JS前端AI应用集合重磅开源,PP-OCRv3 JS版模型速度提升87.5%

在前端应用中,人脸识别、人像分割等AI能力已经广泛分布于各类场景中,其在低延迟、数据隐私保护、服务资源节省等方面都有明显的应用优势。随着人工智能技术的不断发展,越来越多的深度学习模型在保持超轻量的同时也拥有高精度的特点,使得前端可实现的AI应用范围不断扩大。
近期,百度飞桨团队联合飞桨开发者技术专家(PPDE) 陈千鹤,发布了支持一站式AI能力的前端应用集合,大幅提升了AI模型的易用性和可移植性。主要特色包括:
提供视觉模型7种、Web端Demo和小程序端Demo共计6个,覆盖人脸检测、文字识别等经典计算机视觉技术应用方向;
提供开箱即用Demo和NPM包调用两种方式,灵活易用;
支持自定义修改前后处理参数、更换模型等定制化需求。
话不多说,先看Demo!
Web前端应用集合:包括人脸检测、人像分割、手势识别、1000种物品识别。
人脸检测

OCR文字检测与识别动图
小程序应用:
图像识别小游戏
Demo传送门:
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/
详细的使用流程
Demo使用
整体优化后的计算机视觉网页端Demo体验步骤十分简单。
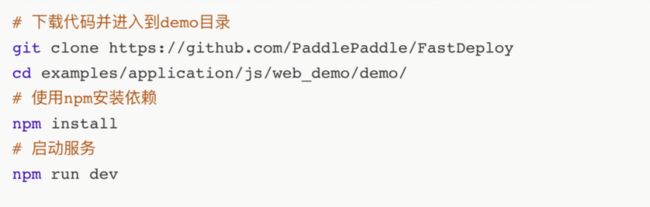
在浏览器中打开网址即可看到如下界面,点击左侧不同的功能即可体验OCR、图像检测、分割功能。网址链接:
http://localhost:5173/main/index.html

进阶使用
以PP-OCR JS模型为例,只需通过指令npm install@paddle-js-models/ocr。
使用方式如下

其中,ocr.recognize ()函数的输入参数img是HTML ImageElement格式的数据。
如果要在前端项目中直接使用其他Demo中的AI能力,只需要在NPM中搜索相应的包,通过指令npm install包名即可完成安装。链接地址:
https://www.npmjs.com/search?q=paddle-js-models
更换模型 自定义前后处理参数
更换模型
步骤1:将模型转成js格式,参考如下命令

步骤2:修改代码替换默认的模型。
以OCR Demo为例

注:
OCR文本识别Demo模型部署的源代码链接
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/demo/src/pages/cv/ocr/TextRecognition/
ocr.init()函数有两个参数,分别为检测模型参数和识别模型参数,源码参考
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/packages/paddlejs-models/ocr/src/index.ts#L52
自定义处理参数
以OCR文本检测Demo为例,期望修改文本检测后处理的参数实现扩大文本检测框的效果。
修改前

参数调整前,文本检测效果如下

通过给detect()函数传入文本检测的后处理参数,修改后代码如下

注:OCR文本检测Demo模型部署的源代码链接:
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/demo/src/pages/cv/ocr/TextDetection/
扩大检测框后,重新运行Demo,文本检测效果如下

有关PP-OCR JS模型预测的细节,参考以下链接
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js/web_demo/packages/paddlejs-models/ocr
更多Demo应用方法可以在FastDeploy中查阅
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/application/js
FastDeploy简介
FastDeploy是一款易用高效的推理部署工具箱。已支持TensorRT、Paddle Inference、OpenVINO、ONNX Runtime、Paddle.js等(Paddle Lite、RKNN等开发中),多硬件统一API部署体验;覆盖业界CV、NLP、Speech等热门AI模型60+,提供开箱即用的部署体验。
深度学习模型
优化经验揭秘
由于前端环境和计算资源限制,在前端部署深度学习模型时,我们对模型的性能有着更严格的要求。简单来说,模型需要足够轻量化。理论上模型的输入shape越小、模型大小越小,则对应的模型的flops越小,在前端运行也能更流畅。经验总结,使用Paddle.js部署的模型存储尽量不超过5M。
本次发布的Demo中的模型性能数据如下表所示。其中,主要针对PP-OCRv3模型进行了优化,因其涉及多个模型的串联(文本检测和文本识别),对单个模型的性能要求更严格。通过通道裁剪、知识蒸馏等技术进一步进行模型轻量化后,整体系统存储从12.3M压缩至4.3M,在Mac M1机器上使用Google Chrome测试推理速度仅需350ms,流畅度显著升级,相比旧版本模型压缩65%,预测速度提升87.5%。
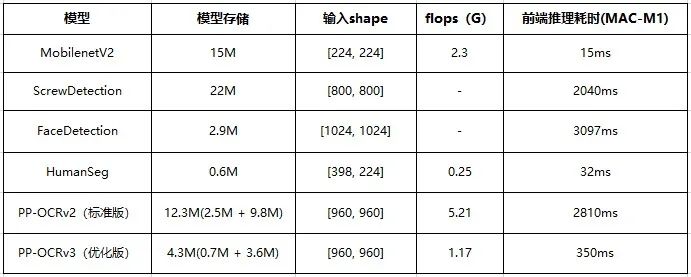 注:flops统计不包含前后处理
注:flops统计不包含前后处理
加入FastDeploy JS
技术交流群
入群福利
第一时间获取FastDeploy产品最新信息及学习资料
近距离与各企业部署大佬互动交流
近距离与FastDeploy研发同学交流讨论
入群方式
微信扫码填写问卷,进入官方社群了解更多产品详情。

相关网址
飞桨官网
https://www.paddlepaddle.org.cn
FastDeploy项目地址
https://github.com/PaddlePaddle/FastDeploy
PaddleOCR项目地址
https://github.com/PaddlePaddle/PaddleOCR
Gitee
https://gitee.com/paddlepaddle/PaddleOCR

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~