PyTorch-Kaldi 深度学习语音识别开源软件
PyTorch-Kaldi 深度学习语音识别开源软件
论文:Ravanelli M (Mirco Ravanelli), Parcollet T, Bengio Y. The Pytorch-kaldi Speech Recognition Toolkit. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 6465–6469.
GitHub:https://github.com/mravanelli/pytorch-kaldi
SpeechBrain 是 PyTorch-Kaldi 的进阶版,使用 All-in-One PyTorch 的模式。
语音识别与说话人识别的区别:相比较说话人识别,语音识别的流程更加复杂,额外需要内容相关的标签和解码方法。
文章目录
- PyTorch-Kaldi 深度学习语音识别开源软件
-
- 摘要
- 引言
- PyTorch-Kaldi 项目
-
- 配置文件
- 特征
- 标签
- 分块与小批量组成
- 神经网络声学建模
- 解码与评分
- 实验设计
- 基准性能
- 参考文献
-
- 语料
- 模型
- 开源软件
摘要
Kaldi 是 C++ 实现的语音识别软件,缺少像 Python 的简单与灵活。PyTorch-Kaldi 旨在构建 Kaldi 与 PyTorch 之间的联系,充分利用 Kaldi 高效性与 PyTorch 灵活性。PyTorch-Kaldi 除了建立 Kaldi 与 PyTorch 之间的联系,还嵌入了非常有用的功能,用于开发最新的语音识别器。程序易于加入自定义的声学模型,包含初始化方法和预执行的模型。PyTorch-Kaldi 支持多个特征和标签流、神经网络组合的建模。程序已公开发布在 Github,适用于运行在本地和高性能计算集群上。
引言
近十年,自动语音识别(Automatic Speech Recognition, ASR)迎来了飞速的发展。深度学习技术开始克服传统高斯混合模型(Gaussian Mixture Models, GMMs)的不足,在众多数据集上表现出优异的性能,例如 TIMIT、AMI、DIRHA、CHiME、Babel 和 Aspire。
语音识别开源软件的发展,诸如 HTK、Julius、CMU-Sphinx、RWTH-ASR、LIA-ASR 和 2011 年以后的 Kaldi,极大地推进了 ASR 的发展,为研究的进行和应用的开发提供了便利。
Kaldi 是目前非常流行的 ASR 工具,它提供一系列 C++ 库。
深度学习框架,例如 Theano、TensorFlow、CNTK 和 PyTorch,为 ASR 机器学习系统的发展提供了帮助。这些软件提供了灵活的神经网络设计模式和大量的深度学习应用。
PyTorch 是 Python 语音的 GPU 加速软件,自动梯度工具使其是用于高效地深度学习应用开发。
PyTorch-Kaldi 建立了 Kaldi 与 PyTorch 之间的桥梁。该软件使用 PyTorch 执行声学建模,使用 Kaldi 执行特征提取、标签/对齐、编码等,是用于 DNN-HMM 框架的 ASR 系统。
PyTorch-Kaldi 能够部署在本地机器和高性能计算机上,支持多 GPU 训练、恢复策略、自动数据分块。
PyTorch-Kaldi 项目
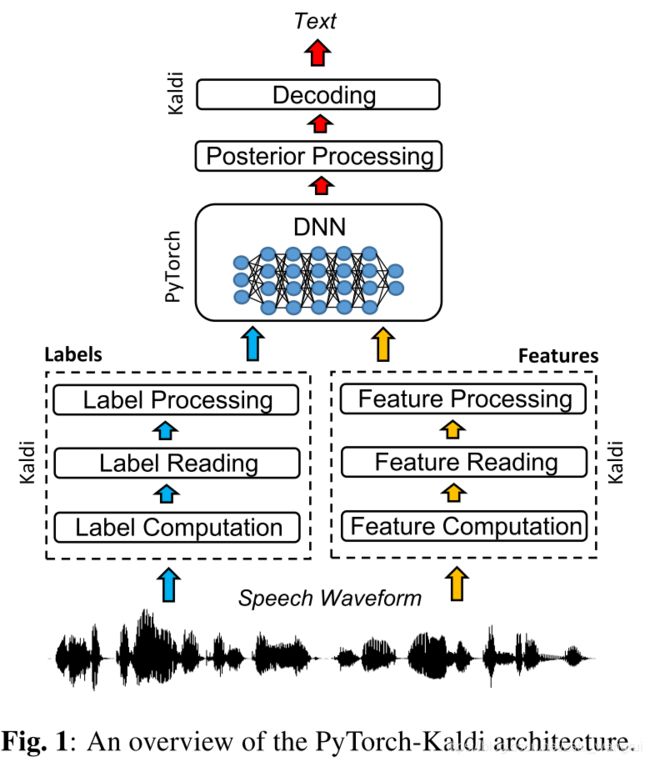
PyTorch-Kaldi 是 Python 语言开发的基于 Kaldi 和 PyTorch 的 ASR 工具。类似地,PyKaldi 是 Kaldi 的 Python 包装,未提供神经网络建模方法;ESPnet 仅支持 ASR 端到端建模,训练的设计需要非常细心。
Fig. 1 描述了 PyTorch-Kaldi 的框架,Kaldi 执行特征提取与语音解码,PyTorch 执行神经网络建模与后处理。主要脚本 run_exp.py 管理 ASR 系统所有的组成成分,包括:特征与标签提取、训练、验证、解码和评分。
配置文件
配置文件采用 INI 格式,用于 run_exp.py:
-
[Exp]:高层次信息,例如文件夹、训练的次数、随机种子、执行 CPU/GPU/多 GPUs 等;
-
[dataset*]:特征与标签的信息(存储的路径、上下文窗口的特效、语音数据划分的 chunks 数量)等;
-
[architecture*]:神经网络模型的描述;
-
[model]:神经网络如何结合;
-
[decoding]:定义解码参数;
-
其他。
该项目采用 *.cfg 文件定义配置文件,例如
# Source: https://github.com/mravanelli/pytorch-kaldi/blob/e06682f9b23ca453b2c3fc35bc474e0617a6cc80/cfg/TIMIT_baselines/TIMIT_MLP_mfcc_basic.cfg
[cfg_proto]
cfg_proto = proto/global.proto
cfg_proto_chunk = proto/global_chunk.proto
[exp]
seed = 1234
use_cuda = True
multi_gpu = False
[dataset1]
data_name = TIMIT_tr
n_chunks = 5
[dataset2]
data_name = TIMIT_dev
n_chunks = 1
[dataset3]
data_name = TIMIT_test
n_chunks = 1
[data_use]
train_with = TIMIT_tr
valid_with = TIMIT_dev
forward_with = TIMIT_test
[batches]
batch_size_train = 128
max_seq_length_train = 1000
[architecture1]
arch_name = MLP_layers1
[model]
model_proto = proto/model.proto
[forward]
forward_out = out_dnn1
[decoding]
decoding_script_folder = kaldi_decoding_scripts/
特征
特征模块由 Kaldi 实现,主要功能是提取特征,提供多个特征流的管理功能
- 计算系数,存储为 ark,例如 mfcc、fbank、plp;
- kaldi-io 实现 chunk 读取;
- 执行上下文窗口合成,混洗以及均值和方差归一化。
标签
标签主要用于神经网络声学建模,来自于 Kaldi 计算的语音特征和内容相关音素状态的序列。该模块可提供多标签,支持多任务学习。例如联合训练内容相关和内容无关的目标,执行单音正则化;语音增加和语音识别联合训练;合作网络深度学习。
分块与小批量组成
分块与小批量合成,由 core.py 中 run_nn 函数实现:
-
数据划分为多块,每块由标签和特征组成;
-
每块存入 cpu 或者 GPU,
-
训练阶段,动态地组合不同的块形成小批量数据,其中小批量由少量的样本组成。
训练时的组合方法因网络结构而异:
-
前馈网络的小批量:从块中随机采样的、混序的特征与标签组成;
-
循环网络的小批量:由完整的句子组成,不同时长的句子进行零补长,形成相同长度。
PyTorch-Kaldi 对句子进行增序排列(有助于最小化零补长,减少对 batch normalization statistics 影响)。
神经网络声学建模
DNN 声学建模,包含前馈网络和训练网络,由 neural_networks.py 实现:
-
自定义模型:nn.Module,初始化方法,前向方法;
-
预训练模型:MLPs、CNN、RNN、LSTM、GRU、Light GRU、twin-regularized RNNs、SincNet。
解码与评分
编码与评分:
-
神经网络输出的概率先经过先验归一化,
-
HMM 编码器利用 n-gram 语言模型进行评分估计,
-
beam搜索提取文字序列,
-
NIST SCTK 评分工具箱计算 Word-Error-Rate (WER) 得分。
实验设计
语料与任务:
-
语料:TIMIT、DIRHA-English、WSJ、CHiME 4、ET-real、DT-real、LibriSpeech。
-
任务:标准音素识别任务、远距离说话场景、四种噪声环境(公交、咖啡厅、住宅区、街道拥堵)。
神经网络设定:
-
特征:MFCC、fbanks、fMLLR,25 ms frame,10 ms hop;
-
前馈模型权重初始化 Glorot 策略 [38],循环模型权重初始化正交矩阵 [39];
-
前馈连接 batch normalization,循环结构 dropout 正则技术;
-
优化器 RMSprop,24 epochs;
-
学习速率变化:性能相对改进低于 0.1% 之后学习速率减少一半;
-
超参数调试:学习速率、隐藏层数量、隐藏层单元数、dropout 因子、twin 正则项参数。
基准性能
实验使用的数据集有 4 个:TIMIT、DIRHA、CHiME 与 LibriSpeech。表 1-4 描述了 TIMIT 数据集上的性能,表 5 对比了其他三个数据集的性能。性能评价指标:PER (Phone Error Rate) 与 WER (Word Error Rate)。结论如下:
- 表 1 中 fMLLR 特征性能最佳,得益于说话人自适应过程,Li-GRU 减少 GRU 33% 计算量,且优于 GRU。
- 表 2 Incr. Seq. Length 鼓励学习短期依赖,然后再学习长期依赖。
- 表 3 表明特征组合和模型组合实现了 TIMIT 最好的公开性能。
- 表 4 测试在原始信号或者 FBANK 上的性能,SincNet 优于 CNN。
- 表 5 表明 Li-GRU 实现了最优的性能,相比较 CHiME 的 Kaldi 18.1% WER 与 ESPNet 44.99% WER;相比较 Librispeech 的 Kaldi 6.5%。
| 模型/特征 | MFCC | FBANK | fMLLR |
|---|---|---|---|
| MLP | 18.2 | 18.7 | 16.7 |
| RNN | 17.7 | 17.2 | 15.9 |
| LSTM | 15.1 | 14.3 | 14.5 |
| GRU | 16.0 | 15.2 | 14.9 |
| Li-GRU | 15.3 | 14.9 | 14.2 |
| 技术/模型 | RNN | LSTM | GRU | Li-GRU |
|---|---|---|---|---|
| Baseline | 16.5 | 16.0 | 16.6 | 16.3 |
| + Incr. Seq. Length (从 1s 语音开始,逐步增加(两倍/epoch)裁剪的语音长度) | 16.6 | 15.3 | 16.1 | 15.4 |
| + Recurrent Dropout | 16.4 | 15.1 | 15.4 | 14.5 |
| + Batch Normalization | 16.0 | 14.8 | 15.3 | 14.4 |
| + Monophone Reg. (两个 softmax 分类器,估计内容相关的状态和预测单音目标) | 15.9 | 14.5 | 14.9 | 14.2 |
| 结构 | 特征 | PER (%) |
|---|---|---|
| Li-GRU | fMLLR | 14.2 |
| MLP+Li-GRU+MLP | MFCC+FBANK+fMLLR | 13.8 |
| 模型 | 特征 | PER (%) |
|---|---|---|
| CNN | FBANK | 18.3 |
| CNN | Raw waveform | 18.1 |
| SincNet | Raw waveform | 17.2 |
| 模型/数据 | DIRHA | CHiME | LibriSpeech |
|---|---|---|---|
| MLP | 26.1 | 18.7 | 6.5 |
| LSTM | 24.8 | 15.5 | 6.4 |
| GRU | 24.8 | 15.2 | 6.3 |
| Li-GRU | 23.9 | 14.6 | 6.2 |
参考文献
语料
- Ravanelli M, Cristoforetti L, Gretter R, et al. The DIRHA-ENGLISH corpus and related tasks for distant-speech recognition in domestic environments. 2015 IEEE Workshop on Automatic Speech Recognition and Understanding, ASRU 2015 - Proceedings. 2016.
- Barker J, Marxer R, Vincent E, et al. The third “CHiME” speech separation and recognition challenge: Dataset, task and baselines. 2015 IEEE Workshop on Automatic Speech Recognition and Understanding, ASRU 2015 - Proceedings. 2016.
- 有噪声的语料: Ravanelli M, Svaizer P, Omologo M. Realistic multi-microphone data simulation for distant speech recognition. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 2016, 08-12-September-2016: 2786–2790.
模型
- Li-GRU: Ravanelli M, Brakel P, Omologo M, et al. Light Gated Recurrent Units for Speech Recognition. IEEE Transactions on Emerging Topics in Computational Intelligence, 2018.
- Ravanelli M, Bengio Y. Speaker Recognition from Raw Waveform with SincNet. 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2018: 1021–1028.
开源软件
- Ravanelli M, Parcollet T, Bengio Y. The Pytorch-kaldi Speech Recognition Toolkit. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 6465–6469.
- Can D, Martinez V R, Papadopoulos P, et al. Pykaldi: A python wrapper for kaldi. ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings. 2018, 2018-April: 5889–5893.
- Watanabe S, Hori T, Karita S, et al. ESPNet: End-to-end speech processing toolkit. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH. 2018, 2018-Septe: 2207–2211.
- Povey D, Boulianne G, Burget L, et al. The Kaldi speech recognition toolkit. IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. 2011(January).
作者信息:
-
CSDN:https://blog.csdn.net/i_love_home?viewmode=contents
-
Github:https://github.com/mechanicalsea
2019级同济大学博士研究生 王瑞 [email protected]
研究方向:说话人识别、说话人分离