Matlab强化学习机器人仿真
Matlab强化学习机器人仿真
使用SAC(soft A-C)平衡机械手臂的球
项目来源:https://www.mathworks.com/company/events/tradeshows/international-conference-on-intelligent-robots-and-systems-2020-3039214.html?s_tid=srchtitle
基础配置
强化学习工具箱 RL Agent
Matlab2020b
Kinova Gen3 七自由度机械臂(只用最后两个关节)
机械臂基于SolidWork模型的URDF导入,在通过Simcaps MultiBody控件生成在Simulink中模型
模型各个关节坐标系以及连杆质量中心(由SW计算得到)由下图所示

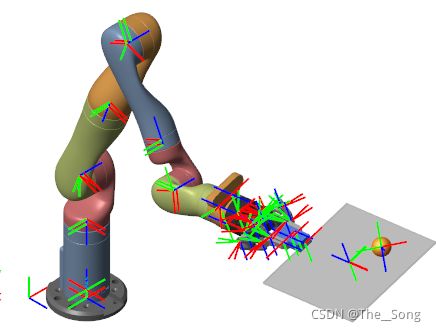
环境
从环境中观察的变量包括:两个执行关节的位置(sin、cos、关节角度),速度(关节角度微分);球的位置(距离板中心的距离x、y),速度(x、y微分);板的方向(四元数),速度(四元数微分);关节力矩;球的直径和重量。
动作:最后两个关节的规范化转矩值。
采样时间:0.01s,仿真时间:10s
仿真终止条件:球掉落
回报Reward:

创建环境:
numObs = 22; % 从环境中观察的变量个数
oinfo = rlNumericSpec([numObs 1]);% 创建观察定义(specification)
``` oinfo = rlNumericSpec - 属性: LowerLimit: -Inf UpperLimit: Inf Name: [0×0 string] Description: [0×0 string] Dimension: [22 1] DataType: "double" ```
numAct = 2; % 动作个数
ainfo = rlNumericSpec([numAct 1]);% 创建动作定义(specification)
ainfo.LowerLimit = -1;
ainfo.UpperLimit = 1;
ainfo = rlNumericSpec - 属性: LowerLimit: -1 UpperLimit: 1 Name: [0×0 string] Description: [0×0 string] Dimension: [2 1] DataType: "double"
使用动作和观察定义创建Simulink环境接口
mdl = "rlKinovaBallBalance"; %Simulink模型
blk = mdl + "/RL Agent"; %Agent block块
env = rlSimulinkEnv(mdl,blk,oinfo,ainfo); %创建环境
env = SimulinkEnvWithAgent with properties: Model : rlKinovaBallBalance AgentBlock : rlKinovaBallBalance/RL Agent ResetFcn : [] UseFastRestart : on
上面可见ResetFcn为空,训练过程中需要提供重置函数来随机生成小球在板上的落点,或是随机调整其他参数,例如球的直径和质量(可以让训练出的agent更加鲁棒)。
这里使用 kinovaResetFcn随机生成小球相对于板中心x、y距离,以及其他机械臂参数。
env.ResetFcn = @kinovaResetFcn;
指定采样和仿真时间
Ts = 0.01; % 采样时间
Tf = 10; % 仿真时间
Agents
本例使用Soft Actor-Critic (SAC) agent,two critics 学习最佳的 Q-value, two critics用于避免学习过程中 Q-function的过拟合。
actor代表基于当前观测到的变量,政策采取最佳的动作。critic 代表了评估当前政策下期望的的期望长期累积Reward。 actor和critic需要采用深度神经网络、线性基函数或查找表来表示。
为critics创建神经网络,两输入(观测、行为)一输出,网络结构建立如下:
cnet = [
featureInputLayer(numObs,'Normalization','none','Name', 'observation')
fullyConnectedLayer(128, 'Name', 'fc1')
concatenationLayer(1,2,'Name','concat')
reluLayer('Name','relu1')
fullyConnectedLayer(64, 'Name', 'fc3')
reluLayer('Name','relu2')
fullyConnectedLayer(32, 'Name', 'fc4')
reluLayer('Name','relu3')
fullyConnectedLayer(1, 'Name', 'CriticOutput')];
actionPath = [
featureInputLayer(numAct,'Normalization','none', 'Name', 'action')
fullyConnectedLayer(128, 'Name', 'fc2')];
% Connect the layer graph
criticNetwork = layerGraph(cnet);
criticNetwork = addLayers(criticNetwork, actionPath);
criticNetwork = connectLayers(criticNetwork,'fc2','concat/in2');

用神经网络表示critics
criticOptions = rlRepresentationOptions('LearnRate',1e-4,'GradientThreshold',1); %控制学习时critics网络参数
critic1 = rlQValueRepresentation(criticNetwork,oinfo,ainfo,'Observation',{'observation'},'Action',{'action'},criticOptions);
critic2 = rlQValueRepresentation(criticNetwork,oinfo,ainfo,'Observation',{'observation'},'Action',{'action'},criticOptions);%用特定神经网络表示critics
SAC Agent中的actor用 rlStochasticActorRepresentation表示,创建用于代表actor政策的深度神经网络
anet = [
featureInputLayer(numObs, 'Normalization', 'none', 'Name', 'observation')
fullyConnectedLayer(128, 'Name', 'fc1')
reluLayer('Name', 'relu1')
fullyConnectedLayer(64, 'Name', 'fc2')
reluLayer('Name', 'relu2')];
meanPath = [
fullyConnectedLayer(32, 'Name', 'meanFC')
reluLayer('Name', 'relu3')
fullyConnectedLayer(numAct, 'Name', 'mean')];
stdPath = [
fullyConnectedLayer(numAct, 'Name', 'stdFC')
reluLayer('Name', 'relu4')
softplusLayer('Name', 'std')];
concatPath = concatenationLayer(1,2,'Name','actionProbParam');
actorNetwork = layerGraph(anet);
actorNetwork = addLayers(actorNetwork, meanPath);
actorNetwork = addLayers(actorNetwork, stdPath);
actorNetwork = addLayers(actorNetwork, concatPath);
actorNetwork = connectLayers(actorNetwork,'relu2','meanFC/in');
actorNetwork = connectLayers(actorNetwork,'relu2','stdFC/in');
actorNetwork = connectLayers(actorNetwork,'mean','actionProbParam/in1');
actorNetwork = connectLayers(actorNetwork,'std','actionProbParam/in2');

创建actor表示
actorOptions = rlRepresentationOptions('LearnRate',1e-4,'GradientThreshold',1);
actor = rlStochasticActorRepresentation(actorNetwork, oinfo, ainfo, 'Observation', 'observation', actorOptions); % 用特定神经网络表示actor
指定Agent的超参数
agentOpts = rlSACAgentOptions(...
'SampleTime',Ts,...
'TargetSmoothFactor',1e-3,...
'ExperienceBufferLength',1e6,... %经验池最大容量
'MiniBatchSize',128,... %从经验池中随机选择的最小批次
'NumWarmStartSteps',1000,...
'DiscountFactor',0.99); %系数0.99倾向于获取长期Reward
最后创建SAC Agent
agent = rlSACAgent(actor,[critic1,critic2],agentOpts);
训练
训练设置rlTrainingOptions
trainOpts = rlTrainingOptions(...
'MaxEpisodes',5000,... %最大轮次
'MaxStepsPerEpisode',floor(Tf/Ts),... %每轮最大步长
'ScoreAveragingWindowLength',100,... %在100个连续轮次中超过均值停止训练
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',675);
doTraining = true; %开始训练
if doTraining
stats = train(agent,env,trainOpts);
else
load('kinovaBallBalanceAgent.mat')
end
训练刚开始:小球非常容易掉下板子从而导致单次训练终止,且Reward平均值为负,如下图


训练1500个轮次左右时,此时Reward显著提高,小球能够更稳地在板子上,此时Reward信息如下

在2300多轮次时,平均Reward达到675以上,训练完成,历时387分钟

训练好的agent在给定小球一个位置时,机械臂能够快速将小球稳定到(0,0)附近的位置。

尝试更改球的参数,例如直径、质量、掉落高度等,由于关节的最大力矩有限制,经过多次测试对于质量小于0.03kg,下落高度小于0.3m的小球,系统有较好的鲁棒性,但是稳定小球的时间增加。

此时Agent做出的动作(最后两关节力矩)并不连续。

对于真实环境下能否适用此Agent有很大疑问。
更改机器人模型
将机器人倒数第三个关节加入Agent中进行训练,主要更改simulink模型,机械臂参数以及kinovaResetFcn。
训练结果如下:

多加入一个关节使得问题更加复杂,训练轮次和时间都增加,2600个轮次和577分钟。