Pytorch入门学习笔记
pytorch==1.5
为什么选择Pytorch
- 活跃度越来越高,逐渐形成了完整的开发生态,资源多
- 动态图架构,运行速度较快
- 代码简洁,易于理解,设计优雅,易于调试
课程内容

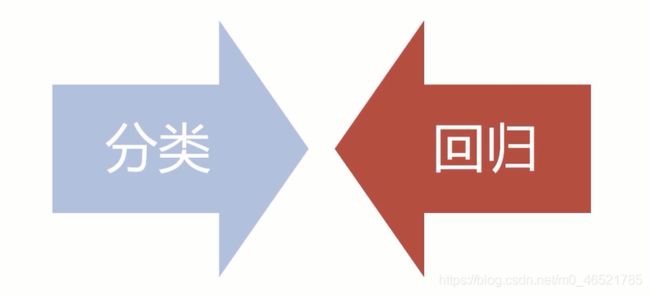
研究的两类问题
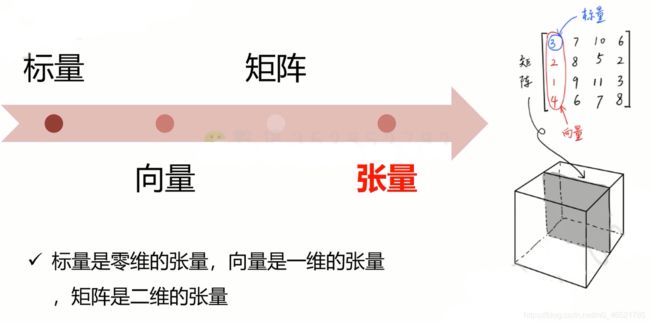
Tensor
tensor是张量,你可能听说过向量,标量等等,我们可以通过张量描述任意维度的物体,其实是对标量,向量,矩阵更加泛化的一个概念,我们使用Tensor描述样本
Tensor常见类型
| 数据类型 | CPU Tensor | GPU Tensor |
|---|---|---|
| 32 bit 浮点 | torch.FloatTensor | torch.cuda.FloatTensor |
| 64 bit 浮点 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16 bit 半精度浮点 | N/A | torch.cuda.HalfTensor |
| 8 bit 无符号整形(0~255) | torch.ByteTensor | torch.cuda.ByteTensor |
| 8 bit 有符号整形(-128~127) | torch.CharTensor | torch.CharTensor torch.cuda.CharTensor |
| 16 bit 有符号整形 | torch.ShortTensor | torch.cuda.ShortTensor |
| 32 bit 有符号整形 | torch.IntTensor | torch.cuda.IntTensor |
| 64 bit 有符号整形 | torch.LongTensor | torch.cuda LongTensor |
Tensor的创建
直接写入数据,默认为float类型:
a = torch.Tensor([[1,2,3],[4,5,6]])
print(a)
print(a.type()) # torch.FloatTensor
指定形状,随机初始化:
a = torch.Tensor(2,3)
print(a)
print(a.shape)
一些特殊的Tensor:
| 函数 | 功能 |
|---|---|
| ones(*size) | 全为1的Tensor |
| zeros(*size) | 全为0的Tensor |
| eye(*size) | 对角线为1,其他为0 |
a = torch.zeros(2,3)
print(a)
a = torch.Tensor(2,3)
a = torch.zeros_like(a)
print(a)
随机Tensor:
# FloatTensor类型
a = torch.rand(2,3)
print(a)
# LongTensor类型
b = torch.randperm(10)
print(b)
符合正态分布/均匀分布的Tensor:
# 正态分布
a = torch.normal(mean=0.0, std=torch.rand(5))
print(a)
# 均匀分布
a = torch.Tensor(2,2).uniform_(-1,1)
print(a)
生成序列Tensor:
a = torch.arange(0, 11, 3)
print(a)
得到等间隔的n个Tensor:
# 即返回四个数值,n=4
a = torch.linspace(2, 10, 4)
print(a)
numpy的相互转换
import torch
import numpy as np
# numpy转Tensor
a = np.array([[1,2,3],[4,5,6]])
b = torch.from_numpy(a)
print(b)
# Tensor转numpy
c = b.numpy()
print(c)
属性
每个Tensor都有torch.dtype、torch.device、torch.layout三种属性,torch.device标识了Tensor对象在创建之后所存储在的设备名称,torch.layout表示Tensor内存布局的对象
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
a = torch.Tensor([1,2,3])
a = a.to(device)
print(a)
# 或者
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
a = torch.Tensor([1,2,3],detype=torch.float32,device=device)
运算
加减乘除:add/sub/mul/div
注:这里的乘法是哈达玛积,是元素对应相乘,不是矩阵乘法
import torch
a = b = torch.Tensor([1,2,3])
c = a + b # 常用
c = torch.add(a,b)
c = a.add(b)
a.add_(b) # 此时修改原来a的值为a+b
矩阵运算:
对于高维的Tensor(dim>2),其矩阵乘法仅在最后的两个维度上,要求前面的维度必须一致
import torch
a = torch.rand(2,3)
b = torch.rand(3,4)
print(torch.mm(a,b))
print(torch.matmul(a,b))
print(a@b)
print(a.matmul(b))
print(a.mm(b))
幂运算(次幂、乘方):
import torch
a = torch.rand(2,3)
print(torch.pow(a,2))
print(a.pow(2))
print(a**2)
print(a.pow_(2))
print(torch.exp(a))
b = a.exp_()
开方运算:
print(a.sqrt())
print(a.sqrt_())
print(a)
对数运算:
print(torch.log2(a))
print(torch.log10(a))
print(torch.log(a))
print(torch.log_(a))
其他运算:

比较运算:
用的不多,不写了。。。。
广播机制
即当维度不同时,默认轮流相加,满足右对齐,即最后一个维度是相同的
import torch
a = torch.rand(2,3)
b = torch.rand(3)
c = a+b
print(a)
print(b)
print(c)
print(c.shape)
tensor([[0.3707, 0.6879, 0.3468],
[0.7848, 0.5571, 0.6672]])
tensor([0.2893, 0.4733, 0.5968])
tensor([[0.6600, 1.1612, 0.9436],
[1.0741, 1.0305, 1.2640]])
torch.Size([2, 3])
一些操作



获取Tensor的数值
tensor.item
使用GPU
if torch.cuda.is_available():
device = torch.device('cuda')
y = torch.ones_like(x,device = device)
# 或者是
x = x.to(device)
# 搬回去
x = x.to('cpu',torch.double)
# 得到gpu的数据
y.to('cpu'.data.numpy())
# 模型搬到cuda
model.cuda()
张量变形
x = torch.randn(4,4)
y = x.view(16) # 变成了一行,即16维
z = x.view(-1,8) # 写-1的话系统会自动换算,即2,8

一些统计学相关函数


一些编程技巧
模型保存
torch.save(state,dir)
torch.load(dir)
并行化
torch.get_num_threads()
torch.set_num_threads(int)
运行放在gpu上
使用to()方法
if torch.cuda.is_avaliable():
device = torch.device('cuda') # GPU
y = torch.ones_like(x,device = device) # 直接创建一个在GPU上的Tensor
x = x.to(device) # 等价于x.to('cuda')
z = x+y
z.to('cpu',torch.double) # to()还可以同时更改数据类型
Tensor与numpy互换
torch.from_numpy()
a.numpy()
一些相关配置

Autograd
每个tensor通过requires_grad参数来设置是否计算梯度,默认为false
如何计算梯度:
使用链式法则,即dz/dx = dz/dy * dy/dx
叶子张量(leaf):
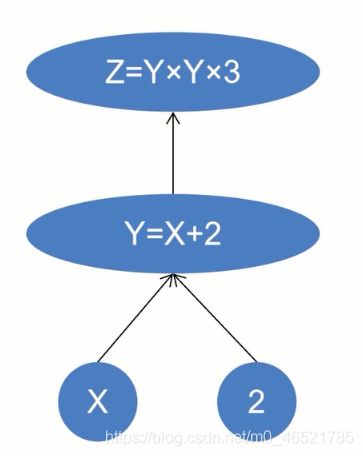
frad与grad_fn:
- grad:该Tensor的梯度值,每次在计算backward时都需要将前一刻的梯度归零,否则梯度值会一直累加
- frad_fn:叶子节点通常为None,只有结果节点的grad_fn才有效,用于指示梯度函数是哪种类型
backwar函数:
- torch.autograd.backward(tensors,grad_tensors=None,retain_graph=None.creat_graph=None)
- retain_graph:通常在调用一次backward之后,pytorch会自动把计算图销毁,所以想对某个变量反复调用backward,则需要将该参数设置为True
- creat_graph:如果为True,那么就创建一个专门的graph of the derivative,这样方便计算高阶微分
torch.autograd.grad()函数:
- grad(outputs,inputs,grad_outputs=None,retain_graph=None,creat_graph=False,only_inputs=True,allow_unused=False)
- 计算和返回output关于inputs的梯度的和
- oututs:函数的因变量,即需要求导的那个函数
- inputs:函数的自变量
- grad_outputs:同backward
- only_inputs:只计算input的梯度
- allow_unused:如果为False,当计算输出出错时指明不适用的inputs
torch.autograd包中其他函数:
- torch.autograd.enable_grad:启动梯度计算的上下文管理器
- torch.autograd.no_grad:禁止梯度计算的上下文管理器
- torch.autograd.set_grad_enable(mode):设置是否进行梯度计算的上下文管理器
torch.autograd.Funcation:
- forward:函数计算从输入Tensor获取的输出Tensor
- backward:函数接收输出Tesnor对于某个标量值的梯度,并且计算输入Tensor相对于该相同标量值的梯度
- 最后,利用apply方法执行相应的运算,定义在Funcation类的父类_FuncationBase中的一个方法
torch.nn库
torch.nn是专门为神经网络设计的模块化接口,nn构建于autograd之上,可以用来定义和运行神经网络
nn.Parameter
- 定义可训练参数,self.param = nn.Parameter(torch.randn(1))
- nn.ParamterList和nn.ParamterDict和python的差不多,而可以使用推导式
self.param = nn.ParameterList([nn.PParameter(torch.randn(10,10)) for i in range(10)])
nn.Linear&nn.conv2d&nn.ReLU&nn.MaxPool2d&nn.MSELoss
定义各种神经网络层,继承于nn.Model的子类
- self.conv1 = nn.Conv2d(1,6,(6,5))
- self.conv1(x)即可调用
参数为Parameter类型:
- layer = nn.Linear(1,1)
- layer.weight = nn.Parameter(torch.FloatTensor([[0]]))
- layer.bias = nn.Parameter(torch.FloatTensor([0]))
nn.funcational
包含torch.nn库中所有函数,包含大量loss和activation funcation,例如:torch.nn.funcational.conv2d()
nn.funcational.xxx是函数接口,无法与nn.Sequential结合使用,需要特别注意dropout层
nn.Module
nn.Sequential(快速搭建神经结构)
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
或者是:
model = nn.Sequential(OrderedDict([
('conv1',nn.Conv2d(1,20,5)),
('relu1',nn.ReLU()),
('conv2d2',nn.Conv2d(20,64,5)),
('relu2',nn.ReLU)
]))
nn.ModeleList
class MyModele(nn.Modele):
def __init__(self):
super(MyModule,self).__init__()
self.linears = nn.ModuleList([nn.Linear(10,40) for i in range(10)])
def forward(self,x):
for i,l in enumerate(self.linears):
x = self.linears[i//2](x) + l(x)
return x
nn.ModeleDict
class MyModele(nn.Modele):
def __init__(self):
super(MyModule,self).__init__()
self.choices= nn.ModuleDict({
'conv':nn.Conv2d(10,10,3),
'pool':nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict([
['lrelu',nn.LeakyReLU()],
['prelu',nn.PReLU]
])
def forward(self,x,choice,act):
x = self.choices[choice](x)
x = self.cativations[act](x)
return x
state_dict() & load_state_dict
- torch.save(model.state_dict(),f=‘net.pth’)
- model.load_statedict(torch.load(‘net.pth’))
Visdom介绍
Facebook专门为Pytorch开发的一款可视化工具,开源于2017年3月,提供了大多数的科学运算可视化api。支持数值、图像、文本以及视频等,支持Pytorch、Torch、Numpy
用户可以通过编程的方式组织可视化空间或者通过用户接口为用户打造表板,检查实验结果和调试代码
安装:
pip install visdom
启动服务:
python -m visdom.server
import visdom
import numpy as np
vis - visdom.Visdom()
vis.text('hello, world!')
vis.image(np.ones((3,10,10)))
tensorboardX介绍(主要)
类似于TensorFlow的可视化方式
pip install tensorboardX
命令行到日志路径,运行tensorboard --logdir ./指定log路径
from tensorboardX import SummaryWriter
writer = SummaryWriter('log')
for i in range(100):
writer.add_scalar('a',i,global_stype=1)
writer.add_scalar('b',i ** 2,global_stype=1)
writer.close()
Torchvision介绍
Torchvision是独立于pytorch的关于图像操作的一些方便的库,主要包含以下包:
- vision.datasets:几个常用视觉数据集,可以下载和加载
- vision.models:已训练好的模型,例如AlexNet,VGG,ResNet
- vision.transforms:常用的图像操作,例如随即切割,旋转,数据类型转换,图像到tensor,numpy数组到tersor,tensor到图像等
- vision.utils,visoion.io,cision.ops