多智能体强化学习-G2ANet
Multi-Agent Game Abstraction via Graph Attention Neural Network
论文地址
代码地址
摘要
本文通过一个完整的图来建模智能体之间的关系,并创新性地提出一种基于两阶段注意力网络(G2ANet)的游戏抽象机制,表明两个智能体之间的交互以及交互的重要性。本文将这种检测机制集成到基于图神经网络的多智能体强化学习中,以进行游戏抽象(可以理解为为了提高智能体的性能,简化学习过程而提出的与多智能体系统结构等相关的先验知识),并提出了两种新的学习算法GA-Comm和GA-AC。
相关工作
大规模的智能体数量个复杂的智能体交互对策略的学习造成影响。因此,简化学习过程是一个重要的研究。早期的研究重要是松散多智能体系统的耦合,采用游戏抽象和知识转换来加速多智能体强化学习。然而,在大规模的智能体环境中,智能体往往不是独立的,通过松散耦合将单智能体的方法应用到多智能体系统中失效。
game abstract
游戏抽象的主要思想是将多智能体强化学习(马尔可夫博弈)模型简化为一个小游戏,从而降低求解(或学习)博弈均衡策略的复杂性。
soft- attention
soft-attention计算元素的重要性分布。它是完全可微的,因此能够实现end-to-end 反向传播训练。
hard-attention
hard- attention从所有元素中选择一个子集,迫使模型只能关注重要元素,完全忽略其他元素。
方法
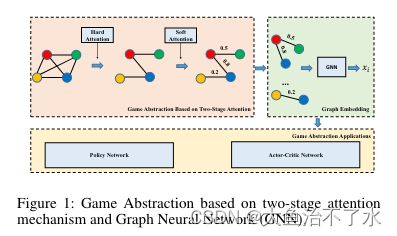
如图所示,本文提出一种基于两阶段注意力网络的图网络结构来进行游戏抽象。hard-attention用来减少无关的边(无关的智能体信息),soft-attention用来学习重要的边(相关的智能体信息),然后使用图网络获得其他智能体的信息。最后,将获得的游戏抽象与强化学习算法结合。
G2ANet:将智能体之间的关系构建为图,每个智能体为一个节点,默认情况下,所有的节点成对连接。
agent-coordination-graph:智能体之间的关系构建为一个无相图: G = ( N , E ) G=(N,E) G=(N,E),又节点集合 N N N和边集合 E E E组成,是 N N N的无序元素对。每个节点代表智能体的入口(开始),边代表两个相邻智能体之间的关系。
之前的工作大部分采用soft-attention机制获得重要性分布,包括环境中的所有智能体(与当前智能体不相关的智能体),从而削弱了真正有作用的智能体的影响。因此,G2ANet中先用hard-attention去除不相关的智能体,在用soft-attention确定相关智能体的权重分布。
部分可观测环境中,在时间步 t t t,每个智能体 i i i获得一个局部观测
o i t o_i^t oit,它包含了智能体 i i i在图 G G G中的信息。通过MLP将局部观测 o i t o_i^t oit编码为一个特征向量 h i t h_i^t hit ,然后,通过特征向量 h i t h_i^t hit 学习智能体之间的关系。hard-attention会输出一个one-hot向量,我们可以得到节点 i i i和 j j j之间的边是否存在于图 G G G中,以及每个智能体需要与哪些智能体交互。通过这种方式,策略学习被简化为几个较小的问题,并且可以实现初步的游戏抽象。
此外,图 G G G中每条边的权重不同。我们通过soft-attention学习每条边的权重。这样,我们可以得到智能体 i i i的一个子图 G i G_i Gi,智能体 i i i仅仅与需要交互的智能体相连,边的权重代表关系的重要性。可以利用GNN获得子图 G i G_i Gi的向量表示,代表其他智能体的贡献。
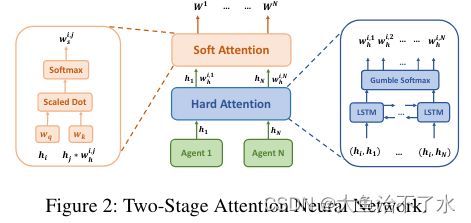
具体的,图上图所示。对于智能体 i i i,通过hard-attention机制学习到一个hard权重 W h i , j W_h^{i,j} Whi,j,决定智能体 i , j i,j i,j之间是否需要交互。利用LSTM网络输出权重(0,1).对于智能体 i i i,我们将智能体 i , j i,j i,j的嵌入向量合并为特征 ( h i , h j ) (h_i,h_j) (hi,hj),并将特征输入到LSTM模型中,这里采用了 B i − L S T M Bi-LSTM Bi−LSTM,减少输入顺序对权重的影响,考虑所有输入的影响。(传统LSTM中输出仅取决于当前时间和前一时间的输入,而忽略了后一时间的输出信息输入)
另外,由于hard-attention采用sampling过程而无法进行梯度反向传播,在这里尝试采用gumbel-softmax解决(具体可以参考gumbel-softmax):
W h i , j = g u m ( f L S T M ( h i , h j ) ) W_h^{i,j}=gum(f{LSTM(h_i,h_j)}) Whi,j=gum(fLSTM(hi,hj))
g u m ( . ) gum(.) gum(.)代表gumbel-softmax 函数。通过hard-attention,得到智能体 i i i的子图 G i G_i Gi,图中, i i i仅仅与需要协作的智能体相连。
然后,使用soft-attention学习子图 G i G_i Gi边的权重 W s i , j W_s^{i,j} Wsi,j,使用query-key(键-值对)将嵌入 e i , e j e_i,e_j ei,ej进行比较,并将这两个嵌入之间的匹配值传递到softmax函数中(这里就是采用最基础的attention机制处理,对hard-attention保留的边进行重要性权重处理)
W s i , j ∝ e x p ( e j T W k T W q e i W h i , j ) W_s^{i,j}\propto exp(e_j^TW_k^TW_qe_iW_h^{i,j}) Wsi,j∝exp(ejTWkTWqeiWhi,j)
W k W_k Wk将 e j e_j ej转化为key, W q W_q Wq将 e i e_i ei转化为query, e i , e j e_i,e_j ei,ej对应图中的 ( h i , h j ) (h_i,h_j) (hi,hj)。
基于G2ANet的策略网络
大部分通信的研究中,通过聚合函数实现通信,聚合函数可以将所有其他智能体的通信向量(例如,平均函数、最大函数)聚合为一个向量,并将其传递给每个智能体。这样,每个智能体都可以接收所有智能体的信息并实现通信。但是,在大多数环境中,智能不需要与所有其他智能体通信。频繁的通信将导致高计算成本,并增加策略学习的难度。本文提出一种GA-Comm。
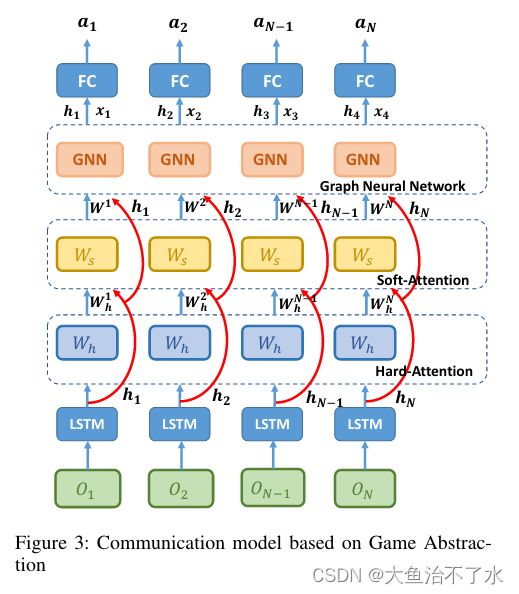
如上图, o i o_i oi代表智能体 i i i的观测,利用LSTM提取智能体的特征:
h i , s i = L S T M ( e ( o i ) , h i ′ , s i ′ ) h_i,s_i=LSTM(e(o_i),h'_i,s'_i) hi,si=LSTM(e(oi),hi′,si′)
( h i , s i ) (h_i,s_i) (hi,si)是LSTM的hidden和 cell states。关于其他智能体对智能体 i i i的贡献,我们首先使用两阶段注意机制来选择智能体 i i i需要与哪些智能体通信并获得其重要性
W h i , j = M h a r d ( h i , h j ) , W s i , j = M s o f t ( W h , h i , h j ) W_h^{i,j}=M_{hard}(h_i,h_j), \\ W_s^{i,j}=M_{soft} (W_h,h_i,h_j) Whi,j=Mhard(hi,hj),Wsi,j=Msoft(Wh,hi,hj)
最后,通过soft-attention输出的权重对邻居特征进行加权处理得到邻居信息 x i x_i xi
x i = ∑ j ≠ i w j h j = ∑ j ≠ i W h i , j W s i , j h j x_i=\sum_{j\neq i}w_jh_j=\sum_{j\neq i}W_h^{i,j}W_s^{i,j}h_j xi=j=i∑wjhj=j=i∑Whi,jWsi,jhj
最后,利用策略梯度得到每个智能体的策略,并扩展到多种RL算法中
a i = π ( h i , x i ) a_i=\pi(h_i,x_i) ai=π(hi,xi)
h i h_i hi是智能体的观测特征, x i x_i xi是其他智能体对 i i i的贡献。
基于G2ANet的AC网络
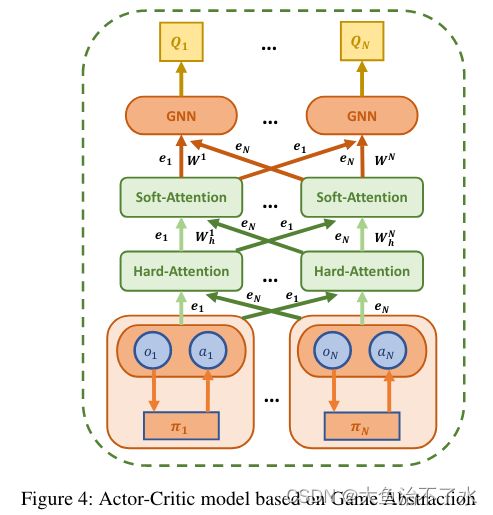
基于M AAC。主要改进是计算其他智能体的贡献权重,在G2ANet-AC中,
x i = ∑ j ≠ i w j v j = ∑ j ≠ i w j h ( V g i ( o j , a j ) ) w j = W h i , j W s i , j ∝ e x p ( h ( B i L S T M j ( e i , e j ) ) e j T W k T W q e i ) x_i=\sum_{j\neq i}w_jv_j=\sum_{j\neq i}w_jh(Vg_i(o_j,a_j))\\ w_j=W_h^{i,j}W_s^{i,j}\propto exp(h(BiLSTM_j(e_i,e_j))e_j^TW_k^TW_qe_i) xi=j=i∑wjvj=j=i∑wjh(Vgi(oj,aj))wj=Whi,jWsi,j∝exp(h(BiLSTMj(ei,ej))ejTWkTWqei)
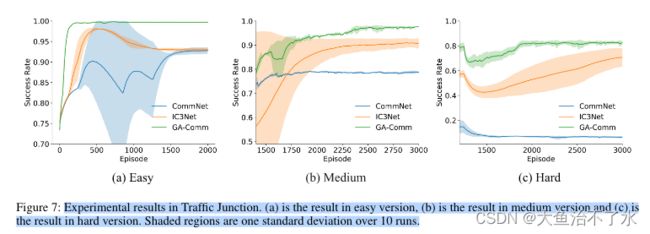
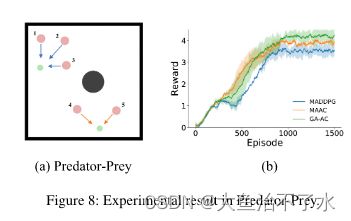
实验
在交通灯和追捕环境中进行验证