朴素贝叶斯算法面试问题汇总
自己救自己系列,不然我这个渣渣就要没工作了。
我只是个木得感情的搬运机器,以下内容都附有原链接地址,你不想我搬运的话,可以联系我删除好勒。
红色加粗是我见了好多次,感觉经常会考得点。
一、朴素贝叶斯介绍
朴素贝叶斯我看的时候各种奇怪的名词晕乎乎的,后来发现主要把握住他的流程即可。
1)由数据集T, 求的先验概率 ![]() 。简单说就是每一类占所有样本比重。
。简单说就是每一类占所有样本比重。
2)求条件概率分布 ![]() 。即
。即![]() 情况下,x每个属性对应的概率。
情况下,x每个属性对应的概率。
3) 求联合概率分布 ![]() , 通过上面两式相乘即可得。
, 通过上面两式相乘即可得。
4)现在就可以预测了。给定一个X,预测其类别,通过
![]()
这时候你会发现需要的东西前三步都已经提供了,然后该式子化简,在求后验概率最大,即
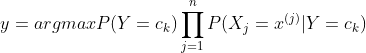
这个也很容易理解。第一项  在第一步已经有了, 后一项就是
在第一步已经有了, 后一项就是![]() 的情况下,X为每种属性x(j)的概率。
的情况下,X为每种属性x(j)的概率。
然后这四步看一下《统计学习方法》上的例题就会很清楚,下面这个链接中也有该例题。
教程依旧推荐先看《统计学系方法》,或者这位北大小天才的 https://www.pkudodo.com/2018/11/21/1-3/
推荐这个博客还是因为他讲的和《统计学习方法》很像,且有代码。
二、相关问题
1、朴素贝叶斯为什么“朴素naive”?
因为在计算条件概率分布p(X|Y)时,朴素贝叶斯做了一个很强的条件独立假设(当Y确定时,X的各个分量取值之间相互独立)
2、朴素贝叶斯属于生成式模型
与判别式模型区别是:
生成式:生成模型是先从数据中学习联合概率分布,然后利用贝叶斯公式求得特征和标签对应的条件概率分布。
包含:朴素贝叶斯、HMM、Gaussians、马尔科夫随机场
判别式:判别模型直接学习条件概率分布,直观的输入什么特征就预测可能的类别。
包含:LR,SVM,神经网络,CRF,Boosting
问题源自:https://www.nowcoder.com/ta/review-ml/review?tpId=96&tqId=32546&query=&asc=true&order=&page=115
3、朴素贝叶斯原理及推导过程
原理: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的待分类项xxx,通过学习到的模型计算后验概率分布。
说人话就是两点:贝叶斯定理、特征条件独立假设。
推导过程:简单点就是上面朴素贝叶斯介绍的内容,复杂一点参考 https://www.jianshu.com/p/b6cadf53b8b8
4、写出全概率公式&贝叶斯公式
全概率:就是表示达到某个目的,有多种方式,问达到目的的概率是多少?
全概率公式: 设事件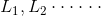 是一个完备事件组,则对于任意一个事件C,若有如下公式成立:
是一个完备事件组,则对于任意一个事件C,若有如下公式成立:

贝叶斯:当已知结果,问导致这个结果的第i原因的可能性是多少?执果索因!
贝叶斯公式: 在已知条件概率和全概率的基础上,贝叶斯公式是很容易计算的:
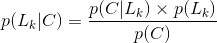
展开得:

答案抄自: https://blog.csdn.net/u010164190/article/details/81043856
问题自:https://mp.weixin.qq.com/s/5ZkwjtaVvDQmaZ6b9W3x6g
5、最大似然估计和最大后验概率的区别?
0)对 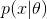 而言,若x未知,
而言,若x未知, 已知,则为概率函数, 描述对不同样本x,其出现的概率。
已知,则为概率函数, 描述对不同样本x,其出现的概率。
若x已知,未知,则为似然函数, 描述给定样本X=x的情况下,参数为真实值的可能性。
1)最大似然估计MLE。即为求一组能够使似然函数最大的参数,即
![]()
举个例子。在上文贝叶斯介绍的第1)步,需要求![]() , 此时已知数据集T中(x,y)分布,
, 此时已知数据集T中(x,y)分布,
求Y对应于每一类的先验概率,即可通过最大似然估计,得到:
![]()
2)最大后验估计MAP。当MLE中参数 服从某种先验概率时,就需要用最大后验估计。
其基础为上文提到的贝叶斯公式,
MAP优化的就是一个后验概率,即给定了观测值以后使后验概率最大:

3)更详细的MLE、MAP和贝叶斯估计间的关系查看 https://blog.csdn.net/bitcarmanlee/article/details/81417151
其他博客上的问题见:https://www.cnblogs.com/zhibei/p/9394758.html
更多你需要的
1、机器学习相关准备知识
1.0 感知机算法面试问题汇总
1.1 SVM算法面试问题汇总 (机器学习必考)
1.2 决策树算法面试问题汇总
1.3 逻辑回归(LR)算法面试问题汇总
1.4 KNN算法面试问题汇总
1.5 集成学习(bagging、boosting、GBDT)算法面试问题汇总
1.6 朴素贝叶斯算法面试问题汇总