【用于图像修复、数据增强等】结合官方代码教程,在Windows 10下运行pix2pix-tensorflow(tensorflow==1.4.0 python=3.6)
目录
- 参考链接
- 0. 安装所需环境tensorflow==1.4.1 python=3.6
- 1. 制作数据集
-
- 1.1 我原本的数据集分布
- 1.2 运行代码`tools/process.py`生成pix2pix所需图像
- 2. 开始训练
- 3. 代码更改与学习记录
-
- 3.1 加入代码,记录log打印日志
- 3.2 损失的作用和标准
- 4. 错误记录
-
- 3.1 执行train.py时,出现错误:Nan in summary histogram【梯度爆炸】
参考链接
-
github代码:github-pix2pix-tensorflow(这个版本的代码是比较老的,tensorflow框架的。直接在github上搜索pix2pix可以直接检索到最新的基于Pytorch的代码:pytorch-CycleGAN-and-pix2pix)
-
相关的文章:从样本到部署Pix2Pix图像翻译案例全流程记录
-
Linux环境下的配置可以参考:AotuDL中Linux环境下运行pix2pix-tensorflow的环境配置(tensorflow==1.8.0 python==3.6)
0. 安装所需环境tensorflow==1.4.1 python=3.6
github上的代码说的需要的版本是tensorflow==1.4.1,但是找遍全网,发现并没有1.4.1的版本,全部都是关于1.4.0版本的安装。然后就看到了这个问题的回答:I am not able to install tensorflow=1.4.1。大概意思就是说:tensorflow==1.4.1是在Linux中可使用的版本,在Windows下可用1.4.0版本替代(然偶看了下github代码,确实他是在Linux下运行的)
所以就参考这篇博文安装1.4.0版本:tensorflow1.4的详细安装教程,我下载的是GPU的tensorflow1.4.0,点击可直接下载tensorflow_gpu-1.4.0-cp36-cp36m-win_amd64.whl
#-------------------------可能会用到的命令----------------------------#
- 查看已有的虚拟环境:
conda info --env - 删除不想要的虚拟环境:
conda remove -n xxx -all - 如需修改虚拟环境默认安装路径,可参考:Anaconda 修改默认虚拟环境安装位置
#--------------------------------------------------------------------------------#
在这个里面键入以下命令:
![]()
- 创建虚拟环境
tf1.4
conda create -n tf1.4 python=3.6
- 激活并进入到
tf1.4虚拟环境
conda activate tf1.4
- 安装tensorflow_gpu-1.4.0
点击下载镜像:tensorflow_gpu-1.4.0-cp36-cp36m-win_amd64.whl
然后键入以下命令:(键入这个镜像的绝对路径。conda不好用时,可换成pip。-i后面是引用豆瓣源加速)
conda install .../tensorflow_gpu-1.4.0-cp36-cp36m-win_amd64.whl -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
- 参考这篇文章知道应该安装keras=2.0.8的版本:解决AttributeError: module ‘tensorflow‘ has no attribute ‘placeholder‘问题(只是暂存一下,还没有做关于
keras的修改,看了一下安装的tensorflow好像没有自带着下载keras,所以需要用keras时再下载2.0.8版本的吧)

- 安装对应的CUDA和cudnn
点击直接下载,下载后的安装流程可参考tensorflow-gpu版本安装教程(过程详细):
- CUDA:cuda_9.1.85_win10.exe
- cudnn:cudnn-9.1-windows10-x64-v7
我的显卡是RTX3050,可用的是CUDA v11.3的,所以之前就已经安装过CUDA113了,对应安装了tensorflow=2.6.0 python=3.8的。但是本文的代码是需要tensorflow=1.4.0 python=3.6的,对应的CUDA是版本 v9.1的,所以我需要重新安装CUDA v.9.1以及相应cudnn。
但是我原本的CUDA v11.3并没有卸载。我看有的文章说的一台电脑可安装多个CUDA,不同虚拟环境中的tensorflow会自动选择对应的CUDA版本,只要在环境变量中指明了每个CUDA的安装位置即可(其实在每个CUDA安装的时候,都会自动将自己的路径添加系统变量path,如下图,但是要留意一下图中的2点,现在是指向v9.1的,不知道会不会影响v11.3的使用,要以后用到了才知道咯~)

- 测试是否tensorflow-gpu安装配置成功
activate tf1.4
python
import tensorflow as tf
tf.test.is_gpu_available() # True
发现安装了CUDAv9.1之后多了个这个:
![]()
Visual Profiler 是是一个图形化的剖析工具,可以显示你的应用程序中CPU和GPU的活动情况,利用分析引擎帮助你寻找优化的机会。(摘录自CUDA入门(四)Visual Profiler)
1. 制作数据集
1.1 我原本的数据集分布
G:.
├─images
│ ├─train
│ └─val
├─labels
│ ├─train
│ └─val

1.2 运行代码tools/process.py生成pix2pix所需图像
需要用到的4个重要参数:
input_dir:图像文件夹1(images)b_dir:图像文件夹2(labels)operation:选择的操作,我这里选择的操作直接是合并combineoutput_dir:合并图像的保存文件夹
运行后的文件夹分布为:
G:.
├─images
│ ├─train
│ └─val
├─labels
│ ├─train
│ └─val
-------------------上面是原本的数据--------------------
------------------下面是合并后的数据--------------------
├─train
└─val
整体的运行命令:
- 合并生成
train数据集:
python process.py --input_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/images/train --output_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/train --b_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/labels/train --operation combine
- 合并生成
val数据集:
python process.py --input_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/images/val --output_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/val --b_dir G:/pycharmprojects/pytorch-CycleGAN-and-pix2pix-master/datasets/linedataset/labels/val --operation combine
合并后的图像示例:(其实就是直接把两张图片横着拼在一起了,自己写代码也能实现)
2. 开始训练
传入的地址须要是绝对地址:
python pix2pix.py --input_dir G:\pycharmprojects\pytorch-CycleGAN-and-pix2pix-master\datasets\linedataset\train --mode train --outp
ut_dir runs/linedata_pix2pix --max_epochs 200 --which_direction BtoA --batch_size 32
训练过程中的终端界面:
(如果显存不够,很大可能就一直卡在这个地方了。所以我选择在AutoDL云服务器上调大batch_size跑代码。想使用AutoDL的可参考博客:AutoDL使用教程:1)创建实例 2)配置环境+上传数据 3)PyCharm2021.3专业版下载安装与远程连接完整步骤)
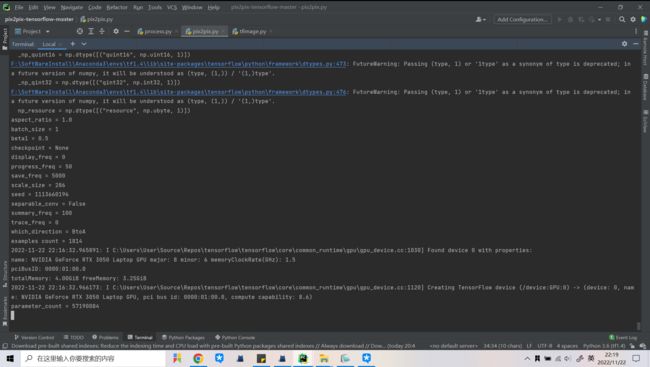
3. 代码更改与学习记录
3.1 加入代码,记录log打印日志
如下,在pix2pix.py的793行代码下面添加如下代码:

代码:
# --------------lwd edit--------------- #
txt_path = os.path.join(a.output_dir, 'result.txt')
with open(txt_path, 'a') as f: # a 表示追加写入
f.write("progress epoch %d step %d image/sec %0.1f remaining %dm" % (train_epoch, train_step, rate, remaining / 60))
f.write(f'discrim_loss: {results["discrim_loss"]} | gen_loss_GAN: {results["gen_loss_GAN"]} | gen_loss_L1: {results["gen_loss_L1"]}\n\n')
# -------------------------------------- #
3.2 损失的作用和标准
参考自官方文档:https://www.tensorflow.org/tutorials/generative/pix2pix

4. 错误记录
3.1 执行train.py时,出现错误:Nan in summary histogram【梯度爆炸】
- 参考链接:执行train.py时,训练到一半出现错误:Nan in summary histogram for: ModelVars/FeatureExtractor/MobilenetV1/Conv
出现原因:batch-size设为了1
解决方法:batch-size不设为1(设置成偶数比较好)(好像并没有解决)
- 参考链接:pix2pix-tensorflow的一个issue:Invalid argument: Nan in summary histogram for: generator/encoder_1/conv2d/kernel/values #190,见下图,说的是学习率太高了(所以我将
--lr参数设置为了0.00001)

- 参考链接:stackoverflow-Nan in summary histogram,通常 NaN 是模型不稳定的标志,例如梯度爆炸

