复现Oriented R-CNN RTX 2080Ti
2022年4月5日15点00分
1.conda新环境
conda create -n obbdetection python=3.7 -y
source activate obbdetection
装pytorch(这一步我不确定是否必要,我选autodl的GPU的时候自带了pytorch,以后有机会再验证吧)
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
2.clone .git and install
git clone https://github.com/jbwang1997/OBBDetection.git --recursive
cd OBBDetection
如果在clone BboxToolkit卡住了,可以cd到OBBDetection文件夹执行:
git clone https://github.com/jbwang1997/BboxToolkit.git --recursive
再安装BboxToolkit
cd BboxToolkit
pip install -v -e . # or "python setup.py develop"
cd ..
安装mmcv
pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html --no-cache-dir
提示报错,会显示很多版本,我选的1.4.0
然后安装成功显示:
Successfully installed addict-2.4.0 mmcv-full-1.4.0 pyyaml-6.0 yapf-0.32.0
安装OBBDetection
pip install -r requirements/build.txt
pip install mmpycocotools
pip install -v -e . # or "python setup.py develop"
2022年4月5日15点27分
大约5分钟完成,显示
Successfully installed Pillow-6.2.2 mmdet-2.2.0+4c779ba
3. test model
先去网上下载他训练好的模型(.pth文件)
https://github.com/jbwang1997/OBBDetection/tree/master/configs/obb/oriented_rcnn
然后上传到GPU服务器上进行测试
python demo/huge_image_demo.py demo/dota_demo.jpg configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_1x_ms_rr_dota10.py ckpt/faster_rcnn_orpn_r101_fpn_1x_mssplit_rr_dota10_epoch12.pth BboxToolkit/tools/split_configs/dota1_0/ss_test.json
如果不能显示图形界面,plot画不出图来,他没有保存图像文件的代码。我的Linux看不了。调了半小时,找到了mmdet/apis/inference.py,最后一行加入
cv2.imwrite("xxxx320.jpg", img)
到时候运行完会在/root/OBBDetection文件夹下生成处理完的结果xxxx320.jpg
4.针对HRSC2016数据集测试、训练。
4.1 准备数据集
数据集放到
/root/OBBDetection/data/HRSC2016
修改训练的数据集路径文件在configs/obb/base/datasets/hrsc.py
完成之后
4.2开始训练
python tools/train.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py --work-dir work_dirs
woc ,居然成功了,直接挂起来吃饭去。
nohup python tools/train.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py --work-dir work_dirs >xxxcbtrain202204051625.log 2>&1 &
2022年4月5日16点27分
一个小时后来检查发现空间不足了,我的存储空间只有20GB,
删掉之前生成的的24个epochs的pth文件,接着25轮继续,因为26轮的epoch26.pth是个坏掉的文件,运行会报错。
python tools/train.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py --work-dir work_dirs --resume-from work_dirs/epoch_25.pth
断掉的过程中我也对25轮的精度进行了测试:
python tools/test.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py /root/OBBDetection/work_dirs/epoch_25.pth --eval mAP
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 444/444, 7.8 task/s, elapsed: 57s, ETA: 0s
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 2999 | 0.9857 | 0.9047 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9047 |
+-------+------+------+--------+--------+
再用vac12运行一遍
python tools/test.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py /root/OBBDetection/work_dirs/epoch_25.pth --eval mAP --options use_07_metric=False
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 2999 | 0.9857 | 0.9748 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9748 |
+-------+------+------+--------+--------+
巧了,效果非常理想。
达到官方的精度了
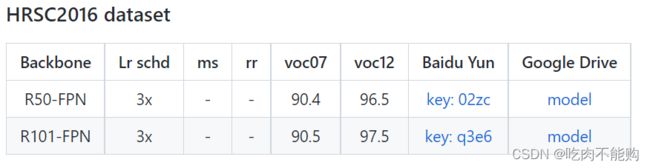
接着把剩下的11轮跑完吧。
36epoch的结果如下
4.3 效果检验
voc07
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 3162 | 0.9840 | 0.9050 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9050 |
+-------+------+------+--------+--------+
voc12
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 3162 | 0.9840 | 0.9740 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9740 |
+-------+------+------+--------+--------+
最后的效果比较理想。
测试两张船。
python demo/image_demo.py demo/100001132.bmp configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py work_dirs/epoch_36.pth
总结
上一次复现失败的原因大概是pytorch版本太高了,调用mmdetection框架出错了,这次碰巧没遇到错误。
也学会了从中断的地方恢复训练,效果比较不错,下次复现S2ANet了。
本次复现共耗时一个半小时,消费3块钱,算上上次失败和之前改错的成本,累计时间一周,20块钱。