评价系统的稳定运行也显得尤为重要。我们评价系统的研发人员一直在对系统架构做优化升级。不断提升系统性能,竭力提升用户体验。在这期间也遇到了一些需要解决和完善的问题,我们根据评价系统不同时间段的应用场景,对数据进行异构、读写分离、缓存使用、分布式数据策略建设数据架构,不断追求技术创新。期待未来我们的评价系统更加智能化,用户体验越来越好。
参考文献:
-
https://www.likecs.com/show-204969784.html
-
https://pingcap.com/zh/
文|马娇
编辑|刘慧卿