数字图像处理-美图秀秀:瘦脸算法
简介
本项目是以matlab为主语言并设计GUI界面的一款简易美图秀秀,包含基础的图像处理和一些常见美颜算法
对于一些matlab较难实现的算法采用C++或python来实现
⭐️ github地址:https://github.com/mibbp/MeituShow
里面有我完整的代码,你想直接运行记得看readme配置一下环境,本博客更多的是讲解原理
具体功能包括:
- 增加图像亮度,对比度
- 美白人像
- 采用双边滤波算法磨皮
- 采用液化算法并用dlib提取特征点实现瘦脸
- 基于液化算法并用dlib提取特征点实现大眼
- 采用dlib提取特征点,采用Andrew求凸包并用BFS实现唇彩
- 采用SRCNN超分辨率算法实现提升照片像素
- 采用Beauty-GAN算法实现彩妆迁移
测试照片均来源于网络如有侵权请私聊作者删除
瘦脸算法
这一块我是用python写的主要是matlab没有找到比较好的提取特征点的模型,如果提取特征点不精确很多算法效果都不会很好,所以改用python去写,C++也可以写效果比python好,但是matlab调用python要更简单一些,c++的生成mex文件才行还得按照他的规则来写
瘦脸算法本质上就是人脸图像变形算法,人脸图像变形技术主要有两个比较关键的,一个是空间映射,另一个就是重采样技术,空间映射又分为前向映射和后向映射,我们采用的使后向映射一般都是后向映射,因为后向映射变形后的图像能稳定、平滑地过渡变化,并得到良好的渐变效果,满足人的视觉感官体验。
matlab调用python
建议网上搜相关教程,这里贴一个官方教程
工具和环境安装准备
-
python3
-
CMake
-
Dlib
-
opencv
python最好3.6以上吧,我使用的是3.8,想安装Dlib的先安装CMake等一些其他包,直接网上搜教程然后跟着做就好了,配环境如果是新手的话肯定是比较折磨的
人脸特征点
人脸特征主要应具有普遍性(人人拥有)、唯一性(人人不同)、稳定性(不因时间、年龄、环境的变化而变化)和采集方便性(应釆集容易、设备简单、对人影响程度小)等特点。比如人脸轮廓,五官那些
人脸检测
我们实际使用的训练好的模型提取特征点,但这里还是大概讲一下算法原理
想提取人脸特征首先的检测到人脸才行,检测人脸我应该在上课时候讲了一下,这里就懒得打字了,建议直接看论文
基于Harr特征
Harr-like特征是Viola等提出的一种简单矩形特征,因其类似于Harr小波而得名,脸部的一些特征可以由矩形特征简单的描绘,如下图示范:

上图中两个矩形特征,表示出人脸的某些特征。比如中间一幅表示眼睛区域的颜色比脸颊区域的颜色深,右边一幅表示鼻梁两侧比鼻梁的颜色要深
矩形特征对一些简单的图形结构,比如边缘、线段,比较敏感,但是其只能描述特定走向(水平、垂直、对角)的结构,因此比较粗略。如上图,脸部一些特征能够由矩形特征简单地描绘,例如,通常眼睛要比脸颊颜色更深;鼻梁两侧要比鼻梁颜色要深;嘴巴要比周围颜色更深。
对于一个 24×24 检测器,其内的矩形特征数量超过160,000个,必须通过特定算法甄选合适的矩形特征,并将其组合成强分类器才能检测人脸。
常用的矩形特征有三种:两矩形特征、三矩形特征、四矩形特征,如图:

特征值计算
特征矩阵的特征值就是白色区域像素值减去黑色区域像素值,因为矩阵数量很多,所以需要一个能够快速计算矩阵区间和的算法也就是二维前缀和算法,这玩意很简单网上一搜就会,就是求出 s u m ( x , y ) sum(x,y) sum(x,y), s u m ( x , y ) sum(x,y) sum(x,y)的意思就是以图形左上角 ( 0 , 0 ) (0,0) (0,0)为矩阵左上顶点, x , y x,y x,y为右下顶点,计算除该矩阵的像素和,只需 O ( N M ) O(NM) O(NM)的时间复杂度就可以预处理出来
然后查询的时间复杂度是 O ( 1 ) O(1) O(1)的,如下图所示我们相求X矩阵的像素值

因为绿色、紫色、红色、蓝色矩阵都已经求出来了所以直接绿色减去蓝色和紫色然后再加上重复相减的红色区域就是X矩阵的像素值
Adaboost训练人脸检测模型
刚刚说了我们需要得到一个好的特征矩阵来提取特征,但是我们不知道那个好,那我们就找到所有的特征矩阵然后训练找到那个比较好的
这个算法原理其实就是三个臭皮匠,顶个诸葛亮,我上课应该也做了演示,这里简单说一下流程就是先来一个弱分类器,可以很垃圾甚至你写给随机给值都行(就是这样工作量会变大所以一般都是会选个最优弱分类器),然后对他初始赋权都一样然后进行初步训练,训练后可能有些表现得很好有些不好,然后就调整权重,把那些效果不好的权重拉高然后降低好的生成第二个模型,然后再根据结果调整权重,最后把所有训练得结果分配权重整合起来就变成了强分类器
弱分类器的训练和选取
以20*20图像为例,78,460个特征,如果直接利用AdaBoost训练,那么工作量是极其极其巨大的。
所以必须有个筛选的过程,筛选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost进行训练。
现在有人脸样本2000张,非人脸样本4000张,这些样本都经过了归一化,大小都是20x20的图像。那么,对于78,460中的任一特征 f i f_i fi,我们计算该特征在这2000人脸样本、4000非人脸样本上的值,这样就得到6000个特征值。将这些特征值排序,然后选取一个最佳的特征值,在该特征值下,对于特征 f i f_i fi来说,样本的加权错误率最低。
弱分类器训练过程大致为以下几步
-
对每个特征,计算所有训练样本的特征值
-
将特征值排序
-
排完序后遍历对每个元素计算
- 全部正例权重和记为 T + T^+ T+
- 全部负例权重和记为 T − T^- T−
- 该元素前正例权重和记为 S + S^+ S+
- 该元素前负例权重和记为 S − S^- S−
-
选取当前元素的特征值 和它前面的一个特征值之间的数作为阈值,所得到的弱分类器就在当前元素处把样本分开 —— 也就是说这个阈值对应的弱分类器将当前元素前的所有元素分为人脸(或非人脸),而把当前元素后(含)的所有元素分为非人脸(或人脸)。该阈值的分类误差为:
e = m i n ( S + + ( T − − S − ) , S − + ( T + − S + ) ) e = min(S^+ + (T^--S^-),S^-+(T^+-S^+)) e=min(S++(T−−S−),S−+(T+−S+))
正列就是正样本,可以理解为正值,就我们会为每个点分配一个权重,分配正确的为正数,错误的是负数,比如人脸就是正样本,非人脸就是负样本
由于一共有78,460个特征、因此会得到78,460个最优弱分类器,在78,460个特征中,我们选取错误率最低的特征,用来判断人脸,同时用此分类器对样本进行分类,并更新样本的权重。
有一个非常经典的例子就是
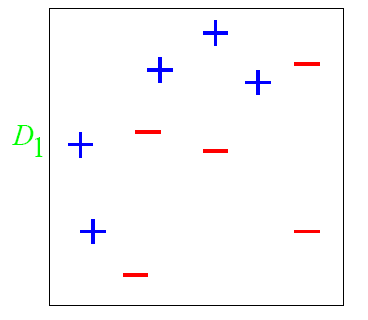
图中’+‘和’-'表示不同的类别,我们想训练出一个特征矩阵能够分出这两类,一开始都赋一样的权比如0.1,第一次训练出的结果是这样的

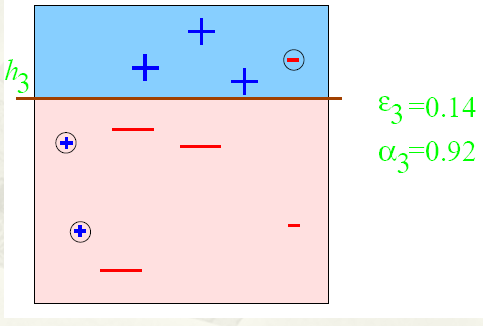
权重都是一样的话那这样就是最理想的,因为左边都是正列,右边加进来就会变差,但是这个还不行因为还有很多正列没有被包含进来,这时候我们把那些没被包含进来的正列加权,对已经加进来的正列减全,这样第二次训练就变成了

虽然把所有正列都包进来了但是还是有一些负的,所以把负的权重增大,包含进来的正的减小,这样第三次训练就变成了
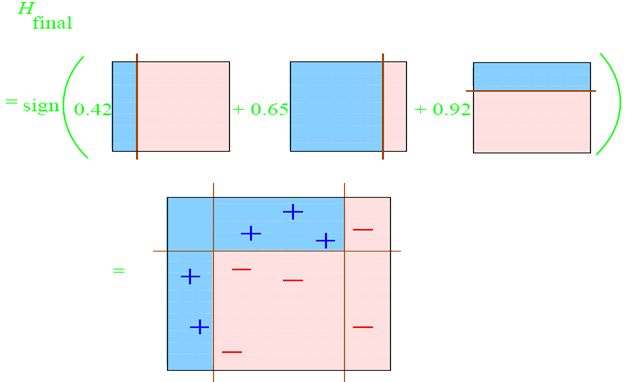
然后把这三次训练加权结合就变成了最终的强分类器
特征点提取
特征点提取也有很多算法,感兴趣的可以自行去了解吧,比如HOG,CNN这些
我这里采用的是dlib模型提取人脸68个特征点,因为我自己尝试了写之后发现效果很差不如直接用别人训练好的模型(我是fw)
配置好CMake dlib opencv等环境
"""
作者:Mibbp
日期: 2022年10月30日
"""
import dlib
import cv2
import numpy as np
import math
predictor_path = 'D:/dlib-shape/shape_predictor_68_face_landmarks.dat' # 导入模型
# 使用dlib自带的frontal_face_detector作为我们的特征提取器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
def landmark_dec_dlib_fun(img_src):
img_gray = cv2.cvtColor(img_src, cv2.COLOR_BGR2GRAY)
land_marks = []
rects = detector(img_gray, 0)
for i in range(len(rects)):
land_marks_node = np.matrix([[p.x, p.y] for p in predictor(img_gray, rects[i]).parts()])
for idx,point in enumerate(land_marks_node):
# 68点坐标
pos = (point[0,0],point[0,1])
# print(idx,pos)
# 利用cv2.circle给每个特征点画一个圈,共68个
cv2.circle(img_src, pos, 5, color=(0, 255, 0))
# 利用cv2.putText输出1-68
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img_src, str(idx + 1), pos, font, 0.3, (0, 0, 255), 1, cv2.LINE_AA)
land_marks.append(land_marks_node)
return land_marks
def main():
src = cv2.imread('C:/Users/mibbp/Pictures/xfsy_0068.jpg')
# cv2.imshow('src', src)
landmark_dec_dlib_fun(src)
cv2.imshow("src", src)
cv2.waitKey(0)
if __name__ == '__main__':
main()

如上图所示,其中1 ~ 17为人脸轮廓,18 ~ 22为左眉毛,23 ~ 27为右眉毛,28 ~ 36为鼻子,37 ~ 42为左眼,43 ~ 48为右眼,49 ~ 60为外嘴唇轮廓,61 ~ 68为内嘴唇或牙齿轮廓
液化算法
瘦脸算法有很多,本质上都是像素迁移或者图像扭曲算法,比如基于最小二乘法的MLS,还有这里介绍的液化算法
想深入理解的可以看论文,我这里只做通俗解释
-
MLS: Image Deformation Using Moving Least Squares
-
液化:Interactive Image Warping
-
人脸图像变形技术
算法原理
这些像素迁移或者图像扭曲算法,其实都可以看作是把某一个像素移动到一个目标位置,比如瘦脸就是把脸外围的像素往里收缩,实际上就是计算出目标点的位置,然后把当前点替换成目标点的像素就行,但是直接替换肯定使不行的,因为计算出的目标点坐标是实数,但是实际上像素点坐标都是整数,而且为了能够使变化后的图形更平滑,所以要用一些重采样技术进行一些插值处理
前向映射和后向映射
空间映射是指建立原图像与目标图像之间各对应像素点的映射关系的函数,而其中又分为前向映射和后向映射说人话前向映射就是指通过原图像某个像素点算出目标图像对应像素点,后向映射就是通过目标图像像素点算出他是由原图像那个点转移过去的
图像变形中,各像素点之间的映射关系一般不是一一对应的,会产生“空洞”和“混叠”现象(源图像中的多点映射到目标图像中的一点)的前向映射方式并不能满足图像变形过程中的要求,为了解决这一问题,我们可以采用非均勾采样、相交检测等方法,但是这些方法会带来空间和时间上开销较大的不利影响。为了保证变形图像的唯一性(没有“空洞”和“混叠”现象)、完整性,我们采用后向映射的方法可以很好地解决时间和空间上的开销问题,它将目标图像中的每个像素点都映射到源图像中对应的某个位置,这些位置的灰度值利用重釆样技术得到。由于后向映射在实现方式上很方便,仅用源图像中的特征作为目标特征,用变形后的图像即目标图像中的特征作为源特征建立映射关系就可以完成。因此后向映射成为主流的映射方式。
最近邻域插值
这个名字听着可厉害其实就是对求出的点的坐标四舍五入一下就好了,也就是求得的实数点 ( x , y ) (x,y) (x,y)的像素值 R G B ( x , y ) RGB(x,y) RGB(x,y)由距离该店最近的像素点RGB值替代
R G B ( x , y ) = R G B ( r o u n d ( x ) , r o u n d ( y ) ) RGB(x,y) = RGB(round(x),round(y)) RGB(x,y)=RGB(round(x),round(y))
领域平均插值
邻域平均插值将实数点处的灰度值用它的邻域像素点的平均值来代替。设点处的个最近邻像素为, A , B , C , D A,B,C,D A,B,C,D。它们的灰度值分别为 g r a y ( A ) , g r a y ( B ) , g r a y ( C ) , g r a y ( D ) gray(A),gray(B),gray(C),gray(D) gray(A),gray(B),gray(C),gray(D)。则
R G B ( x , y ) = R G B ( A ) + R G B ( B ) + R G B ( C ) + R R G B ( D ) 4 RGB(x,y) = \frac {RGB(A)+RGB(B)+RGB(C)+RRGB(D)} {4} RGB(x,y)=4RGB(A)+RGB(B)+RGB(C)+RRGB(D)
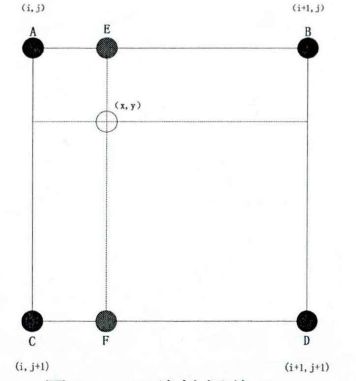
双线性插值
设 ( x , y ) (x,y) (x,y) 点处的 4 个最近邻像素 A , B , C , D A,B,C,D A,B,C,D 的坐标分别为 ( i , j ) , ( i , j + 1 ) , ( i + 1 , j ) , ( i + 1 , j + 1 ) (i,j),(i,j+1),(i+1,j),(i+1,j+1) (i,j),(i,j+1),(i+1,j),(i+1,j+1) 如图所示。
双线性插值按以下步骤计算处的灰度值:
首先计算 E , F E,F E,F 这两点的RGB值 R G B ( E ) , R G B ( F ) RGB(E),RGB(F) RGB(E),RGB(F):
R G B ( E ) = ( x − i ) [ R G B ( B ) − R G B ( A ) ] + R G B ( A ) R G B ( F ) = ( x − i ) [ R G B ( D ) − R G B ( C ) ] + R G B ( C ) RGB(E) = (x-i)[RGB(B)-RGB(A)]+RGB(A) \\ RGB(F) = (x-i)[RGB(D)-RGB(C)]+RGB(C) RGB(E)=(x−i)[RGB(B)−RGB(A)]+RGB(A)RGB(F)=(x−i)[RGB(D)−RGB(C)]+RGB(C)
则 ( x , y ) (x,y) (x,y)得RGB值为:
R G B ( x , y ) = ( y − j ) [ R G B ( F ) − R G B ( E ) ] + R G B ( E ) RGB(x,y) = (y-j)[RGB(F)-RGB(E)]+RGB(E) RGB(x,y)=(y−j)[RGB(F)−RGB(E)]+RGB(E)
相对于邻域平均插值和最近邻域插值,双线性插值虽然有较大的计算量,但其插值结果比较平滑。考虑到人脸图像需要高度的真实感,选择使用双线性插值进行重采样
液化算法思路
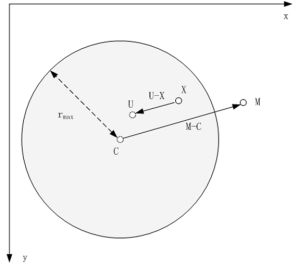
假设当前点为 X ( x , y ) X (x,y) X(x,y),指定变形区域的中心点为 C ( C x , C y ) C(C_x,C_y) C(Cx,Cy),变形区域半径为 r r r,调整变形终点(从中心点到某个位置M)为 M ( M x , M y ) M(M_x,M_y) M(Mx,My),变形程度为 s t r e n g t h strength strength,当前点对应变形后的目标位置为 U U U。变形规律如下,
- 圆内所有像素均沿着变形向量的方向发生偏移
- 距离圆心越近,变形程度越大
- 距离圆周越近,变形程度越小,当像素点位于圆周时,该像素不变形
- 圆外像素不发生偏移
U ⃗ = X ⃗ − ( r m a x 2 − ∣ X ⃗ − C ⃗ ∣ 2 ( r m a x 2 − ∣ X ⃗ − C ⃗ ∣ 2 ) + ∣ M ⃗ − C ⃗ ∣ 2 ) ( M ⃗ − C ⃗ ) \vec{U} = \vec{X} - \bigg(\frac{r_{max}^2 - \vert \vec{X}-\vec{C} \vert^2 }{(r_{max}^2 - \vert \vec{X}-\vec{C} \vert^2 ) + \vert \vec{M}-\vec{C} \vert^2}\bigg) (\vec{M}-\vec{C}) U=X−((rmax2−∣X−C∣2)+∣M−C∣2rmax2−∣X−C∣2)(M−C)
对上面公式进行改进,加入变形程度控制变量strength,改进后瘦脸公式如下
K 0 = 100 S t r e n g t h K 1 = ( x − C x ) 2 + ( y − C y ) 2 t x = ( r 2 − ( x − C x ) 2 ( r 2 − ( x − C x ) 2 ) + K 0 ( M x − C x ) 2 ) 2 ( M x − C x ) t y = ( r 2 − ( y − C y ) 2 ( r 2 − ( y − C y ) 2 ) + K 0 ( M y − C y ) 2 ) 2 ( M x − C x ) d x = x − t x ( 1.0 − K 1 r ) d y = y − t y ( 1.0 − K 1 r ) K_0 = \frac{100}{Strength} \\ K_1 = \sqrt(x-C_x)^2 + (y-C_y)^2 \\ t_x = \bigg( \frac{r^2-(x-C_x)^2}{(r^2-(x-C_x)^2) + K_0(M_x-C_x)^2} \bigg)^2 (M_x-C_x) \\ t_y = \bigg( \frac{r^2-(y-C_y)^2}{(r^2-(y-C_y)^2) + K_0(M_y-C_y)^2} \bigg)^2 (M_x-C_x) \\ d_x = x-t_x(1.0-\frac{K_1}{r}) \\ d_y = y-t_y(1.0-\frac{K1}{r}) K0=Strength100K1=(x−Cx)2+(y−Cy)2tx=((r2−(x−Cx)2)+K0(Mx−Cx)2r2−(x−Cx)2)2(Mx−Cx)ty=((r2−(y−Cy)2)+K0(My−Cy)2r2−(y−Cy)2)2(Mx−Cx)dx=x−tx(1.0−rK1)dy=y−ty(1.0−rK1)
代码
import dlib
import cv2
import numpy as np
import math
predictor_path = 'D:/dlib-shape/shape_predictor_68_face_landmarks.dat'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
def landmark_dec_dlib_fun(img_src):
img_gray = cv2.cvtColor(img_src, cv2.COLOR_BGR2GRAY)
land_marks = []
rects = detector(img_gray, 0)
for i in range(len(rects)):
land_marks_node = np.matrix([[p.x, p.y] for p in predictor(img_gray, rects[i]).parts()])
land_marks.append(land_marks_node)
return land_marks
def localTranslationWarp(srcImg, startX, startY, endX, endY, radius,Strength):
ddradius = float(radius * radius)
copyImg = np.zeros(srcImg.shape, np.uint8)
copyImg = srcImg.copy()
K0 = 100/Strength
ddmc = (endX - startX) * (endX - startX) + (endY - startY) * (endY - startY) # (m-c)^2
H, W, C = srcImg.shape
for i in range(W):
for j in range(H):
# 计算该点是否在形变圆的范围之内
# 优化,第一步,直接判断是会在(startX,startY)的矩阵框中
if math.fabs(i - startX) > radius and math.fabs(j - startY) > radius:
continue
distance = (i - startX) * (i - startX) + (j - startY) * (j - startY)
K1 = math.sqrt(distance)
if (distance < ddradius):
# 计算出(i,j)坐标的原坐标
# 计算公式中右边平方号里的部分
ratio = (ddradius - distance) / (ddradius - distance + K0 * ddmc)
ratio = ratio * ratio
# 映射原位置
UX = i - (ratio * (endX - startX) * (1.0 - (K1 / radius)))
UY = j - (ratio * (endY - startY) * (1.0 - (K1 / radius)))
# 根据双线性插值法得到UX,UY的值
value = BilinearInsert(srcImg, UX, UY)
# 改变当前 i ,j的值
copyImg[j, i] = value
return copyImg
# 双线性插值法
def BilinearInsert(src, ux, uy):
w, h, c = src.shape
if c == 3:
x1 = int(ux)
x2 = x1 + 1
y1 = int(uy)
y2 = y1 + 1
part1 = src[y1, x1].astype(np.float) * (float(x2) - ux) * (float(y2) - uy)
part2 = src[y1, x2].astype(np.float) * (ux - float(x1)) * (float(y2) - uy)
part3 = src[y2, x1].astype(np.float) * (float(x2) - ux) * (uy - float(y1))
part4 = src[y2, x2].astype(np.float) * (ux - float(x1)) * (uy - float(y1))
insertValue = part1 + part2 + part3 + part4
return insertValue.astype(np.int8)
def face_thin_auto(src,LStrength,RStrength,Lcen,Rcen,Lrad,Rrad,Center):
# src为原图像
# LStrength,RStrength为左右脸形变强度
# Lcen,Rcen为左右脸形变中心
# Lrad,Rrad为形变范围半径
# Center为形变重点一般就是人脸中心鼻子那一块
LStrength为
landmarks = landmark_dec_dlib_fun(src)
# print(landmarks)
# 如果未检测到人脸关键点,就不进行瘦脸
if len(landmarks) == 0:
return
for landmarks_node in landmarks:
# print(landmarks_node)
left_landmark = landmarks_node[Lcen]
left_landmark_down = landmarks_node[Lcen+Lrad]
right_landmark = landmarks_node[Rcen]
right_landmark_down = landmarks_node[Rcen+Rrad]
endPt = landmarks_node[Center]
# 计算第Lcen个点到第Lcen+Lrad个点的距离作为瘦脸距离
r_left = math.sqrt(
(left_landmark[0, 0] - left_landmark_down[0, 0]) * (left_landmark[0, 0] - left_landmark_down[0, 0]) +
(left_landmark[0, 1] - left_landmark_down[0, 1]) * (left_landmark[0, 1] - left_landmark_down[0, 1]))
# 计算第Rcen个点到第Rcen+Rrad个点的距离作为瘦脸距离
r_right = math.sqrt(
(right_landmark[0, 0] - right_landmark_down[0, 0]) * (right_landmark[0, 0] - right_landmark_down[0, 0]) +
(right_landmark[0, 1] - right_landmark_down[0, 1]) * (right_landmark[0, 1] - right_landmark_down[0, 1]))
# 瘦左边脸
thin_image = localTranslationWarp(src, left_landmark[0, 0], left_landmark[0, 1], endPt[0, 0], endPt[0, 1],
r_left,LStrength)
# 瘦右边脸
thin_image = localTranslationWarp(thin_image, right_landmark[0, 0], right_landmark[0, 1], endPt[0, 0],
endPt[0, 1], r_right,RStrength)
# 显示
# cv2.imshow('thin', thin_image)
# 保存
cv2.imwrite('C:/Users/mibbp/Pictures/thin.jpg', thin_image)
def test():
print("pytest1")
def main(LStrength,RStrength,Lcen,Rcen,Lrad,Rrad,Center):
LStrength = int(LStrength)
RStrength = int(RStrength)
Lcen = int(Lcen)
Rcen = int(Rcen)
Lrad = int(Lrad)
Rrad = int(Rrad)
Center = int(Center)
src = cv2.imread('C:/Users/mibbp/Pictures/pysltest.jpg')
# cv2.imshow('src', src)
face_thin_auto(src,LStrength,RStrength,Lcen,Rcen,Lrad,Rrad,Center)
cv2.waitKey(0)
if __name__ == '__main__':
main()
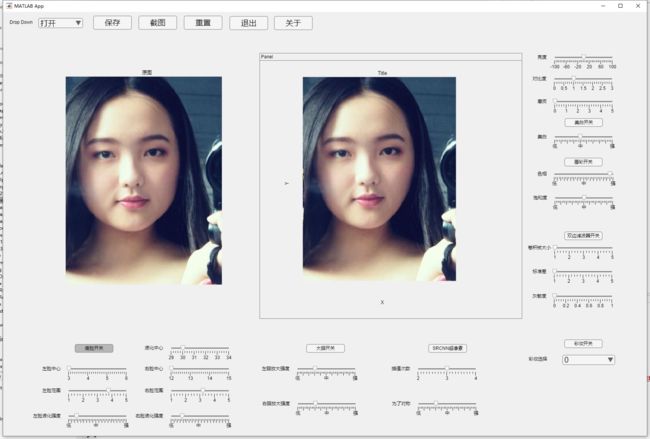
效果展示
参考资料
-
https://blog.csdn.net/qq_14845119/article/details/121500720
-
https://blog.csdn.net/nk_wavelet/article/details/52590487
-
https://www.cnblogs.com/zyly/p/9410563.html
-
MLS: Image Deformation Using Moving Least Squares
-
液化:Interactive Image Warping
-
人脸图像变形技术