计算机视觉中的注意力模块———CBAM
CBAM: Convolutional Block Attention Module
本篇文章录用于ECCV2018:CBAM:卷积块注意模块
论文地址:https://arxiv.org/pdf/1807.06521.pdf
非官方代码实现:https://github.com/Youngkl0726/Convolutional-Block-Attention-Module/blob/master/CBAMNet.py
摘要:
本文提出了卷积attention模块,一种简单而有效的前馈卷积神经网络attention模块。给定一个中间特征映射,我们的模块沿着channel和spatial这两个不同的维度按顺序输入attention映射,然后将attention映射乘以输入特征映射以进行自适应特征细化。因为CBAM是一个轻量级的通用模块,所以它可以无缝地集成到任何CNN架构中,具有可以忽略不计的开销,并且可以与基本的CNN一起进行端到端训练。我们通过对ImageNet-1K分类数据集、MSCOCO和VOC2007检测数据集的广泛实验验证了我们的CBAM。我们的实验表明,对不同模型的分类和检测性能的一致改进,证明了CBAM的广泛适用性。
Contribution
作者说明这篇文章中主要有以下三个贡献:
- 提出了一个有效的attention模块CBAM,可以有效的提高CNN的表达能力;
- 通过广泛的消融研究来验证attention模块的有效性;
- 通过引入我们的轻量级CBAM模块,验证了各种网络的性能,在多个基准(Image Net-1K、MSCOCO和VOC2007)上性能有了很大的提高。
Attention mechanism
这里总结了2017年发表的3篇论文
- Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X.,
Tang, X.: Residual attention network for image classification. arXiv preprint
arXiv:1704.06904 (2017) - Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. arXiv preprint
arXiv:1709.01507 (2017) - Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Chua, T.S.: Sca-cnn: Spatial and
channel-wise attention in convolutional networks for image captioning. In: Proc.
of Computer Vision and Pattern Recognition (CVPR). (2017)
CBMA模块


用Pytorch代码表示:
import torch
import torch.nn as nn
class CBAM_Module(nn.Module):
def __init__(self, channels, reduction):
super(CBAM_Module, self).__init__()
# 定义全局avg池化,输出的通道数output_size = 1,即输出channel = 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 定义全局max池化。输出的通道数output_size = 1,即输出channel = 1
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 定义两层的感知机MLP,中间含有一个线性激活函数relu
# reduction表示的是压缩feature map通道的倍数
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1,
padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1,
padding=0)
# 线性激活sigmod得到最后的通道注意力
self.sigmoid_channel = nn.Sigmoid()
## 压缩通道数
self.conv_after_concat = nn.Conv2d(2,1,kernel_size=3,stride=1,padding=1)
self.sigmoid_spatial = nn.Sigmoid()
def forward(self, x): # exsample x.size() = [8,128,64,64]
# Channel attention module
module_input = x
# avg全局池化+MLP
avg = self.avg_pool(x) # [8,128,1,1]
avg = self.fc1(avg) # reduction= 16 [8,8,1,1]
avg = self.relu(avg) # [8,8,1,1]
avg = self.fc2(avg) # [8,128,1,1]
# max全局池化+MLP
mx = self.max_pool(x) # [8,128,1,1]
mx = self.fc1(mx) # reduction= 16 [8,8,1,1]
mx = self.relu(mx) # [8,8,1,1]
mx = self.fc2(mx) # [8,128,1,1]
# 元素加法
x = avg + mx
## 线性激活
x = self.sigmoid_channel(x)
# Spatial attention module
# module_input表示输入特征图,x表示根据channel attention模块得到的channel-refined 特征图
x = module_input * x
module_input = x
## avg pool 不是全局的,调用torch.mean
avg = torch.mean(x, 1, True)
## max pool 不是全局的,调用torch.max
mx, _ = torch.max(x, 1, True)
# 在dim=1 上进行拼接
x = torch.cat((avg, mx), 1)
# 压缩通道数
x = self.conv_after_concat(x)
# sigmod激活
x = self.sigmoid_spatial(x)
# 对于输入的特征图*
x = module_input * x
return x
"""
x = torch.Tensor(8,128,64,64)
mb = CBAM_Module(channels = 128, reduction = 16)
print(x.size())
print(mb(x).size())
"""
这里总结一下,对于一个中间特征输入F,channel attention模块通过Mc变换得到通道注意力,spatial attention模块通过Ms变换得到空间注意力。
对于输入的特征图F,Mc(F)*F之后得到的特征图F’再进行Mc(F’)*F’,
这里的*表示的是矩阵元素乘法element wise。

channel attention模块
对于输入的特征图,通过全局maxpool和全局avgpool获得通道注意力一维向量,然后经过一个共享的感知机MLP得到各自的一位向量后进行元素加法,并通过sigmod激活得到空间注意力向量。
用数学公式表示:

spatial attention模块
利用特征的空间间关系,生成了一个空间注意图。与通道注意力不同,空间注意力关注于“在哪里”是一个信息丰富的部分,这是对通道注意力的补充。为了计算空间注意力问题,首先根据channel attention模块得到的channel-refined 特征图 沿着信道轴应用avg pool操作和max pool池操作,并将它们连接起来,以生成一个有效的特征描述符。沿着信道轴应用pooling操作在突出显示信息区域[33]方面是有效的。在被连接的特征描述符上,我们应用了一个卷积层去生成空间注意特征图。
用Pytorch代码表示如上
数学公式表示:

将CBAM模块插入到ResNet block中去

Experiments
顶会论文在实验部分往往非常精彩。
首先是消融实验验证有效性
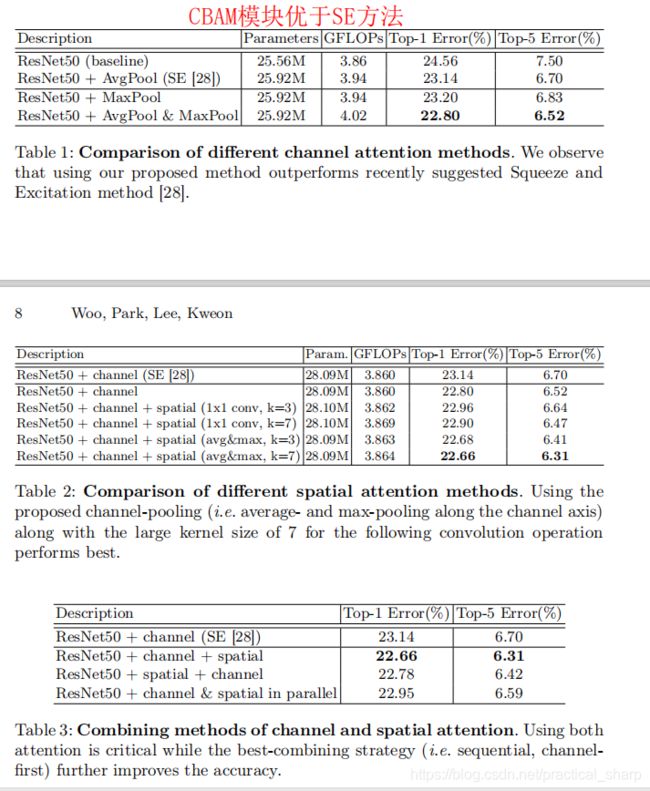
表3说明了先进行channel attention再进行spatial attention的效果优于后者。
结果中,我们可以发现,生成一个注意图顺序地注入一个比并行处理更精细的注意图。 此外,信道优先级的性能略优于空间优先级
这里描述一下我感兴趣的目标检测部分,通过将CBAM模块加入ResNet50backbone用来改进Faster RCNN和SSD算法,在COCO数据集上面提升比较精彩。

接下来笔者就得好好理解RetNet50+CBAM模块的代码了,
这里推荐一个:
https://github.com/luuuyi/CBAM.PyTorch
import torch
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
## 通道注意力模块
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
## 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out
out = self.sa(out) * out
if self.downsample is not None:
residual = self.downsample(x)
# 计算注意力修正矩阵
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.ca = ChannelAttention(planes * 4)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
# 计算注意力修正矩阵
out = self.ca(out) * out
out = self.sa(out) * out
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 分类网络 最后连接全连接层输出
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50_cbam(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
pretrained_state_dict = model_zoo.load_url(model_urls['resnet50'])
now_state_dict = model.state_dict()
now_state_dict.update(pretrained_state_dict)
model.load_state_dict(now_state_dict)
return model
只读一遍太可惜了,不用手动敲一个用来做MNIST手写数字图像分类
博客链接:https://blog.csdn.net/practical_sharp/article/details/114699526