DANet中的Position和Channel Attention Module个人经验整理
文章目录
-
-
- DANet中的Position Attention Module
- DAN中的Channel Attetnion Module
- nn.Softmax(dim=-1)的理解
- torch.bmm的理解
-
工作参考借鉴了Dual Attention Network for Scene Segmentation中的Position Attention Module(PAM)空间位置注意力模块和Channel Attention Module(CAM)通道注意力模块。
arXiv: 点这里
official code: 点这里
模型code: 点这里
在学习和使用中一些疑惑和找到的相应解答整理如下。
文章中,两个模块的详情示意图
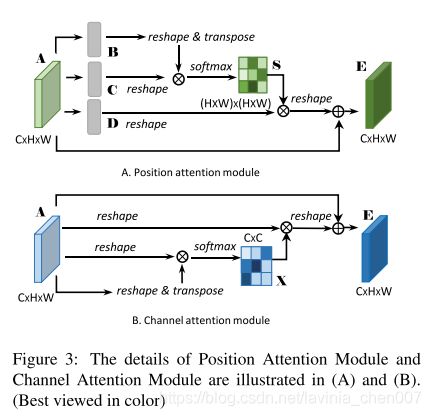
文章中,对Channel Attention Module中有这样一段
Noted that we do not employ convolution layers to embed features before computing relationshoips of two chan nels, since it can maintain relationship between different channel maps.
在下面的Code中可以特别注意一下PAM和CAM实现的不同之处。
关于两个模块最终的output,文章中表示是通过以下方式产生:
PAM: E j = α ∑ i = 1 N ( s j i D i ) + A j E_j = \alpha\sum_{i=1}^N(s_{ji}D_i) + A_j Ej=α∑i=1N(sjiDi)+Aj
CAM: E j = β ∑ i = 1 C ( x j i A i ) + A j E_j = \beta\sum_{i=1}^C(x_{ji}A_i) + A_j Ej=β∑i=1C(xjiAi)+Aj
其中, α \alpha α和 β \beta β 文中表示为
is initialized as 0 and gradually learns to assign more weight
此处在读文章的时候,不知道该如何实现,后来看了Code豁然开朗。
DANet中的Position Attention Module
class PAM_Module(nn.Module):
"""Position attention module"""
# Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.channel_in = in_dim
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8,kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8,kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim,kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1)) #注意此处对$\alpha$是如何初始化和使用的
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs:
x : input feature maps
returns:
out:attention value + input feature
attention: B * (H*W) * (H*W)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0,2,1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query,proj_key)
attetion = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value,attention.permute(0,2,1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
DAN中的Channel Attetnion Module
class CAM_Module(nn.Module):
"""Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.channel_in = in_dim
# CAM和PAM相比是没有Conv2d层的
self.gamma = nn.Parameter(torch.zeros(1)) #注意此处对$\beta$是如何初始化和使用的
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
inputs:
x : input feature maps
returns:
out:attention value + input feature
attention: B * C * C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize,C,-1).permute(0,2,1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, heigh, width)
out = self.gamma*out + x
return out
nn.Softmax(dim=-1)的理解
在看Code时,第一个遇到的不理解之处就是softmax中的dim=-1。之前在使用的过程中,有遇到过dim=0或者1,第一次遇到dim=负数。搜索了一下,以下解读是我看下来最清晰易懂的
pytorch中tf.nn.functional.softmax(x,dim = -1)对参数dim的理解
torch.bmm的理解
第二个不理解的地方是torch.bmm,也是网上搜索了一下相关的理解,把我觉得最佳的解读贴在此处便于参考。
torch.bmm() 与 torch.matmul()
torch.bmm()函数解读