机器学习:贝叶斯和优化方法
I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Hyperparameter optimization is a key aspect of the lifecycle of machine learning applications. While methods such as grid search are incredibly effective for optimizing hyperparameters for specific isolated models, they are very difficult to scale across large permutations of models and experiments. A company like Facebook operates thousands of concurrent machine learning models that need to be constantly tuned. To achieve that, Facebook engineering teams need to regularly conduct A/B tests in order to determine the right hyperparameter configuration. Data in those tests is difficult to collect and they are typically conducted in isolation of each other which end up resulting in very computationally expensive exercises. One of the most innovative approaches in this area came from a team of AI researchers from Facebook who published a paper proposing a method based on Bayesian optimization to adaptively design rounds of A/B tests based on the results of prior tests.
超参数优化是机器学习应用程序生命周期的关键方面。 尽管诸如网格搜索之类的方法对于优化特定隔离模型的超参数非常有效,但它们很难在较大的模型和实验排列范围内扩展。 像Facebook这样的公司运营着成千上万个需要不断调整的并发机器学习模型。 为此,Facebook工程团队需要定期进行A / B测试,以确定正确的超参数配置。 这些测试中的数据很难收集,它们通常彼此隔离地进行,最终导致计算量很大。 该领域最具创新性的方法之一来自Facebook的一组AI研究人员,他们发表了一篇论文,提出了一种基于贝叶斯优化的方法,该方法可以根据先前测试的结果自适应地设计A / B测试轮次。
为什么要进行贝叶斯优化? (Why Bayesian Optimization?)
Bayesian optimization is a powerful method for solving black-box optimization problems that involve expensive function evaluations. Recently, Bayesian optimization has evolved as an important technique for optimizing hyperparameters in machine learning models. Conceptually, Bayesian optimization starts by evaluating a small number of randomly selected function values, and fitting a Gaussian process (GP) regression model to the results. The GP posterior provides an estimate of the function value at each point, as well as the uncertainty in that estimate. The GP works well for Bayesian optimization because it provides excellent uncertainty estimates and is analytically tractable. It provides an estimate of how an online metric varies with the parameters of interest.
贝叶斯优化是一种解决黑盒优化问题的强大方法,该问题涉及昂贵的函数评估。 最近,贝叶斯优化已发展成为一种优化机器学习模型中超参数的重要技术。 从概念上讲,贝叶斯优化首先评估少量随机选择的函数值,然后将高斯过程(GP)回归模型拟合到结果中。 GP后验提供了每个点上函数值的估计以及该估计中的不确定性。 GP对于贝叶斯优化非常有效,因为它提供了出色的不确定性估计并且在分析上易于处理。 它提供了有关在线指标如何随目标参数变化的估计。
Let’s imagine an environment in which we are conducting random and regular experiments on machine learning models. In that scenario, Bayesian optimization can be used to construct a statistical model of the relationship between the parameters and the online outcomes of interest and uses that model to decide which experiments to run. The concept is well illustrated in the following figure in which each data marker corresponds to the outcome of an A/B test of that parameter value. We can use the GP to decide which parameter to test next by balancing exploration (high uncertainty) with exploitation (good model estimate). This is done by computing an acquisition function that estimates the value of running an experiment with any given parameter value.
让我们想象一下一个环境,在该环境中我们将对机器学习模型进行随机和常规实验。 在这种情况下,贝叶斯优化可用于构建参数与感兴趣的在线结果之间关系的统计模型,并使用该模型来确定要运行的实验。 下图很好地说明了该概念,其中每个数据标记都对应于该参数值的A / B测试结果。 我们可以使用GP来决定探索(高不确定性)与开发(良好模型估计)之间的平衡,然后再测试哪个参数。 这是通过计算获取函数来完成的,该获取函数会估计使用任何给定参数值运行实验的值。
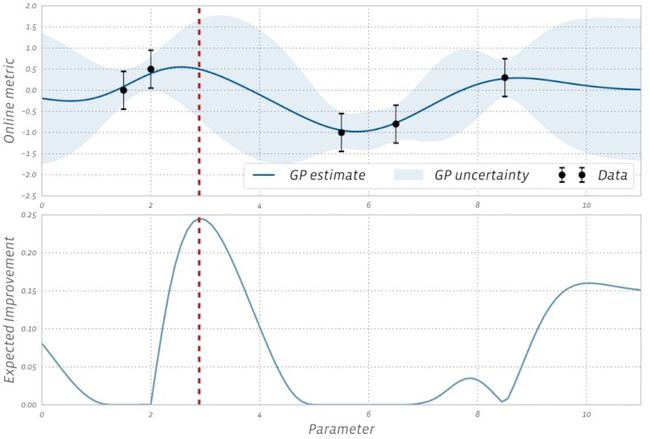
The fundamental goal of Bayesian optimization when applied to hyperparameter optimization is to determine how valuable is an experiment for a specific hyperparameter configuration. Conceptually, Bayesian optimization works very efficiently for isolated models but its value proposition is challenged when used in scenarios running random experiments. The fundamental challenge is related to the noise introduced in the observations.
将贝叶斯优化应用于超参数优化时,其基本目标是确定实验对于特定超参数配置的价值。 从概念上讲,贝叶斯优化对于隔离模型非常有效,但是在用于随机实验的场景中使用贝叶斯优化时,其价值主张受到挑战。 基本挑战与观测结果中引入的噪声有关。
噪声和贝叶斯优化 (Noise and Bayesian Optimization)
Random experiments in machine learning systems introduce high levels of noise in the observations. Additionally, many of the constraints for a given experiment can be considered noisy data in and out itself which can affect the results of an experiment. Suppose that we are trying to evaluate the value of a function f(x) for a given observation x. With observation noise, we now have uncertainty not only in the value f(x), but we also have uncertainty in which observation is the current best, x*, and its value, f(x*).
机器学习系统中的随机实验在观察结果中引入了高水平的噪声。 此外,给定实验的许多约束条件都可以被视为噪声输入和输出本身,这会影响实验结果。 假设我们正在尝试评估给定观察值x的函数f(x)的值。 对于观察噪声,我们现在不仅在值f(x)上具有不确定性,而且在当前最佳观察值x *及其值f(x *)上也具有不确定性。
Typically, Bayesian optimization models use heuristics to handle noisy observations but those perform very poorly with high levels of noise. To address this challenge, the Facebook team came up with a clever answer: why not to factor in noise as part of the observations?
通常,贝叶斯优化模型使用启发式方法来处理嘈杂的观察结果,但是在高噪声水平下,它们的表现非常差。 为了应对这一挑战,Facebook团队提出了一个聪明的答案:为什么不将噪音作为观察的一部分呢?
Imagine if, instead of computing the expectation of observing f(x) we observe yi = f(xi) + €i, where €i is the observation noise. Mathematically, GP works similarly with noise observation as it does with noiseless data. Without going crazy about the math, in their research paper, the Facebook team showed that this type of approximation is very well suited for Monte Carlo optimizations which yield incredibly accurate results estimating the correct observation.
想象一下,如果不是观察f(x)的期望,而是观察yi = f ( x i )+ €i ,其中€i是观察噪声。 在数学上,GP与无噪声数据的工作原理相似。 在研究数学的过程中,Facebook团队毫不犹豫地表示,这种近似方法非常适合蒙特卡洛优化方法,该方法产生难以置信的准确结果,可估计正确的观测值。
带有噪声数据的贝叶斯优化 (Bayesian Optimization with Noisy Data in Action)
The Facebook team tested their research in a couple of real world scenarios at Facebook scale. The first was to optimize 6 parameters of one of Facebook’s ranking systems. The second example was to optimize 7 numeric compiler flags related to CPU usage used in their HipHop Virtual Machine(HHVM). For that second experiment, the first 30 iterations were randomly created. At that point, the Bayesian optimization with noisy data method was able to identity CPU time as the hyperparameter configuration that needed to be evaluated and started running different experiments to optimize its value. The results are clearly illustrated in the following figure.
Facebook团队在Facebook规模的几个真实场景中测试了他们的研究。 首先是优化Facebook排名系统之一的6个参数。 第二个示例是优化与HipHop虚拟机(HHVM)中使用的CPU使用率相关的7个数字编译器标志。 对于第二个实验,随机创建了前30个迭代。 那时,带噪声数据的贝叶斯优化方法能够将CPU时间标识为需要评估的超参数配置,并开始运行不同的实验以优化其价值。 下图清楚地说明了结果。
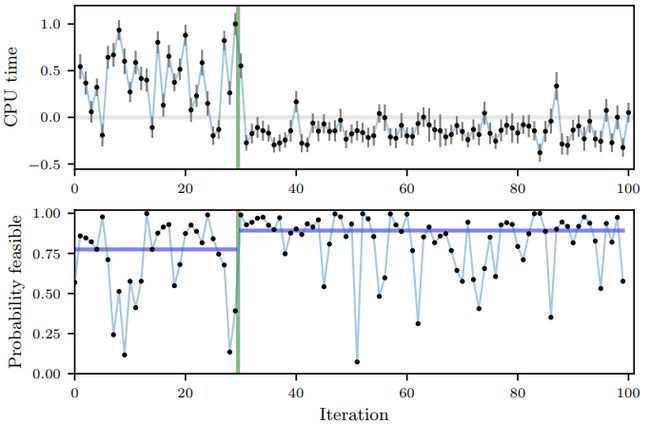
Techniques such as Bayesian optimization with noisy data are incredibly powerful in large scale machine learning algorithms. While we have done a lot of work on optimization methods, most of those methods remain highly theoretical. Its nice to see Facebook pushing the boundaries of this nascent space.
在大型机器学习算法中,诸如带噪声数据的贝叶斯优化之类的技术非常强大。 尽管我们在优化方法方面做了大量工作,但其中大多数方法仍具有很高的理论性。 很高兴看到Facebook突破了这个新兴领域的界限。
翻译自: https://medium.com/dataseries/facebook-uses-bayesian-optimization-to-conduct-better-experiments-in-machine-learning-models-6f834169d005
机器学习:贝叶斯和优化方法