基于朴素贝叶斯分类器的西瓜数据集 2.0 预测分类_朴素贝叶斯(转载自Morgan)...
什么是朴素贝叶斯
要搞懂朴素贝叶斯分类,首先需要了解什么是贝叶斯定理和特征条件独立假设,朴素贝叶斯算法就是基于这两个来实现的分类方法。
贝叶斯定理
贝叶斯定理通俗点讲就是求在事件 B 已经发生的前提下,事件 A 发生的概率,记为 P(A|B),被称为 A 的后验概率,也称为条件概率。
其基本公式为:

P(A)就叫做先验概率或边缘概率。
P(B|A) 就是在 事件A 发生情况下的 B 事件的概率分布,也是条件概率。
公式记不住怎么办,A 和 B 太容易混淆了。有办法,我们来推导一遍,首先 A 和 B 同时发生的概率被成为联合概率,表示为 P(AB)、P(A,B)、P(A ∩ B)。学过概率我们应该都知道,条件概率公式为:

若由两个事件推广到无穷多个事件,条件概率公式可扩展为:
取n=2, 令A2=B, 则P(AB) = P(A)P(B|A), 代入上述公式即可得到贝叶斯定理公式。
还有一个是全概率:设事件{Aj}是样本空间Ω的一个划分,且P(Ai)>0,那么对于任意事件B,全概率公式为:

我们将 上面公式也带入到贝叶斯定理中去,最终 贝叶斯公式得到:

此处休息 2 分钟
特征条件独立
搞懂了贝叶斯定理,我们再来看特征条件独立,这个就很好理解了。先从数学角度描述一下,然后再通过例子详细说明。假设有一训练集(X,Y),输入 X 记为x=(x1, x2, …, xn), 表示每个样本 x 都有 n 维特征,输出 Y 为类标记集合,记作y={y1, y2, …, yk}, 表示类标记集合有 k 种类别。如果新来一个样本 m,判断它属于 Y 的哪个类别, 转化为概率问题其实就是求解 m属于 Y 哪个类别的概率最大。在这过程中,我们假设 x 的各个特征都相互独立,这个就是特征条件独立假设,根据条件独立公式 P((A,B)|C) = P(A|C)* P(B|C)可得对应公式为:
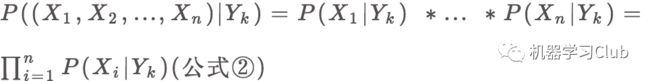
再冷静一下
现在我们有公式①和公式②,将公式②代入公式①中,可得:

因此,朴素贝叶斯分类器表达式可以转化为为:
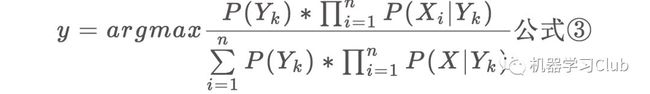
又因对于所有的样本中,公式③的分母都是一样的,朴素贝叶斯分类器表达式最终为:
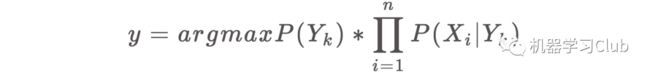
至此可以看出,分类问题其实就是数学中求最大概率的问题。
用例子学习朴素贝叶斯分类
比如 下一篇我们即将实现的垃圾短信分类器。首先大概确定一份邮件中出现哪些特征会被判定为垃圾邮件。假设有100封邮件样本,我们已经标注垃圾邮件有25封,垃圾邮件中含有“便宜”、“发票”、“乱码”等字样。根据朴素贝叶斯分类器原理,一个样本判断属于哪个类别是求最大概率问题。通过分析得到:
- P(垃圾邮件) = 0.25 (先验概率)
- P(便宜|垃圾邮件) = 10/25 = 0.4 (条件概率)
- P(发票|垃圾邮件) = 15/25 = 0.6
- P(乱码|垃圾邮件) = 20/25 = 0.8
通过朴素贝叶斯公式可得
P(垃圾邮件|(便宜,发票,乱码)) = 0.048 (后验概率)
- P(正常邮件) = 0.75
- P(便宜|正常邮件) = 5/75
- P(发票|正常邮件) = 3/75
- P(乱码|正常邮件) = 1/75
通过朴素贝叶斯公式可得
P(正常邮件|(便宜,发票,乱码)) = 1/37500
通过比较,发现 P(垃圾邮件|(便宜,发票,乱码))>P(正常邮件|(便宜,发票,乱码))。因此如果再来一份新邮件,如果出现便宜,乱码,发票字样,那么我们预测为垃圾邮件。
PS:由于在实际问题中,可能会出现某些特征条件概率为 0 的情况,并不是说不存在这种情况,而是数据样本未采集到对应的数据。针对这种情况,一般采用拉普拉斯平滑来修正,具体的用法暂时先不说明了,简单来说假设样本为 1 来避免。
最后
朴素贝叶斯假设就是对条件概率分布做了条件独立的假设,由于这是一个较强的假设,因此朴素两字也是这样来的,也正因为这个假设条件,使得朴素贝叶斯高效,而且易于实现,对应的缺点也因为假设太强,分类的性能不一定很高。
朴素贝叶斯分类其实在日常生活中我们经常会用到,比如说路上走来一个人,我们一眼就能看出它是男人还是女人,或是黄种人还是白种人。在企业中,判断信用卡诈骗,病人分类,新闻分类等都使用的是朴素贝叶斯分类。
在下一篇中,我们将运用朴素贝叶斯分类器算法来实现一个垃圾短信分类检测器,敬请期待。
原创文章,欢迎转载,转载请声明作者和出处,谢谢!
欢迎关注机器学习 Club ,在这里我将持续输出机器学习原创文章,尽量用朴实的语言带你领略技术的美妙
机器学习Club