Hadoop完全分布式实现WordCount
动手实现一下WordCount:

既然Hadoop搭建好了,那就体验一下分布式,玩起来呗!
运行前提:
- 搭建好你的Hadoop集群 ,结构如下:
- Master
- Slave1
- Slave2
可以参考我写的搭建教程,跟着我的步骤来就行:hadoop分布式搭建
确保你的分布式实例运行成功了,再往下看
WordCount源码:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
-
cv一下源码然后执行一下代码
-
依次执行一下命令 :
cd ~
mkdir wordcount
cd wordcount
sudo vim WordCount.java
Ctrl+V
等等,在你准备大展拳脚的时候,请你先把hadoop启动了先!!!
- 启动hadoop
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
编译、打包 Hadoop MapReduce 程序
我们将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
- 再执行
source ~/.bashrc
- 编译
javac WordCount.java

- 打包class文件
jar -cvf WordCount.jar ./WordCount*.class
编写自定义文本
随便写一点用来统计的文本,英文文本 , 随便你写
- 我的文件如下:

我在code文件夹里写的,你直接在wordcount文件夹下执行上述命令就行
echo 是shell的变量定义,后面跟的是一个字符串,把这个字符串放入input文件下file0文件
当然你也可以随意的写内容
cd input
sudo vim file0
sudo vim file1

写个小短文
sudo vim file2
In a 2011 report from the renowned consulting firm McKinsey, "Big data" is regarded as "the next frontier for innovation, competition and productivity".
You may have heard this buzzword for numerous times and even have been astonished by a variety of its applications from the marketing case "beer and diaper" to the Google Flutrends.
Admittedly, big data technology is profoundly changing the modern business and industry.
However, I want to remind you as well as myself of "the right we have forgotten", as big data pioneer Mayer-Sch?nberger puts it.
With big data technology permeating gradually, your data, including browser history, tweets, or even credit card payment record, will tag you an ID, on which your character is based.
For instance, IBM experts recently claim that they can abstract a person's personal information like personality, hobbies by means of just analyzing 150 tweets he or she sent.
Another example we are familiar with is online shopping.
Websites like Taobao and Amazon all have data analytic group focusing on machine learning to promote commodities to customers automatically and intelligently.
It was once talked with popularity that a father received a can of milk powder as a gift from an online shopping website, but he was confused for he already had a daughter who was 18 years old.
Out of curiosity, he asked the website servants why they had sent him milk powder.
It turns out that this seemingly stupid gift decision is based on his daughter's credit card records on the website, where she had looked up to and bought some baby supplies in the last few months, and she was pregnant with his father not knowing it.
In the future, there is no doubt that your data will accompany you with your sorrows as well as joys, whether you like it or not.
上传到hdfs
# 把本地文件上传到分布式HDFS上
/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input output
你要是这一步就成功了,就没问题啦 ~
我的小短文统计结果:
"Big 1
"beer 1
"the 2
150 1
18 1
2011 1
Admittedly, 1
Amazon 1
Another 1
Flutrends. 1
For 1
Google 1
However, 1
I 1
IBM 1
ID, 1
In 2
It 2
Mayer-Sch?nberger 1
McKinsey, 1
Out 1
Taobao 1
Websites 1
With 1
You 1
a 7
abstract 1
accompany 1
all 1
already 1
an 2
analytic 1
analyzing 1
and 8
applications 1
are 1
as 7
asked 1
astonished 1
automatically 1
baby 1
based 1
based. 1
been 1
big 3
bought 1
browser 1
business 1
but 1
buzzword 1
by 2
can 2
card 2
case 1
changing 1
character 1
claim 1
commodities 1
competition 1
confused 1
consulting 1
credit 2
curiosity, 1
customers 1
data 5
data" 1
data, 1
daughter 1
daughter's 1
decision 1
diaper" 1
doubt 1
even 2
example 1
experts 1
familiar 1
father 2
few 1
firm 1
focusing 1
for 3
forgotten", 1
from 3
frontier 1
future, 1
gift 2
gradually, 1
group 1
had 3
have 4
he 4
heard 1
him 1
his 2
history, 1
hobbies 1
in 1
including 1
industry. 1
information 1
innovation, 1
instance, 1
intelligently. 1
is 6
it 1
it. 2
its 1
joys, 1
just 1
knowing 1
last 1
learning 1
like 3
looked 1
machine 1
marketing 1
may 1
means 1
milk 2
modern 1
months, 1
myself 1
next 1
no 1
not 1
not. 1
numerous 1
of 5
old. 1
on 4
once 1
online 2
or 3
out 1
payment 1
permeating 1
person's 1
personal 1
personality, 1
pioneer 1
popularity 1
powder 1
powder. 1
pregnant 1
productivity". 1
profoundly 1
promote 1
puts 1
received 1
recently 1
record, 1
records 1
regarded 1
remind 1
renowned 1
report 1
right 1
seemingly 1
sent 1
sent. 1
servants 1
she 3
shopping 1
shopping. 1
some 1
sorrows 1
stupid 1
supplies 1
tag 1
talked 1
technology 2
that 4
the 8
there 1
they 2
this 2
times 1
to 5
turns 1
tweets 1
tweets, 1
up 1
variety 1
want 1
was 4
we 2
website 1
website, 2
well 2
where 1
whether 1
which 1
who 1
why 1
will 2
with 4
years 1
you 4
your 4
Bug记录&解决 :
当然bug无法避免哦,来一起Debug !!!
hadoop运行报错
- bug 1
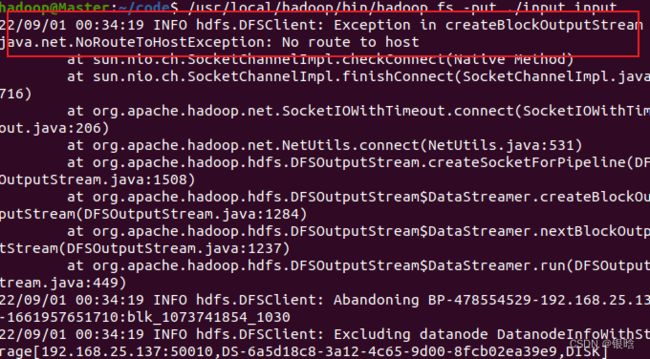
hadoop没开,或者连接失败,回去重启
- bug2
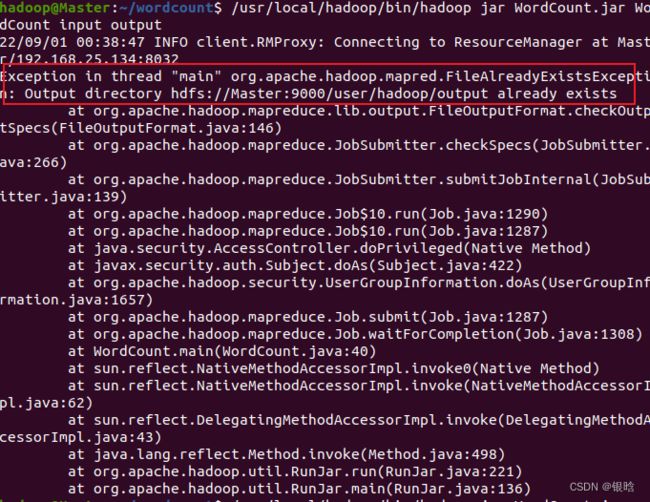
之前跑分布式实例已经创建了一个output,所以要再指定一个输出的文件夹
/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input output/wc
- bug3
程序能执行完,但是error不断!
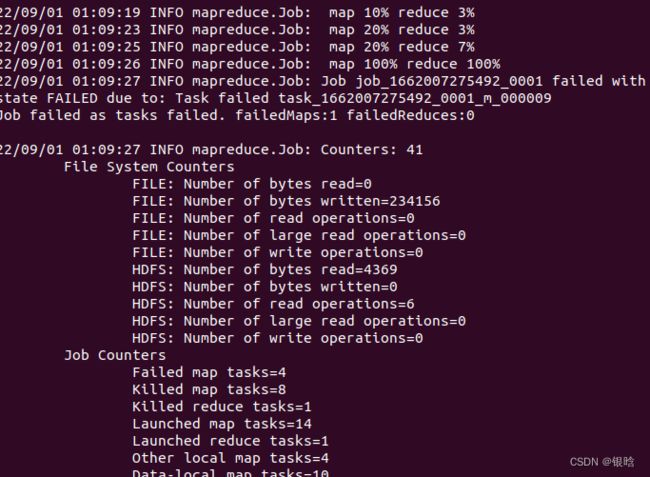
- 找到这里

解决完输出,发现输入又有问题,呜呜呜
- 先把输出删了,不然又得报错
hdfs dfs -rm -r output/wc
我找了找输入,然后我找到了!
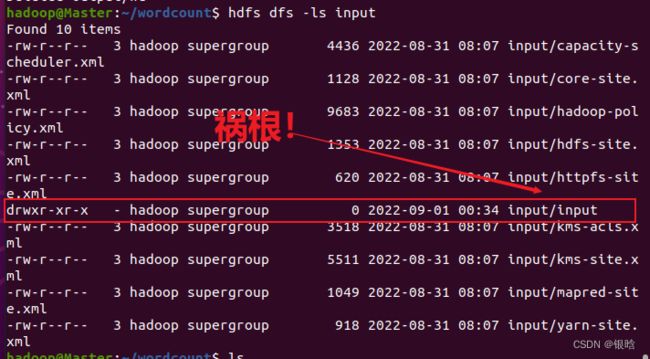
- 重新执行启动命令
/usr/local/hadoop/bin/hadoop jar WordCount.jar org/apache/hadoop/examples/WordCount input/input output/wc
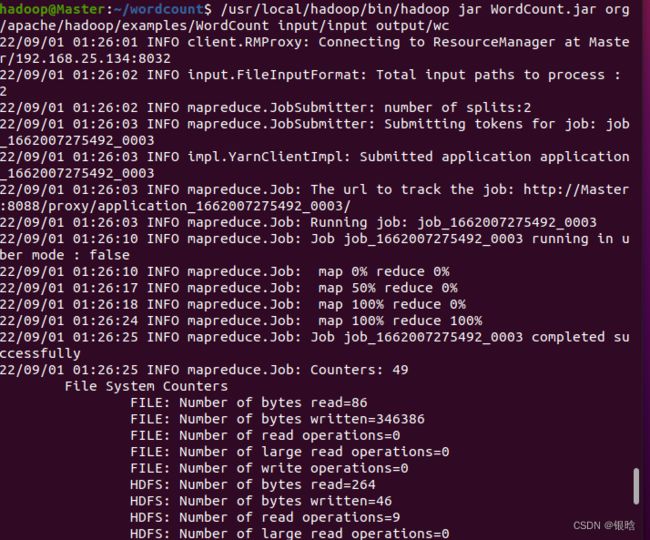

看上去一切正常,看看输出
hadoop fs -cat /user/hadoop/output/wc/part-r-00000

okay ,词频统计结果出来了,你的第一个MapReduce程序应该算是成功了!
Summary
Bugs只会帮助你更深入的学习到平时学不到的地方,你的bug比别人多,解决它,日积月累下来,coding的差距藏在Bug里
下期预告
似乎命令行有点不爽,又上高级的编译器呗,ojbk!
- 我遇到了一点错误,等我解决了,再来偷偷告诉你哈哈哈哈哈哈哈
Call me
有问题 call me !!!
-> 我是裤裤的Boy : [email protected]
