机器学习实战-KNN算法-鸢尾花分类
from sklearn import neighbors
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import random
iris = datasets.load_iris()
print(iris)

data_size = iris.data.shape[0]
index = [i for i in range(data_size)]
random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
test_size = 40
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
model = neighbors.KNeighborsClassifier(n_neighbors=3)
model.fit(x_train, y_train)
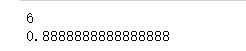
prediction = model.predict(x_test)
print(classification_report(y_test, prediction))
机器学习实战-KNN算法-水果分类
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
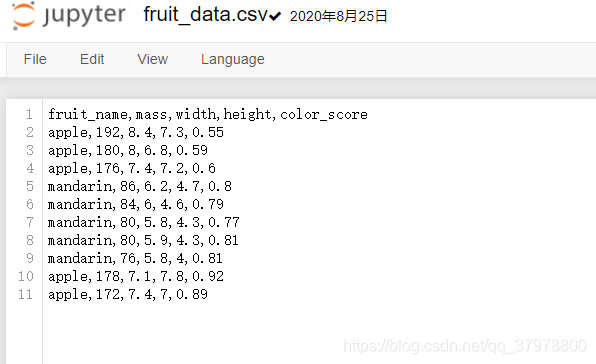
data = pd.read_csv('fruit_data.csv')
data

labelencoder = LabelEncoder()
data.iloc[:,0] = labelencoder.fit_transform(data.iloc[:,0])
data

labelencoder.classes_

from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(data.iloc[:,1:], data.iloc[:,0], test_size=0.3, stratify=data.iloc[:,0], random_state=20)
test_scores = []
train_scores = []
k = 30
for i in range(1,k):
knn = KNeighborsClassifier(i)
knn.fit(x_train,y_train)
test_scores.append(knn.score(x_test,y_test))
train_scores.append(knn.score(x_train,y_train))
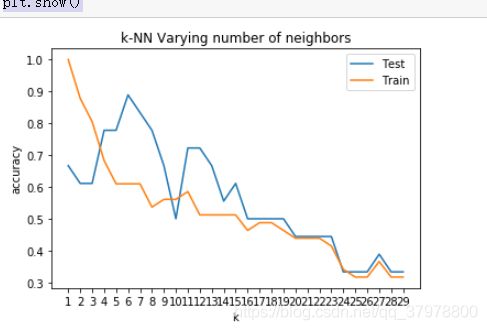
plt.title('k-NN Varying number of neighbors')
plt.plot(range(1,k),test_scores,label="Test")
plt.plot(range(1,k),train_scores,label="Train")
plt.legend()
plt.xticks(range(1,k))
plt.xlabel('k')
plt.ylabel('accuracy')
plt.show()
k = np.argmax(test_scores)+1
knn = KNeighborsClassifier(k)
knn.fit(x_train,y_train)
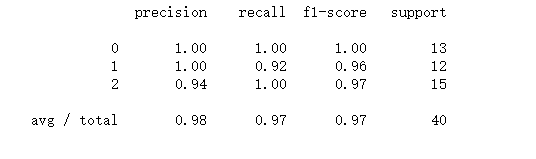
print(k)
print(knn.score(x_test,y_test))