自然语言处理与企业对话系统设计
原创:晏茜
资料来源:李俊
本文分享的主题分为两个部分,第一部分内容是关于企业级对话系统的简介,第二部分探讨对话系统和自然语言处理技术结合的领域。
1. 企业对话系统

我们首先来介绍一下企业级对话系统。谷歌的 CEO 桑达尔在 16 年曾发表言论,人工智能将通过各式各样的智能助手来改变我们的生活方式。现在,智能助手切实存在于日常生活的方方面面。举个简单的例子,以前,我们在获取城市的交通拥堵的情况最主要的方式是我们的交通广播,而现在我们可以通过各式各样的 APP 准确的获取所在城市的实时交通情况,这是属于智能助手的具体应用。
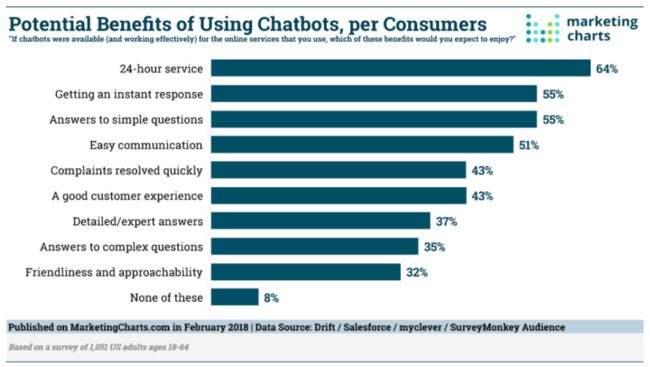
在当前自然语言处理和人工智能技术取得重大进步的前提下,Chatbot 机器人是比较有意义的。艾瑞咨询的研究报告显示,对用户而言,他们对于 Chatbot 的关注点中,排在第一位的是 24 小时的服务。不管各行各业,如果他的电话服务中心(call center)全部采用人力去维护或者提供 24 小时的服务,其实对他的成本消耗是非常大的。而如果我们的机器人足够智能化,它就可以代替人力提供 24 小时的服务,从而降低了成本。从这个角度来讲,它产生的收益是显而易见的,也是符合消费者当前的预期或消费者对于交互的需求的。
消费者对于 Chatbot 机器人的能力要求中,排在第二位的是及时的回复,排在第三的是能够直接回答一些比较简单的问题,排在第四的是比较友好的或比较容易的沟通,排在第五的是能快速的处理一些投诉,排在第六的是优质的客户体验。
从这些角度可以反观到,我们在构建 Chatbot 机器人的时候,应该从哪些方面进行提升?

据 2021 年第一季度发布的数据统计,63% 的顾客能够接受线上沟通的方式,也就是说,63% 的顾客愿意和机器人进行沟通。大概有 80% 的公司,愿意使用 Chatbot 机器人。大概有 50% 的企业,愿意在他们的用于 APP 开发的成本中,增加对于 Chatbot 的研发投入。如果我们开发的 Chatbot 机器人足够优质,那么,它带来的对于整个行业或者整个技术环境的人力成本的缩减将可达到 80 亿美元的数额。
这组数据足以说明,Chatbot 在未来是比较有发展前景的。近年来,很多自媒体都在唱衰人工智能的落地,但是如果我们仔细去了解这个行业,或者说去了解一些企业的业务情况和需求的时候,我们可以发现其实整个人工智能的落地,特别是我们今天要讨论的自然语言处理的推荐和对话,在我们日常的工作环境中其实是有很多的应用场景的。而且推荐这种表现形式也是可以放在对话环境里面去做的。所以,对话系统是整个 AI,特别是自然语言处理落地的非常典型的场景。
对话系统的类别

对话系统到底是怎样分类的呢?一般而言,我们可以从两个维度划分,一个是从任务的类型,另一个是从应用的领域进行划分。如果从任务的类型进行划分,我们可以将对话系统分成任务型和 QA 型,以及闲聊型。闲聊型一般不会有上下文的联系,单轮即可实现,QA 型一般是可以一次性解决的交互,比如顾客想询问怎么退货,或者怎么办信用卡,任务型一般会涉及到多轮的交互,比如我想定一个闹钟,那么我告诉我的智能助手或者机器人我的诉求,它会反过来问你,你想定哪一个时间。第二个维度是按照应用的领域来划分,也可以分为两类,一是开放域,开放域也就是没有特定的应用场景。第二个是垂直领域,比如电商领域中负责婴儿产品的机器人,负责金融领域的机器人,负责交通的机器人等等。

举两个例子,第一个例子是京东的机器人,第二个是智能助手。许多公司都有自己的 OA 系统。OA 系统一般以弹窗的形式存在,点击会弹出一个对话界面,在对话界面可以问一些常见的问题,比如,怎么报销,出差补助怎样计算等一类问题。相对来说,这种对话机器人是比较容易实现的,它集成了任务型和 QA 型的对话能力,比如,如何补签到这种通过一轮交互就可以直接给出答案的 QA 型,还有订机票的任务型对话的应用场景,比如我们想订机票,机器人可能会反问你,你想订机票的日期和时间,某些公司还有专门的订票系统,当你输入订机票的指令时,它并不会返回答案,而是直接返回一个菜单,你可以通过点击菜单,链接到公司的订票系统进行机票的预定。

上图演示了基于知识图谱的 QA 型对话系统,图中姚明这一节点有很多的属性,比如他和王治郅是队友,他是上海交大经济与管理学院毕业的学生,他的出生年月日,他的身高,他曾为哪个 NBA 球队效力等。作者已将该知识图谱作为免费开源使用的资源,我们可以通过这种图形化的界面去访问,也可以调免费提供的 API,访问地址如下:
https://www.ownthink.com/knowledge.html
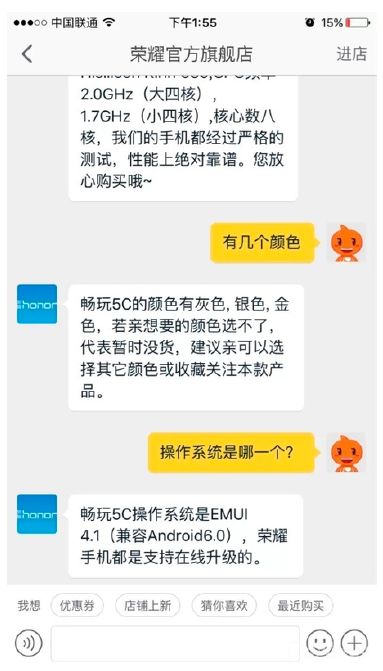
以上对话进一步展示了 QA 型对话系统的应用场景。

KB-QA 是基于知识库的问答。KB 即 Knowledge Base,是指知识库是以表单的形式来做存储的。KG 即Knowledge Graph,上图所示的图谱就属于 Knowledge Graph 的存储方式。无论哪种方式,只要你的后端都是以结构化后的数据作为引擎,或者引擎的一部分的,你都可以把它叫做 KB-QA。
Text-QA 是指给你一篇文章,再给你一个问题,这个问题往往是基于这篇文章来问的,那么你的答案就是根据这篇文章得到的答案。你的答案要么是从文章里面去截取的,要么就是你希望算法能理解这篇文章,然后再去做文本的生成,这是两种不同处理的技术方向。那么如果它是提取的,我们就可以采用抽取式的算法来实现,如果它是生成的,我们可以采用 NLG(自然语言生成)的一些技术来实现它。
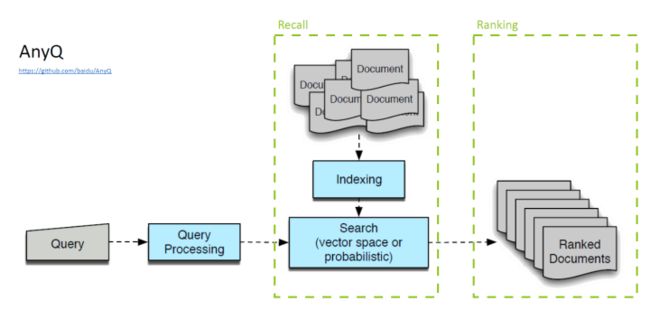
AnyQ 是百度开源的问答系统框架。AnyQ 的基本的框架来自于上图。这个架构分成两级,分别叫做粗排和精排,也可以叫做召回层和排序层。
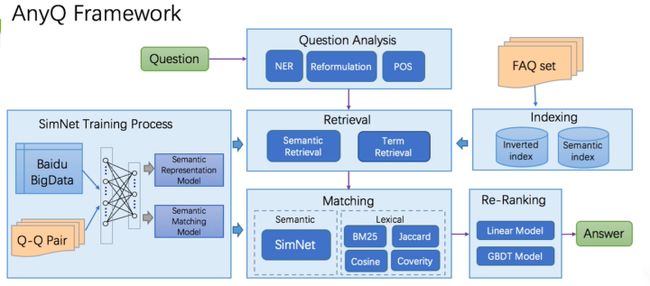
上图展示了 AnyQ 框架的每一个子模块所包含的功能块。
当我们的问题出现之后,需要经过问题的分析与处理,那么分析与处理包括哪些内容呢?比如词性标注、NER 等,然后再进入检索层,那么检索层怎样来实现检索呢?有两个方面,右边是 FAQ 的 query 对去做最基本的检索,左边有孪生网络来训练的判断句子相似度的工具,也可以帮你去做检索。Matching 层,也就是精排的这一层,也是基于语义的孪生网络,可以通过不同的语义相似度,比如 BM25、余弦相似度,最终返回你的答案。这是 AnyQ 的最基本的一个流程。这一套流程其实可以复用到很多的场景里面。
阅读理解是在工业领域和我们的工作中应用最少的,因为它对于训练数据的要求太高了,可能在一些自然语言处理的比赛中会经常有阅读理解的场景,但是,当你真正走入工作岗位中,很少或几乎没有哪个公司想要在他的生产环境中使用阅读理解算法。阅读理解算法的可控性差,它的使用很可能会给企业带来一些法律上或业务上的风险,所以很多公司都不太愿意把这样的不成熟的技术放在他的生产环境中。阅读理解算法也是一个研究的重点或难点。因为构建一个机器人最理想的状态是它能够像人一样,我们给它一篇文章,它能够理解这篇文章,并做出对应的回复,这是我们整个人工智能或者说计算机科学的比较高的目标了。做学术的同学可以更多地去关注阅读理解算法的领域。当然,阅读理解算法在工业领域或我们的工作岗位上也并不是完全不可用的,我们也可以换个角度去使用它,比如,我们在去做检索或推荐的时候其实是可以使用的。举个例子,我们开发一个写作助手,或者写作提示,如果我输入了一段话,接下来该说什么,写作助手可以根据前文的这些输入,然后结合阅读理解算法生成一些候选的文本提供给用户选择。这样的方式丰富了它的应用的场景。
2. Chatbot 与自然语言处理的结合点
第二部分的内容会讨论 Chatbot 和自然语言处理技术的结合点。
一个好的机器人应该具备哪些自然语言处理的技术呢?它应具备像人一样去理解我们的问题的能力,同时它也应当具备可扩展的能力,也就是说,当你在训练的时候,你给它的可能是比较标准的数据,但是当用户的语言发生改变,这个时候它应该也能比较灵活的去处理这样的变化。所以,这其实就要求机器人的自然语言理解模块必须具备一定的泛化能力。
我们一般理解的机器人的终端都是通过文字输入的方式,而其实也有很多场景是通过语音的交互来实现的,也就是说我们先要做预案,然后通过语音识别解析成文字,得到文字之后,我们再通过一些工具把它转成语音,这种应用主要是针对一些中老年的用户人群。
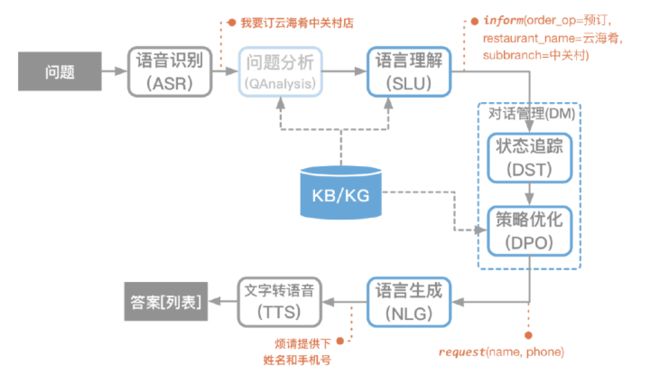
以上流程图展示了语音交互的的过程。从语义的解析,到自然语言理解部分,再到对话管理模块,然后对话管理模块再指导语言生成,最后从语言转成录音。
首先问题出现,通过 ASR 也就是语音识别技术得到文字“我要定云海肴中关村店”,通过问题的分析和自然语言理解,我们能得到说话人的意图是预定饭店,地址在中关村,以及餐馆的名字是云海肴,我们首先要定一些槽位,槽位怎么理解呢?就是你除了告诉机器人餐厅的地点和名字,还要告诉机器人有多少人就餐,什么时间来用餐,你的联系电话是多少,在这里槽位至少是这五个必备信息。当我们输入了“我要定云海肴中关村店”这句话,我们的意图已经可以被判别到了,还告诉了机器人饭店的名字,还有地点,那么用餐的时间,你的电话号码以及用餐的人数是多少,这三个信息还没有。这个时候就要靠我们的对话管理模块,当我们的的这些槽位没有填充的时候,机器人就会不断的去询问你,你的电话号码是多少,有多少人用餐,以及用餐的时间。当我们把所有的槽位都填充好了之后,就可以执行我们的action了。这个action可以采用语言生成的方式去生成答案,也可以采用模板的方式来申请答案,再通过文字转语音,获取答案列表。这是整个语音交互全流程的实例。
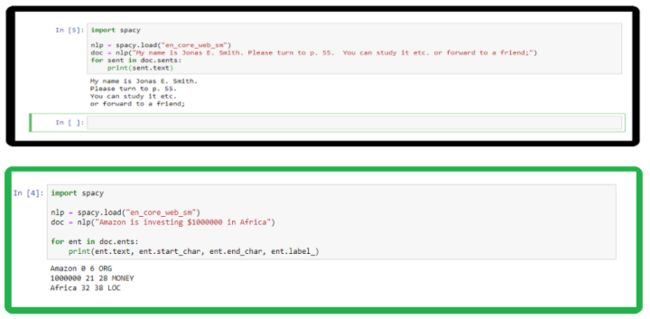
此处贴取了两段代码。首先导入 spacy 这个包,然后再去做分句,你输入了一段话,它可以自动的去提取一些实体,比如这里输入“Amazon is investing $1,000,000 in Africa”,亚马逊在非洲投资了 100 万美元,这里机构名是亚马逊,投入的金额是 100 万美金,地点是非洲,机器人比较完备的把这些信息提取出来,这就是实体提取的过程。我们可以把实体的提取作为自然语言理解中的槽位的提取,也就是 NER 的技术。当然,在中文领域,也有一些这样的工具,比如哈工大开源的一个组件LTP也能实现这样一些最基本的功能。
这里给大家补充一下模板的知识。只要做过这方面的工作,你就会发现规则是比当前任何模型在大部分场景都更有效的。那么模板的方式怎样来实现呢?其实这个问题可以作为一个开放的问题,因为模板的实现方式是多种多样的。
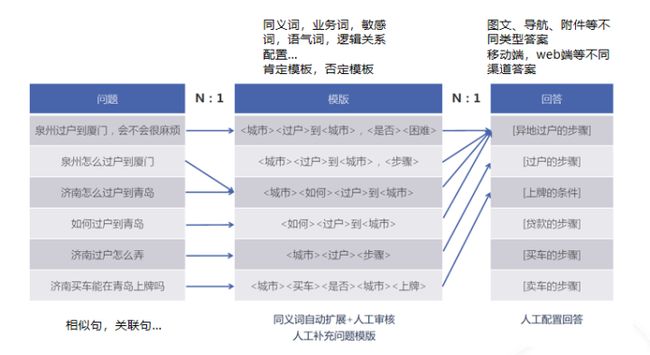
举例来说,此处的模板是按照关键词来实现的,假设语句中出现了关键词,那么我们就可以把它匹配上,假设没有出现这些关键词,那么就相当于没有匹配上,我们的分数就会很少。那么都出现了关键词的情况下,我们如何来突出它们的相关性呢?除了把模板中的内容提取出来,其余的辅助词可以帮助我们做对应的减分。假如我们的模板语句是“我喜欢吃火锅”,一名用户输入了“我喜欢吃火锅”,而另一名用户输入了“我喜欢吃广州的火锅”,那么“我喜欢吃火锅”对比“我喜欢吃广州的火锅”,很明显前者与我们问题库中的语句是更相近的,也可以说是一模一样的。那么如果我们的模板只配了“我喜欢吃火锅”,你就会发现“我喜欢吃火锅”和“我喜欢吃广州的火锅”两句话都是可以完全匹配上的,但是很明显“我喜欢吃广州的火锅”是有文字的冗余的,它输入了更多的无效的信息。这个时候我们可以基于模板进行设计,首先从模板里面提取出关键词,然后针对剩余的辅助词去做相应的减分,每多出现了一个词,我们就减去0.1分,那么这个时候我们就会发现,基于以上逻辑,“我喜欢吃火锅”的分数会比“我喜欢吃广州的火锅”的分数高,那么在精排的时候,我们就可以把“我喜欢吃火锅”排在前面,这就是一个简单的模板匹配的使用场景。
在模板的关键词中我们还要考虑一些同义词,我们可以在关键词里面去维护我们的同义词,这样在模板中去引用关键词的时候,它可以自动的去映射它的同义词关系,这个时候就可以解决这样一类的问题。同样,我们还可以在问题构建的时候去维护它的一些相似问题和关联问题。
Chatbot 有一定的局限性,比如,冷启动问题,不能像人一样灵活,或者在一个任务中,它跳出了另一个任务。当前,我们的 Chatbot 比较难去解决这些比较复杂的场景,但是大部分的场景,比如一般的 QA 或者说一般的资讯类任务,我们的自然语言处理技术或者 Chatbot 机器人在这些场景上的技术还是比较成熟的。
以上是关于自然语言处理与企业对话系统设计的相关内容,欢迎批评指正。