机器学习之贝叶斯网络实践(举例)
一、贝叶斯算法推导相关
朴素贝叶斯的假设:
一个特征出现的概率,与其他特征(条件)独立(特征独立性),即对于给定分类的条件下,特征独立;
每个特征同等重要(特征均衡性)
朴素贝叶斯的推导:
朴素贝叶斯(Naive Bayes,NB)是基于“特征之间是独立的”这一朴素假设,应用贝叶斯
定理的监督学习算法;
对于给定的特征向量:
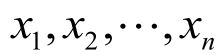
类别y的概率可以根据贝叶斯公式得到:
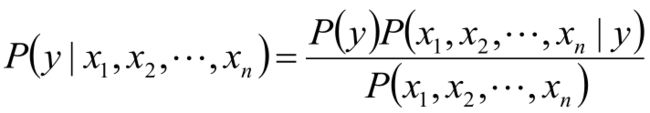
使用朴素的独立性假设:
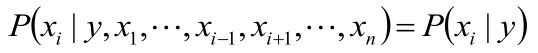

高斯朴素贝叶斯:

多项分布朴素贝叶斯 Multinomial Naive Bayes

拉普拉斯平滑:

二、代码实践样例
高斯朴素贝叶斯代码样例:
from sklearn.naive_bayes import GaussianNB, MultinomialNB
import numpy as np
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
data = pd.read_csv('..\\8.Regression\\iris.data', header=None)
x, y = data[np.arange(4)], data[4]
y = pd.Categorical(values=y).codes
feature_names = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
features = [0,1]
x = x[features]
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7, random_state=0)
priors = np.array((1,2,4), dtype=float)
priors /= priors.sum()
gnb = Pipeline([
('sc', StandardScaler()),
('poly', PolynomialFeatures(degree=1)),
('clf', GaussianNB(priors=priors))]) #设置先验值
# gnb = KNeighborsClassifier(n_neighbors=3).fit(x, y.ravel())
gnb.fit(x, y.ravel())
y_hat = gnb.predict(x)
print(100 * accuracy_score(y, y_hat))
y_test_hat = gnb.predict(x_test)
print(100 * accuracy_score(y_test, y_test_hat))
文本处理样例:
def load_stopwords():
f = open('stopword.txt')
for w in f:
stopwords.add(w.strip().decode('GB18030'))
f.close()
def segment_one_file(input_file_name, output_file_name):
f = open(input_file_name, mode='r')
f_output = open(output_file_name, mode='w')
pattern = re.compile('(.*?) ')
for line in f:
line = line.decode('GB18030')
news = re.findall(pattern=pattern, string=line)
for one_news in news:
words_list = []
words = jieba.cut(one_news.strip())
for word in words:
word = word.strip()
if word not in stopwords:
words_list.append(word)
if len(words_list) > 10:
s = u' '.join(words_list)
f_output.write(s.encode('utf-8') + '\n')
f.close()
f_output.close()
词处理样例:
from time import time
from gensim.models import Word2Vec
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
class LoadCorpora(object):
def __init__(self, s):
self.path = s
def __iter__(self):
f = open(self.path,'r')
for line in f:
yield line.split(' ')
def print_list(a):
for i, s in enumerate(a):
if i != 0:
print '+',
print s,
if __name__ == '__main__':
if not os.path.exists('news.model'):
sentences = LoadCorpora('news.dat')
t_start = time()
model = Word2Vec(sentences, size=200, min_count=5, workers=8) # 词向量维度为200,丢弃出现次数少于5次的词
model.save('news.model')
print 'OK:', time() - t_start
model = Word2Vec.load('news.model')
print '词典中词的个数:', len(model.vocab)
for i, word in enumerate(model.vocab):
print word,
if i % 25 == 24:
print
print
intrested_words = ('中国', '手机', '学习', '人民', '名义')
print '特征向量:'
for word in intrested_words:
print word, len(model[word]), model[word]
for word in intrested_words:
result = model.most_similar(word)
print '与', word, '最相近的词:'
for w, s in result:
print '\t', w, s
words = ('中国', '祖国', '毛泽东', '人民')
for i in range(len(words)):
w1 = words[i]
for j in range(i+1, len(words)):
w2 = words[j]
print '%s 和 %s 的相似度为:%.6f' % (w1, w2, model.similarity(w1, w2))
print '========================'
opposites = ((['中国', '城市'], ['学生']),
(['男', '工作'], ['女']),
(['俄罗斯', '美国', '英国'], ['日本']))
for positive, negative in opposites:
result = model.most_similar(positive=positive, negative=negative)
print_list(positive)
print '-',
print_list(negative)
print ':'
for word, similar in result:
print '\t', word, similar
print '========================'
words_list = ('苹果 三星 美的 海尔', '中国 日本 韩国 美国 北京',
'医院 手术 护士 医生 感染 福利', '爸爸 妈妈 舅舅 爷爷 叔叔 阿姨 老婆')
for words in words_list:
print words, '离群词:', model.doesnt_match(words.split(' '))