深度学习模型试跑(九):HRNet / HRNet-Semantic-Segmentation

目录
- 前言
- 一.模型解读
- 二.模型训练
-
- 1.数据转换
- 2.配置
- 3.开始训练
- 三.模型推理
前言
官方项目地址:
mmsegmentation地址:
一.模型解读
具体参考
二.模型训练
我的环境
os: win10
cuda: 11.0
gpu: RTX3090
torch: 1.7.0
代码: 因为要使用libtorch,所以选择了mmsegmentation的,因为这里有形成的转换代码
1.数据转换
支持4类数据(voc2012, cityscapes, pascal_context, ade20K), 我选择的是voc2012,因这个数据模式相对熟悉一些。
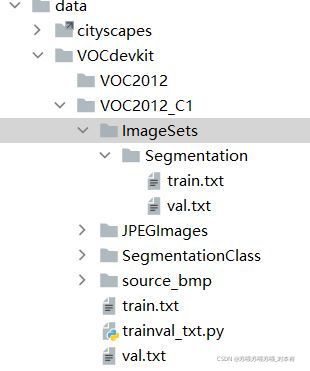
labelme转voc2012的程序应该有很多,可以在网上找。
—VOC2012_C1: 我自己的数据集
——ImageSets: 放置验证集和训练集文档
——JPEGImages: 放置原始训练及验证图片(jpg格式)
——SegmentationClass: 放置标签图片(png格式)
2.配置
配置可参考我上一篇,因为都是在mmsegmentation下做的
修改的地方我用中文注释出来了,实际应用的时候不要带中文。
总配置文件: fcn_hr18_512x512_40k_voc12augPG.py
参考: fcn_hr18_512x512_40k_voc12aug.py
_base_ = [
'../_base_/models/fcn_hr18.py', '../_base_/datasets/pascal_voc12_augPG.py',
'../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py'
]
model = dict(decode_head=dict(num_classes=3))
根据总配置文件,逐步设置各个分支配置文件,以下的py程序我都是复制了相关分支的配置脚本
fcn_hr18.py: 不用修改
pascal_voc12_augPG.py:
_base_ = './pascal_voc12PG.py'
# dataset settings
data = dict(
train=dict(
ann_dir=['SegmentationClass'],
split=[
'ImageSets/Segmentation/train.txt'
]))
pascal_voc12PG.py:
# dataset settings
dataset_type = 'PGC1VOCDataset'
data_root = 'data/VOCdevkit/VOC2012_C1'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
#由于pascal_voc12PG.py改变了数据集类型,需要在mmseg/datasets/voc.py中添加一类,
voc.py
import os.path as osp
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class PascalVOCDataset(CustomDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor')
PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
[128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
[192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
[192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
[128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
def __init__(self, split, **kwargs):
super(PascalVOCDataset, self).__init__(
img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
assert osp.exists(self.img_dir) and self.split is not None
@DATASETS.register_module()
class PGC1VOCDataset(CustomDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'scratch', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor')
PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
[128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
[192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
[192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
[128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
def __init__(self, split, **kwargs):
super(PGC1VOCDataset, self).__init__(
img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
assert osp.exists(self.img_dir) and self.split is not None
@DATASETS.register_module()
class UcontrolVOCDataset(CustomDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'myoepithelium', 'neutrophil', 'unlabeled', 'macrophage', 'lymphocyte', 'apoptotic_body',
'plasma_cell', 'fibroblast', 'mitotic_figure', 'tumor', 'vascular_endothelium', 'eosinophil')
PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
[128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
[192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
[192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
[128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
def __init__(self, split, **kwargs):
super(UcontrolVOCDataset, self).__init__(
img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
assert osp.exists(self.img_dir) and self.split is not None
default_runtime.py
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook') #打开Tensorboard
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='gloo') #设置为gloo,NCCL只支持linux系统
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
schedule_80k.py: 不用修改
3.开始训练
训练脚本:
python tools/train.py configs/hrnet/fcn_hr18_512x512_40k_voc12augPG.py
训练的时候会报错,
错误1:
data[‘category_id’] = self.cat_ids[label]
IndexError: list index out of range
解决方法:
我到mmdet/datasets/coco.py下,找到每个self.cat_ids[label]的位置,然后在前面添加一句if label < 1:
例如
for i in range(bboxes.shape[0]):
if label < 1:
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(bboxes[i][4])
data['category_id'] = self.cat_ids[label]
json_results.append(data)
错误2:想不起来啦,暂时先放着
三.模型推理
from mmseg.apis import inference_segmentor, init_segmentor
# config_file = 'configs/setr/setr_pup_512x512_160k_b16_ade20k.py'
# checkpoint_file = 'checkpoints/setr_pup_512x512_160k_b16_ade20k_20210619_191343-7e0ce826.pth'
config_file = 'configs/hrnet/fcn_hr18_512x512_40k_voc12augPG.py'
checkpoint_file = 'checkpoints/fcn_hr18_512x512_40k_voc12augPGC1.pth'
# build the model from a config file and a checkpoint file
model = init_segmentor(config_file, checkpoint_file, device='cuda:0')
# test a single image and show the results
img = 'demo/test_c1.bmp' # or img = mmcv.imread(img), which will only load it once
result = inference_segmentor(model, img)
# visualize the results in a new window
model.show_result(img, result, show=True)
# or save the visualization results to image files
# you can change the opacity of the painted segmentation map in (0, 1].
model.show_result(img, result, out_file='result_hrnet.jpg', opacity=0.5)

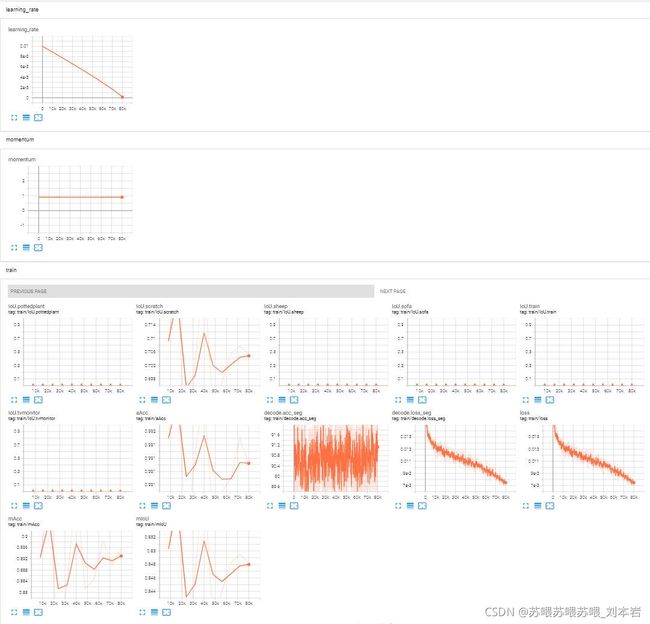
tensorboard: