论文笔记 EMNLP 2019|Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event
文章目录
-
- 1 简介
-
- 1.1 动机
- 1.2 创新
- 2 相关工作
- 3 方法
-
- 3.1 输入表示
- 3.2 实体识别
- 3.3 文档级实体编码
-
- 3.3.1 实体和句子编码
- 3.3.2 文档级别编码
- 3.4 基于实体的有向无环图的生成
-
- 3.4.1 EDAG的建立
- 3.4.2 任务分解
- 3.4.3 记忆
- 3.4.4 路径扩展
- 3.4.5 优化
- 3.4.5 训练
- 4 实验
- 5 总结
1 简介
论文题目:Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction
论文来源:EMNLP 2019
论文链接:https://arxiv.org/pdf/1904.07535.pdf
代码链接:https://github.com/dolphin-zs/Doc2EDAG
1.1 动机
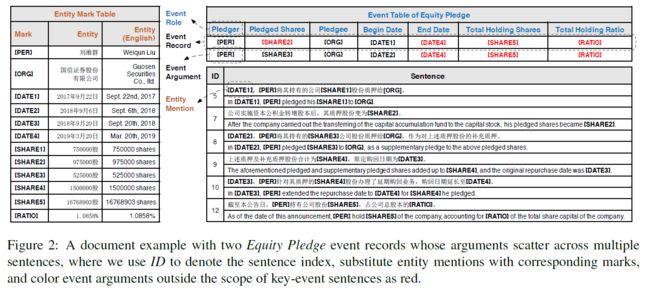
- 在金融领域,事件抽取有两个挑战,论元分散和多事件,如下图。
1.2 创新
- 提出一个模型,可以基于一个文档直接生成事件表,将事件表转换为一个基于实体的有向无环图,将事件表的填充任务转换为几个序列路径扩展的子任务。
- 不使用触发词,解决文档级的事件抽取。
- 构建了一个大规模的文档级别数据库,存在论元分散和多事件问题。
2 相关工作
应用远程监督到关系抽取,需要大量的努力消除标签的噪声。但是,对于文档级事件抽取,使用远程监督和一些简单的限制可以获得好的标签质量。主要原因有两点:
- 知识库和文本文档来自相同的领域。
- 一个事件记录包括多个论元,而一个关系只涉及两个实体。
为了保证标签的质量,对匹配的事件记录进行下面两个限制:
- 预定义的关键事件角色的论元必须存在(非关键的可以为空)
- 匹配的论元数量必须高于一个确定的阀值
3 方法
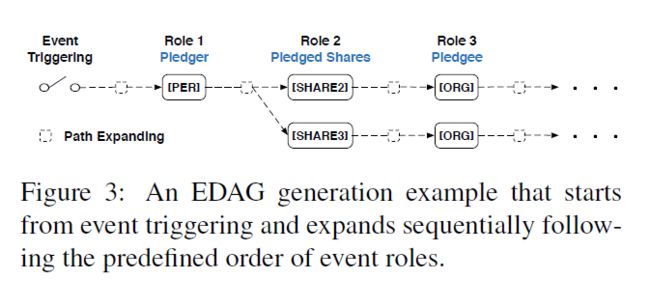
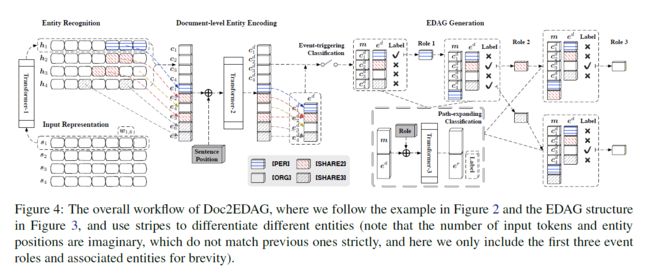
Doc2EDAG的关键是将扁平的事件记录转换为一个基于实体的有向无环图,有向无环图的生成如下图三,下图四为整个模型的框架,主要包括两个部分:文档级实体编码和基于实体的有向无环图的生成。
3.1 输入表示
token编码表为 V ∈ R d w × ∣ V ∣ V{\in}R^{d_w{\times}|V|} V∈Rdw×∣V∣,将一个文档d表示为一个句子的序列 [ s 1 ; s 2 ; . . . ; s N s ] [s_1;s_2;...;s_{N_s}] [s1;s2;...;sNs],每一个句子 s i ∈ R d w × N w s_i{\in}R^{d_w{\times}N_w} si∈Rdw×Nw表示为 [ w i , 1 ; w i , 2 ; . . . ; w i , N w ] [w_{i,1};w_{i,2};...;w_{i,N_w}] [wi,1;wi,2;...;wi,Nw],其中|V|为单词的个数, N s N_s Ns和 N w N_w Nw分别是句子序列和token序列的最大长度。
3.2 实体识别
实体识别是一个经典的序列标注任务,使用Transformer和CRF完成序列标注,对于一个句子 s i ∈ R d w × N w s_i{\in}R^{d_w{\times}N_w} si∈Rdw×Nw,使用Transformer编码 h i = T r a n s f o r m e r − 1 ( s i ) h_i=Transformer-1(s_i) hi=Transformer−1(si), h i ∈ R d w × N w h_i{\in}R^{d_w{\times}N_w} hi∈Rdw×Nw,经CRF处理后计算loss,使用BIO标注论元的角色,在推理阶段,使用维特比解码。
3.3 文档级实体编码
为了高效的解决论元分散问题,全局上下文的信息是重要的。
3.3.1 实体和句子编码
对于实体提及,通过max-pooling每个实体提及覆盖的token得到固定尺寸的编码。例如,第 l l l个实体提及在第 i i i个句子中覆盖第 j j j个到第 k k k个token,对 [ h i , j , . . . , h i , k ] [h_{i,j},...,h_{i,k}] [hi,j,...,hi,k]进行最大池化操作,得到实体提及的编码 e l ∈ R d w e_l{\in}R^{d_w} el∈Rdw,对于每个句子 s i s_i si,对每个token序列 [ h i , 1 , . . . , h i , N w ] [h_{i,1},...,h_{i,N_w}] [hi,1,...,hi,Nw]得到句子编码 c i ∈ R d w c_i{\in}R^{d_w} ci∈Rdw.
3.3.2 文档级别编码
尽管已经得到了全部的句子和实体提及编码,但这些编码仅在句子级别编码局部的上下文信息。为了利用文档级别的上下文信息,使用Transformer促进全部实体提及和句子之间的信息交流,在加入Transformer之前,加入句子位置编码,然后使用max-pooling操作将具有相同实体名称的多个提及编码合并到一个编码中,最后得到文档级别上下文的实体提及和句子编码 e d = [ e 1 d , . . . , e N e d ] e^d=[e_1^d,...,e_{N_e}^d] ed=[e1d,...,eNed]和 c d = [ c 1 d , . . . , c N s d ] c^d=[c_1^d,...,c_{N_s}^d] cd=[c1d,...,cNsd],其中 N e N_e Ne是不同实体的数量。
3.4 基于实体的有向无环图的生成
通过max-pooling句子编码 c d ∈ R d w × N s c^d{\in}R^{d_w{\times}N_s} cd∈Rdw×Ns,得到文档编码 t ∈ R d w t{\in}R^{d_w} t∈Rdw,然后对t进行事件触发词分类。
3.4.1 EDAG的建立
对于每个事件类型,我们首先人为定义一个事件角色顺序,按照这个顺序将事件记录转换为论元链表,每一个论元结点是一个实体或者一个特殊的空论元NA。最后,通过合并相同前缀路径的链表生成基于实体的有向无环图。
3.4.2 任务分解
事件触发词作为开始结点,然后根据预定义的事件角色顺序进行一系列路径扩展子任务。当考虑某个角色时,对于当前EDAG的每个叶节点,都有一个路径扩展子任务来决定要扩展哪些实体。对于每个要扩展的实体,为当前角色的实体创建一个新的结点,并通过将当前叶节点连接到新实体节点来展开路径。如果没有实体扩展,创建一个特殊的NA结点。当前角色的全部子任务完成,移动到下个结点,重复到最后。
3.4.3 记忆
为了更好地进行路径扩展子任务,知道实体已经包含在路径中是关键的。因此,设计一个记忆机制使用句子张量 c d c^d cd初始化记忆张量 m m m,扩展路径时更新 m m m。通过这个事件,每个子任务可以拥有一个独特的记忆张量结合独特的路径历史。
3.4.4 路径扩展
对于每个路径扩展子任务,定义它作为多个二元分类问题的集合,对全部实体预测扩展或不扩展。为了能够了解当前路径状态、历史上下文和当前事件角色,首先拼接记忆张量 m m m和实体张量 e d e^d ed,然后添加一个可训练的事件角色指示器编码,然后使用Transformer-3编码。得到Transformer-3的输出 e r e^r er,最后进行路径扩展分类。
3.4.5 优化
对事件触发词分类,计算交叉熵损失 L t r L_{tr} Ltr。在基于实体的有向无环图的生成阶段,计算每个路径扩展子任务的交叉熵损失,这些子任务的损失和为 L d a g L_{dag} Ldag,最终损失为 L a l l = λ 1 L e r + λ 2 L t r + λ 3 L d a g L_{all}={\lambda}_1L_{er}+{\lambda}_2L_{tr}+{\lambda}_3L_{dag} Lall=λ1Ler+λ2Ltr+λ3Ldag,其中 L e r L_{er} Ler为实体识别损失。
3.4.5 训练
在训练阶段,使用真实的实体token和给定的EDAG结构。在推理阶段,首先识别实体,根据这些实体的编码依次的扩展路径。训练和推理的差异将导致几个错误传播问题。为了缓解这个问题,使用计划采样(scheduled sampling)逐步将文档级实体编码的输入从真实实体提及转换为模型识别的实体提及。
同时对于路径扩展分类,预测为正的负样本比预测为负的正样本更有害,因为预测为正的负样本产生一个完全错误的路径,因此设置 γ ( > 1 ) {\gamma}(>1) γ(>1)作为负样本的在交叉熵中的权重。
注:在序列生成任务中,训练时模型将目标序列中的真实元素作为解码器每一步的输入,然后最大化下一个元素的概率。scheduled sampling以一定概率将生成的元素作为解码器输入,通常概率越来越大,解码器将不断倾向于使用生成的元素作为输入,训练和生成阶段的数据分布将变得越来越一致。
4 实验
通过实验回答下面问题:
- 面对文档级事件抽取特定的挑战,Doc2EDAG在多大程度上可以超越最先进的方法?
- 当面对论元反散和多事件时,不同的模型表现如何?
- Doc2EDAG的各个组件有多重要?
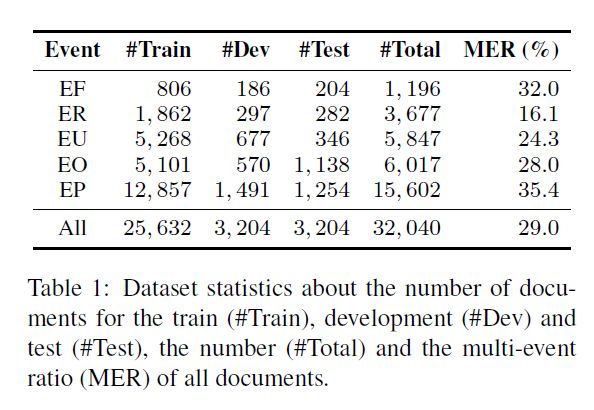
使用2008-2018的ChFinAnn文档和人为总结的事件知识库构建基于远程监督的事件标注。主要集中下面5种事件类型Equity Freeze (EF), Equity Repurchase(ER), Equity Underweight (EU), Equity Overweight (EO) and Equity Pledge (EP)。使用上面(第2节)介绍的限制,保证标注的质量。为了避免中文分词带来的误差传播,使用字符级别的token。数据集如下图:
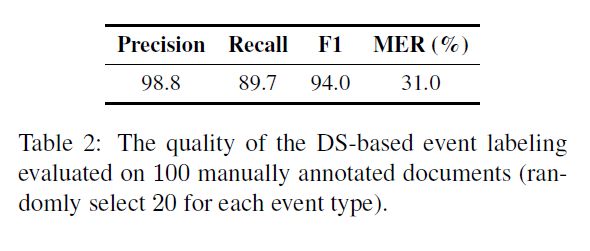
随机选择100个文档进行人工标注,验证基于远程监督的事件标注质量,结果如下图。
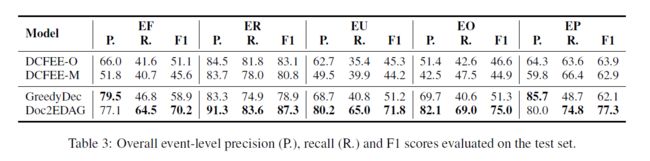
实验结果如下图
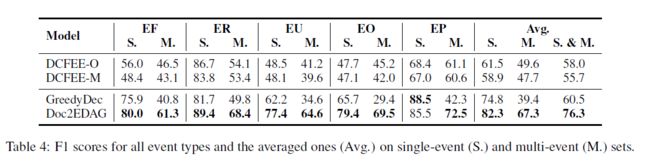
将测试集分为单事件集(一个文档仅包含一个事件记录)和多事件集,以展示当论元发散遇到多时间时带来额外的困难,实验结果如下:
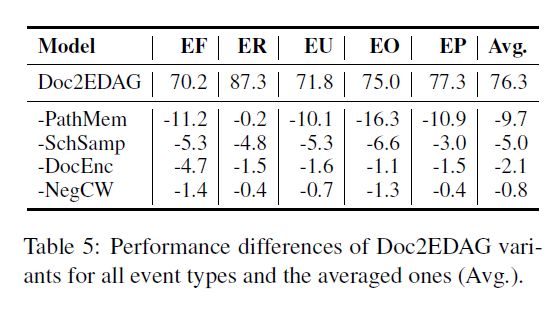
以下面四个变体进行消融实验:
- -PathMem:移除记忆机制
- -SchSamp: 移除分时采样
- -DocEnc:删除用于文档级实体编码的Transformer
- -NegCW:做路径扩展分类时,保持负样本的权重为1
5 总结
- 提出一个新的模型Doc2EDAG,定义了一个新的任务形式不使用触发词,以减轻基于远程监督的标注
- 构建了一个大规模的金融领域数据集