MySQL索引理解
目录
什么是索引?
索引的好处
思考一个小问题, 索引这么好, 那是不是越多越好?
索引分类
索引的创建和删除
explain字段解释
索引底层数据结构
区分MyISAM和InnoDB存储引擎来再认知聚簇非聚簇索引
什么是索引?

- 索引: 类似于目录的帮助快速检索数据的一种数据结构. 辅助结构. 从小最早接触到索引在哪里? 门牌号, 新华字典的目录。。。根据目录(索引) 快速检索data.
- 在MySQL的存储引擎中, 索引大多采取的是索引B+树作为底层数据结构来实现的.
- 当然也存在hash索引. 自适应hash. 根据实际情况而定.
- 索引要起到快速检索的效果,必然存在数据组织结构特性. 字典都是按照一定的结构所组织数据的. 所以具体怎么检索,我们需要对底层数据结构具备相当的理解
索引的好处
- 索引的核心好处就是加速查找速率, 达到快速检索数据的功能.
-
思考一个小问题, 索引这么好, 那是不是越多越好?
首先,不是所有的场景都适合加索引, 索引主要在于他快速查找的优势.
其次,我们维护索引肯定是需要花费空间+时间上的代价的.
- 空间上: 存在单独的索引文件+数据文件 (MyISAM存储引擎) || 索引+数据存储在一起的文件(Innodb存储引擎)
- 时间上:插入数据删除数据对数据进行update的操作都需要额外的维护索引结构(跟新索引文件)索引文件在磁盘上
- 索引文件的改动需要进行磁盘IO操作. 过多的磁盘IO操作会增大CPU的负担
索引分类
- 物理结构层面上:聚集索引(索引+数据聚集在一起)+非聚集索引(索引跟数据不聚集在一起)
- 数量上:单例索引+多列索引 (最左前缀匹配原则, 左边第一列必须先使用, 联合索引才有用)
- 唯一索引: unique index,不可重复,但可为NULL
- 主键索引: 用primary key 修饰, 不为空的唯一索引
- 普通索引: 没有上述限制,可以为空,允许重复.
索引的创建和删除
- create [unique] index 索引名字 on 表(字段名(字段长度))
- drop index 索引名字 on 表名
- explain query sql : explain 关键字, 获取sql命令的执行计划, 分析慢查询sql语句,为其添加索引.
eg: 尝试一个简单的索引使用:

上述是我的一个表结构, 现在我要查询一下王五: 我可以查询id = 3 or 直接查询王五.
1. 查询id = 3
2. 查询name='王五'
对比之下发现猫腻没有: 直接查主键索引id = 3 检索了一行找到结果, 检索没有索引的name=王五. 直接来了个全表查询。 查询了四行记录.

给name字段加上索引再检索查看效果

也变得检索一行了。
explain字段解释
- select_type: 查询语句的类型, simple简单查询语句,不包含嵌套查询. 其他类型都是嵌套查询或者联表查询
- table: 表名
- type: const用于主键或者唯一索引的等值查询。 ref常见于辅助索引的等值查找 ALL全表搜索
- Extra: using index,查询的时候不需要进行回表查询, 直接通过索引可以获得数据
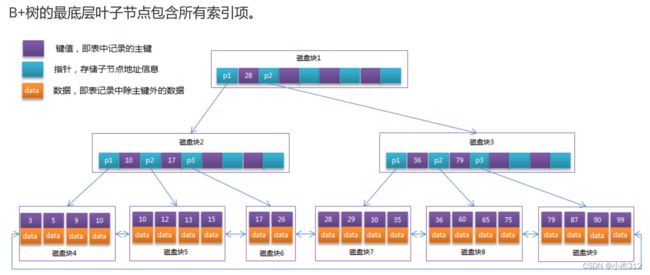
索引底层数据结构

上述这句话是索引底层数据结构选取B+树的关键.
- 第一, 明确一个结点就需要进行一次磁盘IO操作
- 第二,查询到结果的速度主要在于树高,在于路劲上的结点数目.
查询data过程:首先加载根部结点到内存. 建立索引B+树,根据结点信息加载下一个结点所在的磁盘块到内存,不断向下检索。最终到达叶子结点 (分存储引擎,存储的是实际记录信息所在的磁盘地址,或者就是实际的数据记录)
- 磁盘块大小: 16k, 4*pagesize. 也就是4个存储页. (也就是B+树结点设置大小)
- 上述是为了磁盘IO的次数最少. 磁盘IO才是MySQL读写效率的关键.
hash表: 仅仅只能做等值查询, 也就是查询确切的一个值,不能查询一个区间range. 如果需要range查询就会退化为全表扫描的方式.
且数据key值局限性大,不能出现大量的(冲突),如果出现key大量的冲突,还需要resize扩容. 扩容转移数据代价也比较高. (面试考点, 可不可以不转移数据,两个hash表共用? 一致性hash)
key: 存储索引列, Value存储行记录或者行记录所在磁盘地址.
搜索树: AVL树, 红黑树. 二路分叉 树高都不太理想,容易出现廋高现象。磁盘IO次数还是不少.
B树: 多路分叉. 左树 < 结点 < 右树 (多路分叉使得树高进一步降低.)
B+树:B树基础上做出优化, 数据全部都存储在叶子结点上, 且前面的非叶子结点均只存储索引。这样,上面的结点不存储实际的记录,可以存储更多的索引,进一步降低树高. 减少磁盘IO次数,而且叶子结点的数据按照key值有序性用双向链表做串联. 易于快速进行range查询操作。
B树
B+树
区分MyISAM和InnoDB存储引擎来再认知聚簇非聚簇索引
MyISAM引擎使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址

对于MyISAM而言, 主键索引和其他的二次索引结构式一毛一样的。data存储的也是记录的磁盘地址. 唯一一点不一样,就是辅助索引允许key值重复, 但是主键索引唯一.

故而,MyISAM存储引擎。索引+数据分开存储在两个不同的磁盘文件当中.
例如一个user 表,会在磁盘上存储三个文件 user.frm(表结构文件) user.MYD(表的数据文件) user.MYI(表的 索引文件)。 .MYD:data数据文件,.MYI: index索引文件
Innodb存储引擎而言,将索引+数据放入到一个文件中.
![]()
student.ibd: index + data文件, 索引加数据放在一起的文件。 frm表结构的文件.

对于Innodb主键索引:也就是所谓的聚集索引,看吧,为啥叫做聚集,索引和数据聚集在一块的。数据在最下面叶子连在一块,此为之聚集.
Innodb下的非聚集索引: 辅助索引, 二次索引.
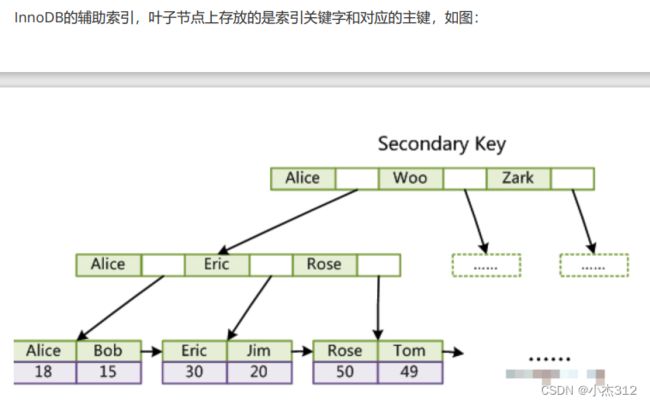
最下面叶子结点记录的是主键值, 也就是聚簇索引B+树的key值。如果需要获取更多的额外的data信息,在辅助索引B+树上找不全,就需要再回表查询,查主键索引B+树,耗费更多的磁盘IO.
看到这里. 小杰想跟兄弟们推荐一篇知乎上火爆的关于索引的文章, 检验一下自己,看看索引过关了不,学无止尽,反复思考,领略概念,企图更加深入。
我以为我对Mysql索引很了解,直到我遇到了阿里的面试官-HollisChuang's Blog
最后小杰浅谈文中几个问题:
如何引入索引? 从慢查询+explain看sql执行计划来分析加索引入手
索引底层数据结构?可能衍生到hash table 与 搜索树 与 B+树的区别和优劣
B+ Tree的叶子节点都可以存哪些东西? data + key
覆盖索引是啥?不要回表查询
联合索引、最左前缀匹配?
我们把识别度最高的字段放到最前面, 最常见的,点击量最高的列放在左边,越左,优先级越高:
如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3)三个索引,这就是最左匹配原则。