图像分割总结
在DeepLab中,将输入图片与输出特征图的尺度之比记为output_stride,如输入图片是256*256,输出是16*16,那么output_stride为16。
这篇总结主要以梳理deeplab系列为主,除此之外图像分割领域还有很多的东西,推荐了一篇github上的总结
啥是图像分割
AI的图像领域工作,大致可以分为这么几个方向,图像分类、目标检测、图像分割,而图像分割又分为语义分割和实例分割。语义分割与实例分割的区别呢就是语义分割只分类别,不分个体,而实例分割呢,不但区分种类,而且区分个体,啥意思呢?如下图,语义分割只分类羊、狗、人,不分羊1、2、3...,但是实例分割呢,在分类的基础上,还要分割羊1,羊2.....。因此有一种对于实例分割的理解呢就是语义分割+目标检测,因为目标检测能够区分个体。
-
图像分类:判别图中物体是什么,比如是猫还是狗;
-
语义分割:对图像进行像素级分类,预测每个像素属于的类别,不区分个体;
-
目标检测:寻找图像中的物体并进行定位;
-
实例分割:定位图中每个物体,并进行像素级标注,区分不同个体;

其实AI发展到今天,已经很难将什么分类,检测,语义,完全的分割开,这么做也没啥实际意义。下图是目标检测中MASK-RCNN的网络结构,后面的three branches部分,对应的三个方面分别是语义、回归和分类。目标检测可以将其分割成两个部分,一个是分类一个是回归,分类得到框住的是什么东西,回归使框更加准确。MASK-RCNN中之所以加入了语义分割的部分,是因为语义分割能够较好的提高目标检测对于小目标的准确率。

基础知识点
空洞卷积
将深度学习卷积的思想应用到图像分割有一个很重要的问题
就是深度学习无论是检测还是分类,都会进行下采样,增加特征图的深度,降低他们宽高。但是下采样对于图像分割确不是很理想,因为图像分割需要对每一个像素进行分类,对位置信息要求很高,这个位置下的像素,如果分类正确了,位置搞错了,那他就是其他的像素,这也是不行的。因此将卷积运用到图像分割就遇到了一个很尴尬的情况,卷积一定伴随着下采样,以此获取像素点及其周围一片整体的信息,但这会造成像素在图像中位置信息的丢失。图像分割又必须尽可能的保留位置信息,这样才能保证每一个像素点都分类正确。为了解决这个问题就诞生了一种全新的卷积,空洞卷积(atrous convolution),这种卷积既能不进行下采样,丢失像素的位置信息,又能获取像素与周围像素的整体信息。这种卷积在DeepLab V1中首先被提出,在DeepLab之后的版本中也一直被使用。
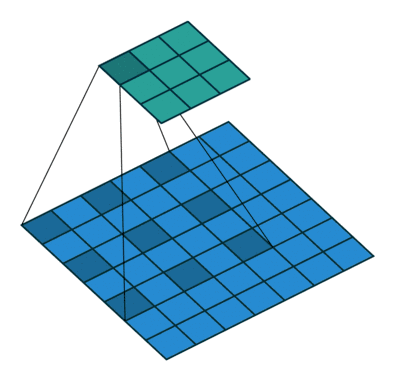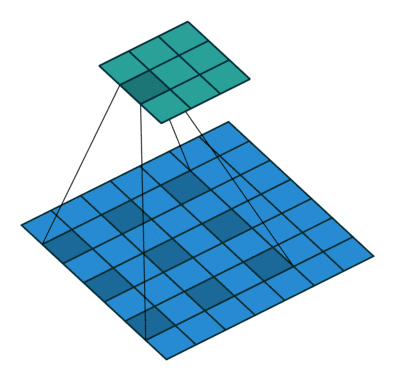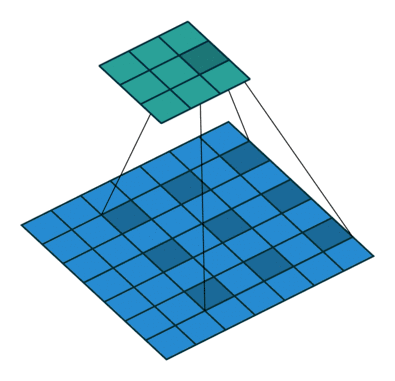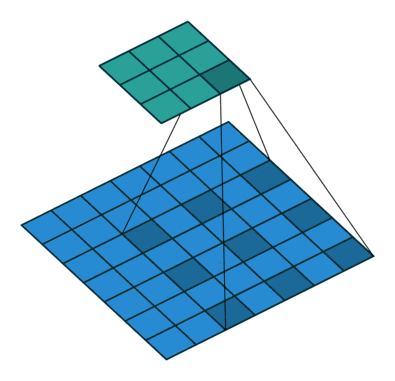
ASPP
想要解释清楚什么是ASPP,首先要解释清楚什么是SPP,因为ASPP完全是借鉴SPP的思想,对SPP的一个变种,或者说是SPP针对语义分割问题的一个调整

深度学习领域里存在一个问题,就是你输入给CNN的图像一定是固定尺寸大小的,但是由于你检测出的目标有长有宽,需要将检测出的有长有短,有大有小的图像进行调整,调整成相同的尺寸去进行分类。因此一开始遇到这种问题,大家的解决办法都是裁剪或者resize,但是裁剪会造成图像区域的丢失,而resize会造成长宽比的变化,这两种情况都会极大的丢失图像原有的信息。因此在深度学习领域诞生了一个方法,叫SPP(Spatial Pyramid Pooling),SPP得网络结构如下
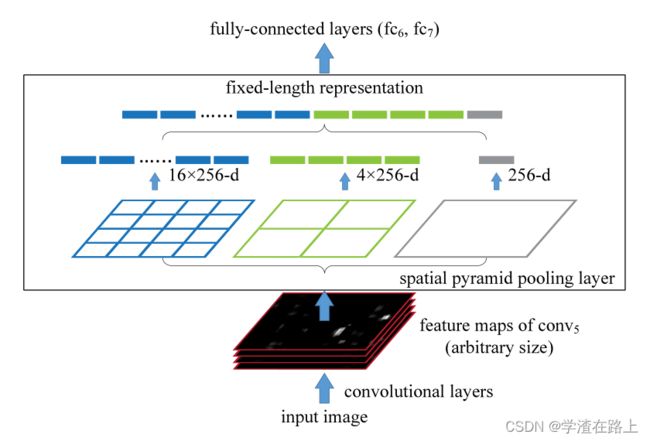
SPP就是一顿卷,卷到8*8之后,对这个特征图进行一次下采样得到一个4*4的特征图,然后再对4*4的特征图进行一次下采样,得到一个2*2的特征图,再对2*2的特征图进行一次下采样得到1*1的特征图,将得到的3个特征图拼接到一起,得到一个21(4*4+2*2+1*1)的特征向量,进行之后的操作。为啥这么做呢,1*1的特征图对应差不多原图那么大,2*2的每一个对应差不多图像的四分之一,以此类推,这样增加了,特征图到原始图像的对应比例,有助于解决深度学习问题中的尺度问题。
啥是ASPP(Atrous Spatial Pyramid Pooling)呢,ASPP就是Atrous的SPP。SPP中用了下采样,ASPP中使用空洞卷积代替了下采样操作,只是每次使用的空洞间隔不一样,以此来解决图像分割中的多尺度物体问题。
deeplab进化史
DeepLabv1:
deeplabv1的创新点,主要有两点,第一点是使用空洞卷积,第二点是使用全连接CRF
空洞卷积,

deeplabv1的算法流程

全联接CRF的效果

DeepLabv2:
空洞卷积是存在理论问题的,论文中称为gridding,其实就是网格效应/棋盘问题。因为空洞卷积得到的某一层的结果中,邻近的像素是从相互独立的子集中卷积得到的,相互之间缺少依赖。
-
局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。
-
远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果。
deeplabv2的创新点是借鉴了SPP的思想,将其移植到了图像分割领域,提出了ASPP思想。
使用不同rate的空洞卷积,代替原本SPP的下采样操作

不同rate的空洞卷积完成之后,进行拼接

DeepLabv3:
v3的主要创新点,如该论文的题目一样rethinking atrous convolution,重新思考了一下。论文中拿掉了之前的全连接CRF,更加侧重空洞卷积的使用,这个位置也是可以理解的,深度学习的发展方向还是越来越黑的。
v3将原本单一方向的空洞卷积增加为两个方向的卷积,类似效果如下图,原本v2得到一个特征图block4后,会将这个特征图复制成四份,分别作rate=6、rate=12......的空洞卷积,如下方左图,但是现在会在复制出的特征图上做多个空洞卷积(左侧这个图并不完全准确,只是表达会做很多个卷积的一个思想),具体的卷积尺度是由Multi-grid Method决定的。

multi-grid 作者考虑了multi-grid方法,即每个block中的三个卷积有各自unit rate,例如Multi Grid = (1, 2, 4),block的dilate rate=2,则block中每个卷积的实际膨胀率=2* (1, 2, 4)=(2,4,8)
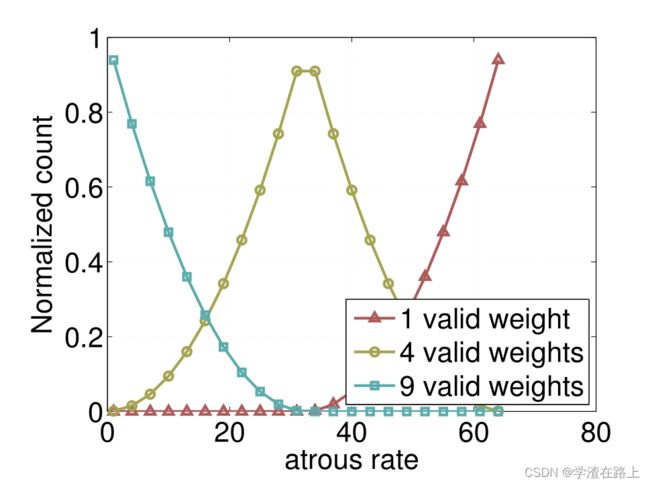
这个方法确定之后呢,作者通过实验发现,膨胀率越大,卷积核中的有效权重越少,当膨胀率足够大时,只有卷积核最中间的权重有效,即退化成了1x1卷积核,并不能获取到全局的context信息。3x3的卷积核中有效权重与膨胀率的对应如下:
因此作者将原本对于每个Block简单的多个空洞卷积的结构,更改为

DeepLabv3+:
v3+在v3的基础上,进行了两点改变,
第一点改变,结合了Encoder-Decoder结构,得到的新的算法结构,如下图
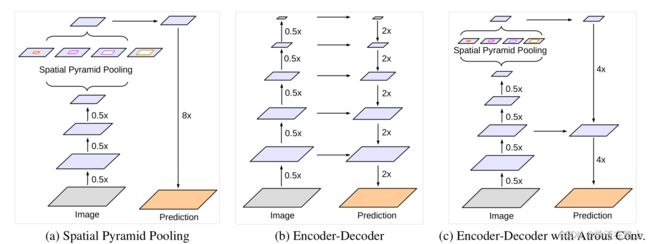
详细的算法结构如下,其中Encoder就是v3

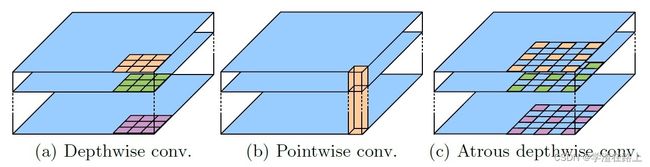
第二点改变把Xception和Depthwise separable convolution应用到Atrous Spatial Pyramid Pooling和decoder中。
相信了解过mobilenet网络结构的读者,都会知道啥是Depthwise separable convolution,作用是干啥的呢,就是提速的。
论文地址
SPP-NET: https://arxiv.org/pdf/1406.4729.pdf
DeepLabv1: https://arxiv.org/pdf/1412.7062v3.pdf
DeepLabv2: https://arxiv.org/pdf/1606.00915.pdf
DeepLabv3: https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+: https://arxiv.org/pdf/1802.02611.pdf
Xception: Deep Learning with Depthwise Separable Convolutions https://arxiv.org/abs/1610.02357
相关推荐
这是github上的一篇总结,别的不多说,就放两张里面的截图吧
https://github.com/mrgloom/awesome-semantic-segmentation


参考
https://mp.weixin.qq.com/s?__biz=MzUyMjE2MTE0Mw%3D%3D&mid=2247492453&idx=1&sn=1a9e42283a3f3b311d60fd356ed8b1f2&scene=45#wechat_redirect
语义分割模型之DeepLabv3+ - 知乎
图像分割三-DeepLab V1~4 - 知乎