不会还有人不会c语言基础吧!超级详细(嵌入式从0开始)
前言
一个计算机小白的C语言学习之路,适合0基础的小白们,宝子们一起加油努力!
本篇使用的是Linux中的gcc编译器,
C语言简介
进制数
计算机数据的表示方式
数据表⽰
1. ⾮移位型数据
每个符号就表⽰对应的数据,如:⼗、⼆、 V 、 VI
每个符号都是表示固定的值
2. 移位型数据
每个符号在不同的位置表⽰的数据⼤⼩不同,如: 20 、 200
2在十位表示20,在百位表示200
计算机虽然只有通、断电(即0 、 1 ),可以通过多个通断电状态来表⽰
⼀个数据值(多个0 和 1 表⽰,每个 0 和 1 在不同的位置表⽰的数据⼤⼩不
同)
计算机数据存储
由于移位型数据的特点可以⽤于在计算机中⽤来表⽰数据,即位不同表⽰数
据值不同,就是我们所说的 进位计数制数 ( 进制数 ), 是⼈为定义的带进位的计
数⽅法 。
计算机中只认识0 和 1, 所以采⽤⼆进制
二进制
每⼀位只有0 和 1, 对应的位不同表⽰的⼤⼩不同 ( 2^n ,最低位 n=0 ) , 逢⼆进
位⼀ 比如:001010101010
十进制
十进制就是我们平时用的阿拉伯数字0~9,到了10就向前进位
二进制与十进制的转换
(一)⼗进制转⼆进制
把⼗进制数 除以 ⼆ ,最先进⾏除法的余数作为最低位
⼗进制数 35 转⼆进制
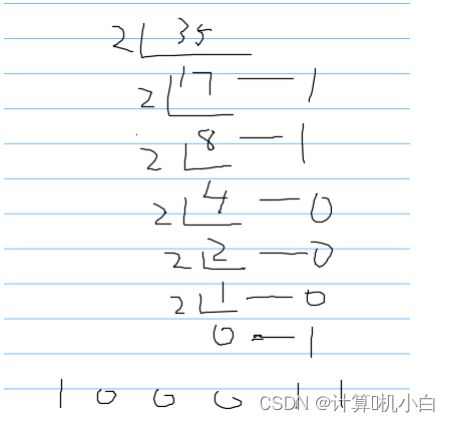
(二)⼆进制转⼗进制
权值:以进制作为底,以当前的位数作为幂,作为对应位的权值
把⼆进制数的每⼀位乘以当前位的权值,最后把所有位的结果相加

八进制
每⼀位只能出现0 〜 7, 共⼋个数据值,逢⼋进⼀,进位的 1 代表低位的 8 ,每⼀
位代表8^n
(一)十进制转八进制
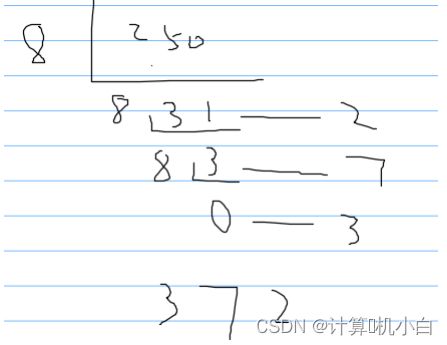
直接除以8
(二)八进制转十进制

每一位乘以8的权值
(三)二进制转八进制
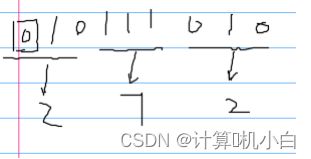
每三位二进制对应的是一位八进制,转换的时候直接三位变一位
(四)八进制转二进制
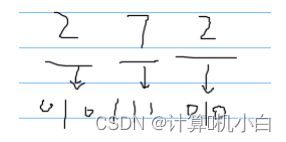
同上一位八进制转换为三位二进制
十六进制
每⼀位数值 0-15, 但是 10 、 11 、 12 、 13 、 14 、 15 占⽤ 2 位,需要⽤特殊的
字⺟来代替(可以使⽤ 1 位 ) 表⽰
A-----10
B------11
C------12
D------13
E------14
F------15
⼗六进制:0 、 1 、 2 、 3 、 4 、 5 、 6 、 7 、 8 、 9 、 A 、 B 、 C 、 D 、 E 、 F ,逢⼗
六进⼀,⾼位的1 代表低位的 16 ,每⼀位的值应该位 16^n
(一)十六进制转十进制

直接除16
(二)十进制转十六进制

每位乘以16的权值
(三)十六进制转二进制

十六进制与二进制是一位对应四位
(四)二进制转十六进制

四位对应一位
什么是计算机程序
计算机程序就是为了告诉计算机 做某个事情或解决某个问题 ⽽设计编写的指
令的集合
只需要让执⾏程序,计算机就会⾃动的进⾏⼯作,根据程序的内容执⾏操
作。计算机的⼀切操作都是依靠程序进⾏控制的。
计算机只能识别⼆进制,程序最终的形式为⼆进制代码
计算机每做⼀件事情就是⼀条指令, ⼀条或多条指令的集合就是计算机程
序 。
计算机语言
由于计算机只能识别⼆进制,需要把我们说的话转换为计算机能够识别的语
⾔(⼆进制)。如果计算机同时掌握了⼏⼗门语⾔甚⾄上百门语⾔,只要我
们使⽤任何⼀门语⾔计算机都能听得懂(转换为⼆进制),就可以和计算机
交流。
计算机语⾔:就是计算机能够识别看得懂且能够转换为⼆进制执⾏指令的语
⾔,就叫做计算机语⾔
常见的计算机语言
1. 机器语⾔
所有的指令中只有 0 和 1 , 0 表⽰断电, 1 表⽰通电
优点:直接对硬件产⽣作⽤,程序的执⾏效率很⾼ 缺点:指令⼜多⼜难记,可读性差
2. 汇编语⾔
符号化机器语⾔,⽤⼀个符号(单词、数字)来表⽰⼀个机器指令
优点:直接产⽣作⽤,程序执⾏效率⽐较⾼,可读性稍好
确定:符号记忆
3. ⾼级语⾔
⾮常接近⾃然语⾔,语法和结构类似于普通英语
优点:简单、易⽤、易于理解
缺点:有些⾼级语⾔写出的程序执⾏效率并不
C语言的基本概念
C 语⾔是⽤于和计算机交流的⾼级语⾔,就是⼀种计算机能够识别翻译成计算
机需要执⾏的⼆进制指令
⾮常接近⾃然语⾔,按照⼈书写的⽅式进⾏编写,需要通过翻译变成机器能
够识别的机器语⾔, C 语⾔就是⽅便⼈进⾏查看编写。编译后给机器查看
程序的执⾏效率⽐较⾼
C语言程序结构
对于计算机程序,就是功能指令的集合,如果使⽤ C ⾼级语⾔写出对应的指令
(功能),怎么执⾏,按照什么顺序执⾏,从哪⾥执⾏, C 语⾔都做了规定,
要满⾜ C 语⾔的语⾔规则
1. C 语⾔程序就要规定从哪⾥开始执⾏,执⾏哪些功能,需要存在程序的执
⾏⼊⼝
⼊⼝:

2. 编译器
每⼀门⾼级语⾔都有⼀个针对当前语⾔的翻译⼯具,把对应语⾔的程序
(使⽤对应语⾔想让计算机执⾏的指令集合)翻译成计算机识别的⼆进
制指令
C 语⾔程序(⽤ C 语⾔写出的指令集合)的翻译⼯具,就叫做 C 语⾔编译
器
编译器: gcc
gcc ⽂件名 .c
⽣成 a.out ⽂件 ---a.out ⽂件就是对应的⼆进制⽂件
C 语⾔程序结构 执⾏程序:
./a.out
3. 结构
xxxx.c---------C 语⾔指令集合(
C 语⾔按照 C 语⾔语法类似⾃然语⾔的规
则写出的执⾏的功能)
---------C 语⾔源⽂件, C 语⾔源程序
gcc------------- 翻译⼯具,把 C 程序翻译为机器语⾔
a.out----------- ⽬标程序,可执⾏程序
----------- ⼆进制程序
C语言基础语法
C 语⾔是类似⾃然语⾔,要满⾜⼀定的语⾔规则 要实现C 语⾔程序(C语⾔的指令集合),要满⾜ C 语⾔的指令规则(语⾔规则)
基础语法:
1. 语句
C 语⾔的代码就是由⼀⾏⾏的语句构成。语句就是程序执⾏的⼀条操作命
令。 C 语⾔规定 语句(⼀条操作命令)必须以分号作为结束,除⾮ C 语⾔
明确规定可以不写分号
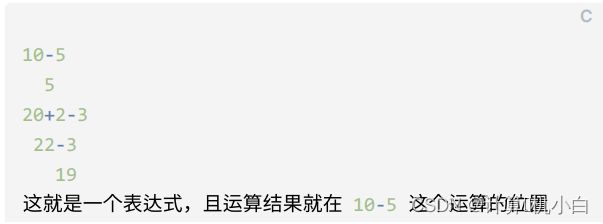
2. 表达式
C 语⾔中各种运算就是使⽤的表达式。表达式就是⼀个计算式(进⾏运算
的式⼦就是表达式),⽤来获取值(运算式的结果)。只要是表达式就
有⼀个运算结果,运算结果出现在运算的位置
C 语⾔基础语法

4. 空格
C 语⾔中空格没有任何的语法含义,只是为了区别各个不同的单位,增强 可读性。
5. 注释
注释就是对代码(C程序指令)的说明,只起到提⽰作⽤,编译器不会对 注释内容进⾏
编译,对代码⽆任何实质影响
单⾏注释
//--- 表⽰单⾏注释,从双斜线开始到这⼀⾏结束都是注释
```
多⾏注释
/* 注释内容 */
从 /* 开始进⾏注释,⼀直到 */ 为⽌
数据类型
C 语⾔的语法中,每⼀种数据都有类型, C 语⾔编译器只有知道数据的类型才
有办法操作数据。
说明在 C 语⾔中只能认识对应的类型, C 语⾔代码只能包含对应的类型数据,
C 语⾔语法只能使⽤这些数据类型
C 语⾔中⽀持的基本数据类型:
整型、浮点型、字符
复杂的类型也是基于基本数据类型构成
计算机数据单位

整形
在 C 语⾔中⽀持整数表⽰,且每个整数类型都是⼀个固定的⼤⼩空间来存储
但是有些数据⽐较⼤,有些数据⼜⽐较⼩,固定⼤⼩空间,存⽐较⼤的数据
时有可能存不下,⼩的数据空间⼜浪费 在整型中设计了多个整型,表⽰不同的固定⼤⼩
整数类型 ⼤⼩
short (int) 2B
整型 int 4B
long (int) 4B(32位计算机 ) 8B (64位计算机)
long long (int)8B(32位计算机 ) 8B (64位计算机)
浮点型
在 C 语⾔中⽀持⼩数表⽰,且每个⼩数类型也是使⽤⼀个固定⼤⼩的空间来存
储。数据也会存在⼤⼩区别,固定空间⼤⼩多少合适?
fl oat 4B
double 8B
浮点型的数据存储:
整数部分和⼩数部分分别⽤⼆进制表⽰
1. 整数部分表⽰
除以⼆取余数
2. ⼩数部分表⽰
乘以⼆取整数部分

由于还是存在⼩数点关系,所以把⼆进制⼩数,采⽤指数的⽅式来表⽰:
即浮点数的表⽰ 分为数据部分与指数部分共同表⽰
数据部分表⽰⼩数数据是多少
指数部分表⽰⼩数点在哪⾥
由于浮点数⽤⼆进制表⽰出来只能⽤固定的位数表⽰,所以在设计浮点型时
fl oat精度只有7位
浮点型表⽰⼩数只能表⽰⼀个近似值(由于⼩数的⼆进制部分的表⽰可能表
⽰不全)

字符型
在计算机中可以表⽰字符,但是字符不能直接存储在计算机中,因为计算机
只认识 0 和 1 不认识字符。
设计⼀种对应关系,⽤⼀个特殊的数字对应⼀个字符,在计算机中只需要存
储这个数字就相当于存储了字符,在使⽤时只需要取出这个数字然后找到对
应关系就是那个字符 -------- 编码
C 语⾔ --------ASCII 码(默认)
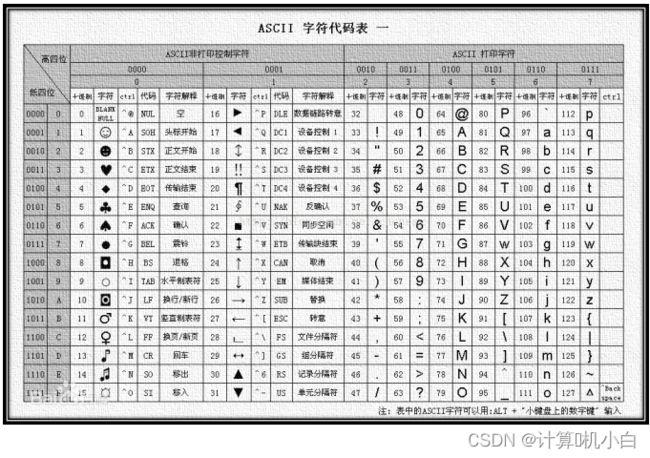
存储字符就是按照整数存储,这个整数就是字符的编码
char表⽰的是字符,但是在计算机中存储形式为字符的编码
数据类型符号
对于数据⽽⾔既有正数⼜有负数,在存储数据时要存储符号
把数据空间的最⾼位作为符号为: 0 表⽰正数、 1 表⽰负数
如: 10、 -10

但是,在计算机中为了计算⽅便,不采⽤数据的实际表⽰⽅式来存储
原码:
数据数值使⽤⼆进制⽅式表⽰,然后最⾼位符号位为 0 或 1 表⽰符号
正数,符号位 0, 后⾯数值为⼆进制值
负数,符号位为 1, 后⾯的数值为对应正数的⼆进制值
原码如图:

反码
正数,反码 == 原码
负数,除了符号位不变(符号位还是为 1 ),其他数据位每⼀位都按位取反(0变为 1,1 变为 0 )
补码
正数,补码 == 原码
负数,反码的基础上 + 1

在计算机中所有数据都是已补码形式存储
表⽰数据类型是有符号(可能是正数也可能是负数)的数据类型,需要在数
据类型前加上 关键字 signed :
有符号的整型数据:
signed int
有符号的浮点型数据 :
signed fl oat
通常不写 signed 时,编译器也会认为是有符号的数据类型
⽆符号数据类型(没有符号,数据类型都是正数), 没有符号位 ,类型⼤⼩
为多少,表⽰数据位数有多少。
表⽰⽆符号的数据类型前加上 关键字 unsigned :
⽆符号的整型数据:
unsigned int

总结:
1. 数据基本类型:整型、浮点型、字符型
整型: short 、 int 、 long 、 long long 浮点型: fl oat 、 double
字符型: char--- 编码形式表⽰(⼀个编码对应⼀个字符)
2. 整型
整数,以⼆进制⽅式存储,使⽤除以⼆ 取余数得到⼆进制形式(⾼位补 0)
3. 浮点型
⼩数,整数部分以除以⼆取余数表⽰,⼩数部分以乘以⼆取整数表⽰, 得到数据部分
⼩数点的位置,⽤指数表⽰ 由数值部分,和指数部分
4. 字符型
把所有的字符对应⼀个编码,把编码(整数)进⾏存储 字符就是以整数形式存储
5. 数据有符号(区分正负数)
⽤数据的最⾼位表⽰符号位: 0 表⽰正数、 1 表⽰负数
计算机存储是以补码形式存储(正数不变、负数取反 +1 )
负数想得到具体的值:把补码进⾏取反 +1
6. 表⽰数据是有符号还是⽆符号
在数据类型前加上 signed--- 表⽰有符号类型
在数据类型前加上 unsigend--- 表⽰⽆符号类型(最⾼位还是数据位, 不是符号位)
变量定义
数据:静态数据、动态数据
静态数据是指⼀些永久性的数据,不会改变
动态数据是指程序在运⾏的过程中,可以进⾏动态的变化(改变)
常量:表⽰⼀些固定的数值,也就是不能改变的数值
整型: 10 、 20 ;浮点型: 1.1 、 5.2 ;字符型:'a'、 'b'
变量:表⽰⼀些不固定的数值,数据可以改变,需要⽤⼀个符号来表⽰数
据,数据不管怎么进⾏变化,符号都表⽰这个数据
变量可以理解为⼀段空间的名字,通过变量名,就可以得到空间的数据值 ,
就是由于值可能随时发⽣变化,所以称为变量
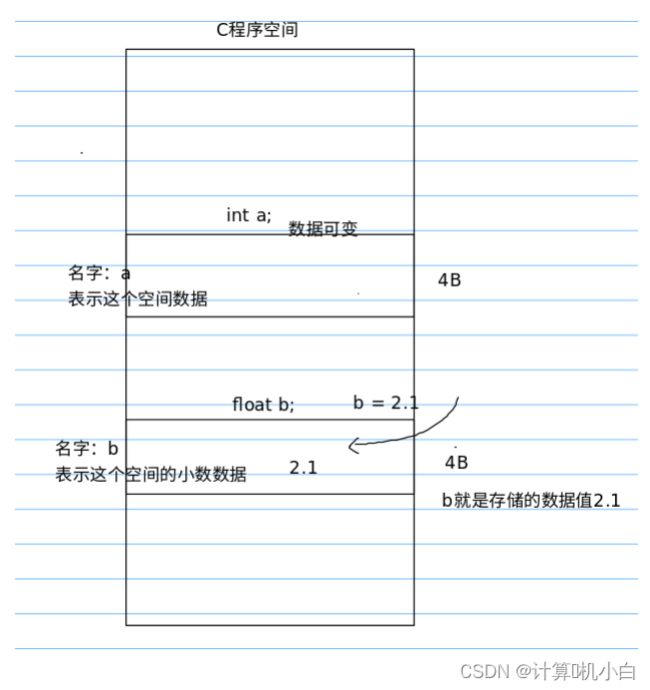
定义变量
在程序的空间中,申请⼀个数据类型的空间作为存储对应类型的数据,由于
数据的值随时可能产⽣变化,⽤⼀个特殊的符号来表⽰这个空间(存储数据
的空间),⽤来表⽰存储的数据值
定义变量:
1. 形式 1 :
数据类型 变量名字 ;
如: int a;
数据类型:⽤来存储什么类型的数据
变量名字:⽤什么符号来表⽰这个数据(这个存储空间叫什么名字)
变量名字:不能随便乱取,要满⾜⼀定的规则
只能以字⺟或下划线开始
整个名字中,只能出现 字⺟ 、 数字 和 下划线
下划线:_
不能与 C 语⾔中规定的关键字⼀样(如: int )
每个变量必须有⾃⼰的类型,才能知道存储空间的⼤⼩,变量名表⽰存储空
间数据的名字

2. 形式 2 :
数据类型 变量名 1, 变量名 2 ,变量名 3,....... ;
连续定义多个同种类型变量 如:int a;
变量使用
变量进⾏了定义,就会有⼀个对应⼤⼩的空间⽤来存储数据
变量名就代表存储的数据,使⽤变量名就是使⽤存储的数据
1. 变量存储数据
可以利⽤运算符 ( = 赋值运算符 ) 往变量中存储数据
= (赋值运算符),把赋值运算符右边的内容赋值给左边
变量名 = 值;
b = 2.1;
注意:变量的要存储的值,应该与变量的类型⼀致
2. 变量数据传递
怎么把⼀个变量数据,存储到另⼀个变量中
直接把变量的值,赋值给另⼀个变量
变量名 2 = 变量名 1 ;
把变量名 1 的值赋值给变量名 2, 让变量名 2 的值也是变量名 1 的值
3. 定义变量时进⾏赋值 ------- 初始化

查看输入输出
使⽤ printf 输出⼀个或多个变量值
要使⽤ printf 功能,在⽂件开始位置: #include < stdio.h >
printf ( " 要输出的内容 ( 原样输出 , 写的是什么就输出什么 ) ,
要输出其他内容需要使⽤格式化字符来进⾏表⽰代替 " ,数据 1 , 数据 2 , 数 据 3 ,..... 数据 n);
回⻋字符: \n
\ ----- 转义字符,把普通字符变为特殊字符,把特殊字符变为
普通字符

输入变量值
给程序的变量输⼊⼀个值
使⽤ scanf 输⼊⼀个或个多值给程序的变量

运算符
只要是使⽤运算符进⾏了运算,就会有⼀个运算的结果出现,不会改变运算
的操作数的值
按照功能:
算术运算符、赋值运算符、关系运算符、逻辑运算符、逗号运算符、位运算
符
算术运算符
数字类型数据的运算,专门⽤于算术运算
+( 加法 ) 、 - (减法)、 * (乘法) 、 / (除法) 、 % (取余)
/ : 除法,如果两个是整数相除,得到的结果还是整数
% :取余,在进⾏除法时,不是得到的商,⽽是得到整除之后的余数
练习:
输⼊两个数,⽤变量存储,交换两个变量值,把交换后的结果打印出来

注意事项 :
如果参与运算的两个数皆为整数,运算结果也是整数
如果参与运算的两个数中有浮点数,那么结果就⼀定是浮点数
在求余数(% ),本质上就是除法求商的余数
在取余运算中,进⾏运算的两个数只能是整数,不能有浮点数
比较运算符
⽐较运算符也叫关系运算符
求左右两边表达式的关系,通过关系运算符来进⾏⽐较判断关系是否成⽴
有以下运算符:
| > | ⼤于运算符,判断⽐较前⼀个数是否⼤于后⼀个数 |
| < | ⼩于运算符,判断⽐较前⼀个数是否⼩于后⼀个数 |
| == | 等于运算符,判断⽐较前⼀个数是否等于后⼀个数 |
| >= | ⼤于等于运算符(不⼩于),判断⽐较前⼀个数是否⼤于或等于后⼀个 数|
| <= | ⼩于等于运算符(不⼤于),判断⽐较前⼀个数是否⼩于或等于后⼀个 ⽐较运算符 数 |
| != | 不等于运算符,判断⽐较前⼀个数是否不等于后⼀个数 |
在 C 语⾔中⽤于⽐较运算,⽐较两个数(经过各种运算)是否满⾜关系,⽐较
判断是否成⽴。⽐较运算 ---- 表达式。
关系运算符,只有两种结果,如果关系成⽴,结果为1,也就是“真”;如果关
系不成⽴,结果为0,也就是“假”

逻辑运算符
逻辑运算符,提供逻辑判断功能,⽤于构造更加复杂的表达式
&& 逻辑与 运算符,当两侧的表达式都为真时,整个逻辑判断表达式为真
( 即左边表达式成⽴,⽽且右边表达式成⽴,整个逻辑表达式才成⽴)
|| 逻辑或 运算符,当两侧的表达式⾄少有⼀个表达式为真时,整个逻辑判断
表达式为真
! 逻辑⾮ 运算符,改变单个表达式的真假,如果表达式为真,则改为假,如
果表达式为假则改为真
逻辑运算符运算结果: 1 或 0,1 表⽰真, 0 表⽰假
逻辑运算符主要作⽤就是连接多个表达式,进⾏确定是否成⽴
在C语⾔规定,任何数值都有真假,
真:只要 ⾮0数值,就表⽰真(成⽴)(1、-1、2、.....、1.2、-5.1、‘a’)
假:只要数值为0,就表⽰假(不成⽴)
浮点数判断相等: a >= b && a<= b
位运算符
C 语⾔提供位运算符,可以把数据按照⼆进制位 bit 的⽅式进⾏运算,⽤来操
作⼆进制位 bit , 包括符号位
~ 把⼀个数据的⼆进制按位取反
& 位与运算符,把两个数值中的每⼀位⼆进制进⾏⽐较,当两个数值⼆进制
位都为1时,这⼀位结果就为 1, 否则为 0
| 位或运算符,把两个数值中的每⼀位⼆进制进⾏⽐较,当两个数值⼆进制位
只要有⼀个为1 (包括两个都为 1 ),这⼀位的结果就为 1, 否则为 0 (两个都位
都为0 )
^ 异或运算符,把两个数值中的每⼀位⼆进制进⾏⽐较,当两个数值⼆进制
位不同时(其中⼀个为1, 另⼀个为 0 )这⼀位的结果就为 1, 否则为 0
<< 左移运算符,把⼀个数值中每⼀位都左移指定的⼤⼩,低位补 0
>> 右移运算符,把⼀个数值中每⼀位都右移指定的⼤⼩,⾼位补之前的最⾼
位值(符号位)
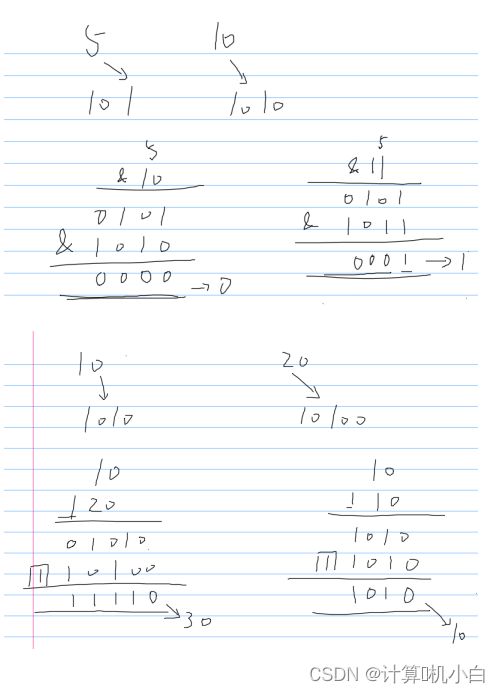

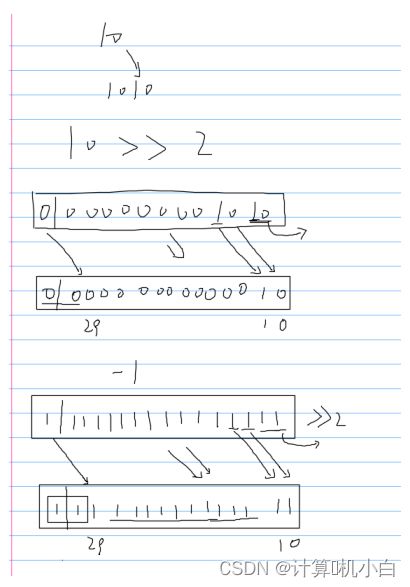
逗号运算符
将多个表达式写在⼀起,从左⾄右依次运算每个表达式,同时把最后⼀个表
达式的运算结果作为整个逗号运算符运算的结果

运算符的优先级
如果在表达式中出现多个运算符,则按照优先级进⾏运算

复合运算符
在运算符中,可以把运算符结合起来⼀起使⽤: 1. 复合 赋值运算符
把 = 运算符和其他运算符结合起来⼀起使⽤
结合算术运算符
+= 、
-= 、
*= 、
/= 、
%= 、
结合位运算符
<<= 、
>>= 、
|= 、
&= 、
^=
将左边变量的值取出进⾏对应的操作,操作完毕后再重新赋值给左边变
量,如:
a += 2 => a = a+2
表⽰把右边表达式进⾏运算得到结果再与左边的变量进⾏指定的运算,
然后把结果赋值给左边 变量
例如:
变量 += 表达式;变量 |= 表达式
= > 变量 = 变量 + ( 表达式 )
2. ⾃增、⾃减运算符
在程序的设计过程中,经常遇到 a = a + 1 和 a = a -1
===>a +=1 和 a -= 1
把 a 变量的值 +1, 把 a 变量的值 -1
在 C 语⾔中提供了两个更为简洁的运算符,即 ++ 和 --

流程控制
C 语⾔的程序是顺序执⾏,即先执⾏前⾯的语句,再执⾏后⾯的语句。会按照
书写的顺序从上往下依次执⾏程序中的每⼀⾏代码。但是这种情况不能满⾜
我们所有的指令(程序)执⾏要求
C 语⾔提供了三种控制程序运⾏的流程。
三种流程控制结构:
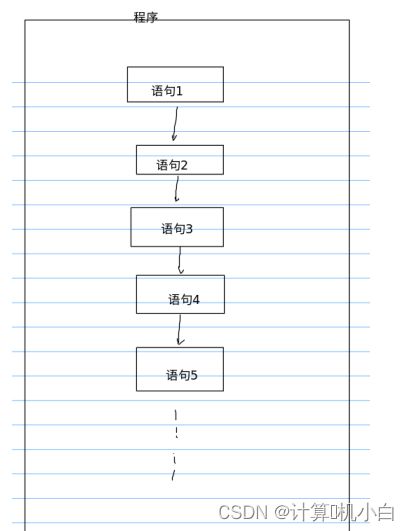
1. 顺序结构
2. 选择结构:根据条件选择执⾏语句
根据对应的条件是否成⽴,进⾏判断来决定是否要执⾏,不执⾏就跳过
部分语句
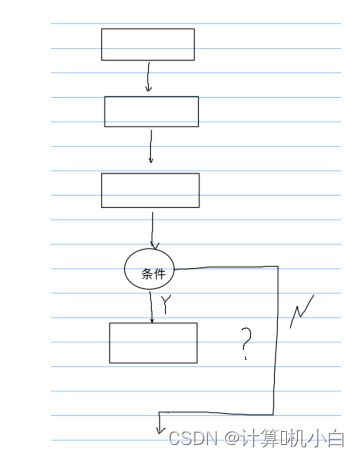
C语⾔中提供了两种选择结构的实现⽅式:if 和switch
if选择结构
if单分⽀选择
进⾏条件判断,满⾜条件时,就执⾏对应语句,不满⾜时就跳
过这段语句继续往下执⾏
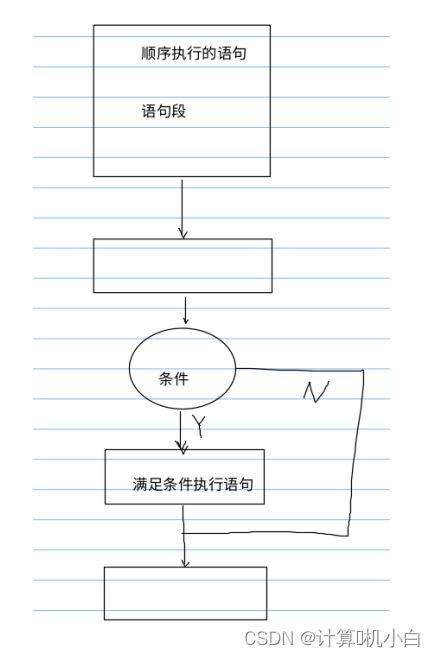
语法形式:
if( 真 / 假判断的条件表达式 )
{
满⾜条件执⾏的语句块
( 如果满⾜条件只执⾏⼀条语句,可以不写 {})
}
条件表达式为真(⾮ 0 ),则执⾏满⾜条件的语句
----- 括号中就是条件,判断真(⾮ 0 )假(0)⾜,假就是不满 ⾜
只要条件表达式成⽴(表达式运算结果为⾮ 0 ):就执⾏
所以在条件表达式中,写出满⾜要执⾏关系的表达式,只要为
真就满⾜关系
if双分⽀选择
进⾏条件判断,如果满⾜条件就执⾏满⾜条件的语句,如果不
满⾜则跳过满⾜条件的语句,去执⾏另⼀段不满⾜条件的语句
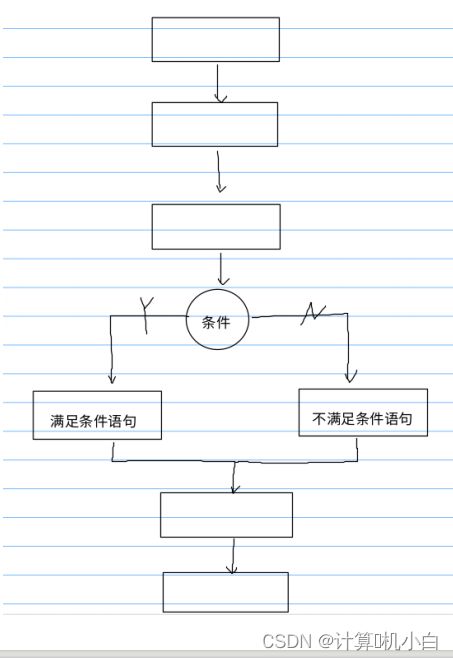
if( 条件表达式 )
{
满⾜条件的语句
}
else
{
不满⾜条件的语句
}
条件表达式为真(⾮ 0 ),则执⾏满⾜条件的语句
if多分⽀选择
进⾏条件判断,如果满⾜条件1, 则执⾏满⾜条件 1 的语句然后结
束整个if ;不满⾜条件 1, 则判断条件 2, 如果满⾜条件 2, 则执⾏满
⾜条件2 的语句然后结束整个 if; 不满⾜条件 2, 则判断条件 3, 如果
满⾜条件3, 则执⾏满⾜条件 3 的语句然后结束 if; 不满⾜条件
3,.......,⼀直到最后⼀个条件判断
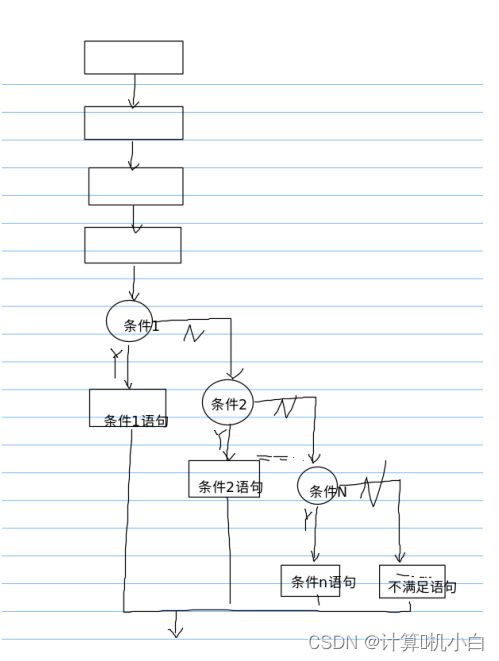
语法:
if( 条件 1)
{
条件 1 语句
}
else if( 条件 2)
{
条件 2 语句 }
else if( 条件 3)
{
条件 3 语句
}
else if( 条件 4)
{
条件 4 语句
}
......
else if( 条件 n)
{
条件 n 语句
}
else
{
不满⾜语句
}
if 选择结构:条件表达式,只有真假,真就执⾏、假就不执⾏
switch选择结构
是⼀种特殊的if...else 结构,对 if...else 进⾏了补充,提供了多路选
择,把if...else 的多路分⽀改成更加易⽤,可读性更好
语法格式:

switch case 语句 表达式和常量表达式结果必须是整数,当相等后,从case
后执⾏直到遇到break或整个switch结束
3. 循环结构
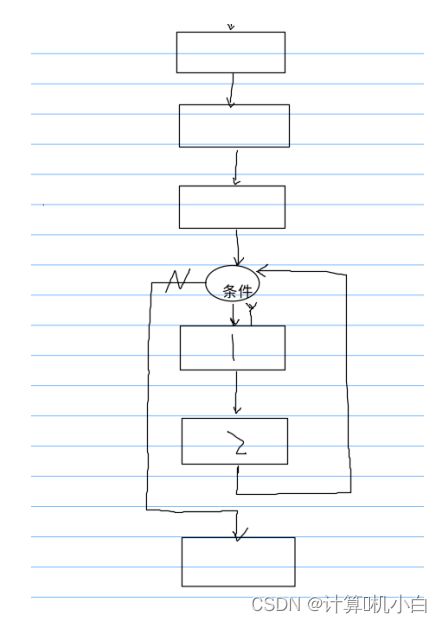
当给定的条件满⾜时,重复执⾏对应的语句块,直到条件不满⾜为⽌,
就跳过这个语句快,继续往下执⾏
给定的条件,叫做 “ 循环条件 ” ,重复执⾏的这段代码称为 “ 循环体 ”
语法格式:
while 循环
while ( 循环控制条件 )
{
循环体 ;
能够让循环结束的语句
}
while 循环执⾏流程:
先判断循环控制条件为⾮ 0 (真),就会执⾏循环体语句,循环体执⾏完,然
后再次判断循环控制条件是否为真,为真就再次执⾏循环体 ; 继续判断循环条
件是否为真,如果为真,就继续执⾏,直到某⼀次判断条件为假就跳出循环
循环控制条件:
满⾜条件就会执⾏,循环退出的主要依据,来控制循环执⾏的次数,循环什
么时候退出
循环体:
循环过程中需要重复执⾏的代码
练习:
先打印五个空格,然后打印五个星号
计算 1+2+3+4+....+100 的和
2. for 循环
判断条件是否成⽴,成⽴就循环体,再次判断条件,如果成⽴继续执⾏循环
体,直到条件不满⾜,就跳出循环
循环体 ;
能够让循环结束的语句
}

当要执⾏循环, 先执⾏⼀次初始化表达式(只执⾏⼀次),先判断循环条件
表达式是否成⽴ ,如果成⽴,则执⾏循环体,循环体执⾏完会执⾏⼀次循环
后的操作表达式;再次判断循环条件表达式是否成⽴,如果成⽴,则再次执
⾏循环体,循环体执⾏完会执⾏⼀次循环后的操作表达式;继续判断循环条
件,当不成⽴则退出循环
与 while 循环⼀致,只是在 for 中,把初始值设置和条件变化改变,提供了⼀
个位置让你去添加,在执⾏时会⾃动去 for 循环的位置进⾏执⾏

for循环的注意事项:
for循环括号内的三个表达式可以不写,但是 ;; 必须添加
如果是初始化表达式没有添加,说明for 循环直接进⾏条件判断,不需要
进⾏初始化表达式执⾏
如果是循环条件表达式没有添加,默认条件永远为真
如果是循环操作表达式没有添加,每轮循环体结束不需要额外执⾏操作表达式
3. 循环的嵌套
在⼀个循环的循环体中,如果再包含了循环就叫做循环的嵌套

四大跳转语句
1. break
⽴即 跳出当前的 switch 语句或 ⽴即 跳出当前的循环


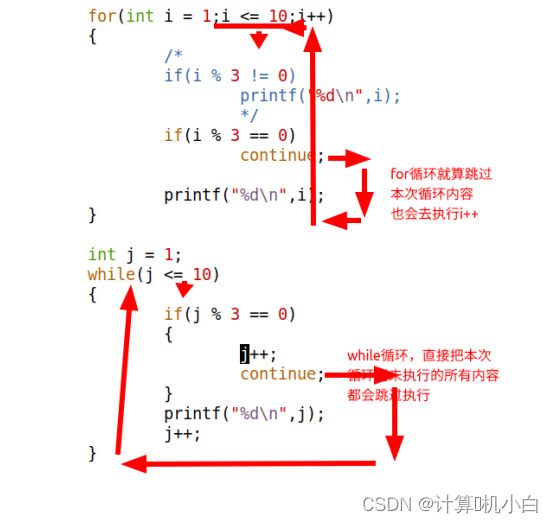
2. continue;
⽤于再循环中,跳过本次循环尚未执⾏的语句,直接进⾏下⼀次循环条
件判断
3. goto;
4. return
结束当前函数,将结果返回给调⽤者
在函数定义中进⾏使⽤return,⽤来表达返回值,同时也表⽰函数功能
语句执⾏结束(函数执⾏到此结束)
return + 值;
注意点:
函数可以包含多个return ,只要执⾏到第⼀个 return 就结束函数
如果没有返回值(返回类型为void ),也可以使⽤ return ,表⽰结束,
但是没有值会返回
函数
需要重复执⾏的功能代码,把这个功能单独的写出来,然后只需要在需要使
⽤的位置直接指明需要使⽤这个功能 ----- 函数
函数:就是⼀段可以重复执⾏的代码功能 ; 将⼀个常⽤的功能封装起来(单独
书写变成⼀个整体),⽅便以后调⽤
就是⼀个功能模块,通过函数来表⽰⼀个功能,要使⽤功能时,只需要把函
数进⾏调⽤
C 语⾔提供了库函数
也允许我们⾃⼰建⽴函数
函数定义:

函数定义步骤:
函数名:函数叫什么名字,标识⼀个功能(函数)
函数体:这个函数功能到底是⼲什么的(具体功能语句),包含了什么代码
返回值类型:就表⽰函数的功能执⾏的结果(返回值)的数据类型
返回值:就表⽰在函数调⽤完成后,会存在⼀个执⾏结果,这个值会返回到调⽤位置
函数名:只能有数字、字⺟和下划线构成,且第⼀个字符只是是能是字⺟或
下划线
1. ⽆返回值,⽆参数列表的函数定义:
函数执⾏之后没有结果(不需要结果),⽆返回值
没有返回值类型,C 语⾔定义了 void ,表⽰空类型,没有数据类型

函数调⽤:
函数名 ();
2. 有返回值,⽆参数列表的函数定义:
函数执⾏后需要有⼀个结果,有返回值
函数定义:

函数调⽤:
函数名 ();
但是有返回值的函数,在函数调⽤完成(函数结束)后,在函数的调⽤
位置就是函数的结果值-----所以叫做返回值,返回值是什么类型根据 函
数名前⾯所定义的返回值类型决定
3. ⽆返回值,有参数列表的函数定义:
没有参数列表的函数,只能⽤于⼀些固定的功能操作
如果函数功能中需要⽤到⼀些值,但是这些值需要是不确定的值,把这
些值设计为变量,作为函数的使⽤; 在调⽤的时候把实际的具体值,传⼊
给调⽤函数中的参数变量,就可以完成具体的操作
如果函数中的变量是⽤于接收在调⽤时传⼊的值,叫做参数变量
参数列表:就是描述有哪些变量⽤于接收调⽤时传⼊的值
参数列表格式:类型 1 变量 1 ,类型 2 变量 2, 类型 3 变量 3...
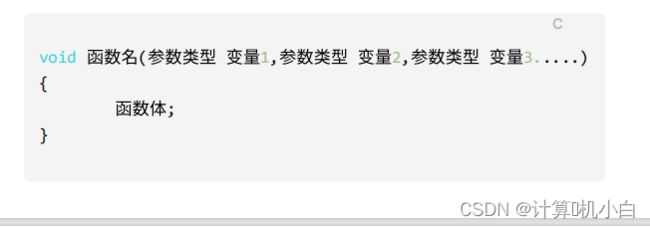
函数调⽤:
函数名 ( 实际值 1, 实际值 2, 实际值 3);
实际值会依次传给参数变量
4. 有返回值,有参数列表的函数定义:

函数使⽤注意事项:
1. 函数定义注意
1. 函数名不能相同
2. 函数的参数和返回值
1. 形式参数:在定义函数时 ,() ⾥⾯定义的参数变量,简称形參
形參变量,属于定义的函数,在实参传递时只能接收值不能接 收变量
2. 实际参数:在函数调⽤时,传⼊的值,简称实参
实参可以时变量、常量、表达式、甚⾄可以是函数调⽤(使⽤ 函数调⽤的结果)
3. 参数个数
实参和形參个数要匹配
4. 参数类型
当实参和形參类型不匹配时,会⾃动把实参变为形參的类型
5. 实参和形參只是值传递,即把实参的值传递给形參,⽽不是把
实参整个变量传给形參
返回值类型 函数名(参数类型 变量 1 , 参数类型 变量 2 , 参数类型 变量
6. 返回值
如果定义函数没有写返回值类型,默认为int
如果返回值(return 值),和返回值类型不匹配,则以返回值 类型为准
3. 函数声明
在C语⾔中,函数的定义是有讲究的
只有在后⾯定义的函数才能调⽤在前⾯定义的函数
因为系统搞不清楚有没有这个函数
也搞不清楚有没有形式参数,没有返回值类型
所以,就存在函数声明,在函数调⽤之前,告诉系统,该函数是什
么样⼦
如果函数的定义是在函数的调⽤之后,就需要声明
函数声明格式:
返回值类型 函数名 ( 参数类型,参数类型,参数类型 ,...);
返回值类型 函数名 ( 参数类型 变量名,参数类型 变量名 ,.....);
数组
数组的基本概念
数组:就是⼀组数据,存储多个数据;数组就是⽤来存储⼀组数据 ; 就是具有
⼀定关系的若⼲个变量的集合,⽤来存储多个数据值
数组的⼏个名词:
1.数组:⼀组" 相同数据类型 " 数据的有序集合
2.数组元素:在数组这个集合的每⼀个数据(构成数组的每⼀个数据)
3.数组下标:数据元素位置的索引(从0 开始)
在之前使⽤,每⼀个数据都需要定义⼀个变量来存储,如果需要存储多个数
据,则需要定义多个变量。
数组:
可以⼀次定义多个变量进⾏使⽤:申请⼀段连续的空间(定义的变量的类型
乘以 变量的个数)来表⽰多个变量存储数据,这就叫做数组
有序的⼀组相同数据类型数据变量集合
数组中的元素的数据类型⼀致
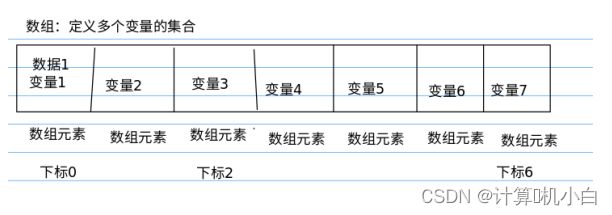
数组的使用
1. 数组的定义: 元素类型 数组名 [ 元素个数 ];
元素类型:数组中每个成员(每个数组元素)是什么类型
数组名:整个数据(变量)集合的名字, 这个名字表⽰整个数组
元素个数:有多少个数据元素(变量)
2. 数组的使⽤:
要使⽤数组,就是使⽤数组的元素,进⾏操作(数组表⽰⼀次定义多个
变量,当然使⽤的是定义的变量)
由于数组在定义时有序,谁是第⼀个数组元素,谁是第⼆个已经定义好 了
数组元素访问:通过索引(下标)进⾏访问
3. 数组的初始化
在进⾏定义时赋值叫做初始化
在定义数组时对数组的元素进⾏赋值叫做数组初始化
元素类型 数组名 [ 元素个数 ] = { 元素值 1, 元素值 2,.......}
完全初始化:对数组的每⼀个元素都进⾏初始化
有元素个数
元素类型 数组名[ 元素个数 ] = { 元素值 1, 元素值 2,.......};
没有元素个数:在定义数组时,不写元素个数; 根据 {} 的元素值个数来确定数组中的元素个数
元素类型 数组名[] = { 元素值 1, 元素值 2,.......};
元素个数根据,元素值个数确定
部分初始化:对数组的部分元素进⾏初始化
+ 有元素个数
+ 按下标顺序,部分初始化
元素类型 数组名 [ 元素个数 ] = { 元素值 1, 元素值 2};
把元素值 1 初始化给下标 0 元素,把元素值 2 初始化给下标 1 元素,其他元
素都赋值为 0
+ 按照指定下标,部分初始化
元素类型 数组名 [ 元素个数 ] = {[ 下标 ] = 元素值 1,[ 下标 ] = 元素值 2};
需要初始化那个元素,就初始化哪个元素,没有顺序,没有进⾏初始化
的元素赋值为 0
+ 没有元素个数
+ 按照指定下标,部分初始化
元素类型 数组名 [] = {[ 下标 ] = 元素值 1,[ 下标 ] = 元素值 2};
按照指定下标的最⼤值,作为数组的元素个数
字符串
字符类型:
字符类型:
是⼀种⽐较灵活的数据类型,字符类型数据占⽤ 1B 存储空间
计算机只认识 0 和 1 ,所以存储 char 字符类型数据时,不是直接存储字符,⽽
是将字符转换为 0 和 1 之后再存储
正是因为存储字符类型数据要转换 0 和 1 , C 语⾔就设计了 ASCII 码,来表⽰ 字
符要转换成什么样的 0 和 1 ,在 ASCII 码中定义了每⼀个字符对应⼀个整数,
只⽤把字符对应的整数转换为 0 和 1 存储,这个整数就表⽰对应的字符。
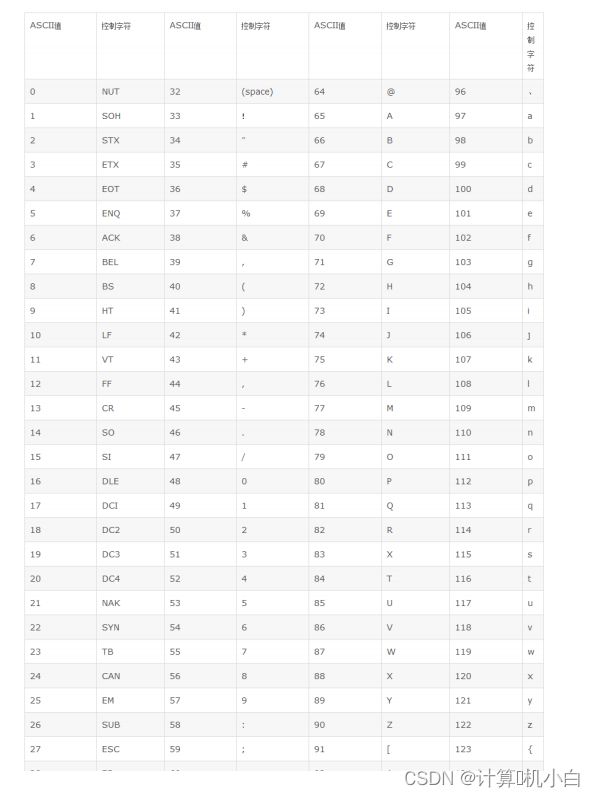
字符的运算都使⽤字符对应的ASCII码整数进⾏运算
字符数组
字符数组:(数组:⼀组相同数据类型的数据集合)
⼀次定义多个字符变量,进⾏存储多个字符(⼀组字符类型的数据集合,有
多个字符数据组成的集合)
定义⼀组字符数据集合来存储多个字符数据 --- 字符数组
如:
char 数组名[ 元素个数 ];
char:数组中每⼀个元素都是字符类型
元素个数:数组中可以存储多少个字符
char buf[10] = {[4] = 'b'};
buf[0] = 'a';

字符数组的使⽤,按照数组的⽅式进⾏,每个元素单独赋值使⽤,每个元素
存储⼀个字符