【数据结构】伪链表查找节点的两种方法(内容充实)
文章目录
-
- 上节回顾
- 一、通过数据查找节点
- 二、通过下标查找节点
- 三、统计重复数据的数量
- 四、统计重复数据的详细信息
- 五、主函数框架
- 六、重复部分的封装函数
- 总结
-
- 下节预告
上节回顾
在上一篇文章伪链表的链接和链表的遍历中我们在最后通过思路和逻辑整理得到了一个通用的链表遍历函数
preview
void preview(struct Code* phead)
{
while(phead != NULL)
{
phead = phead->pnext;
}
}
在接下来的文章中这个函数将会使用的十分频繁,很大程度上就是因为这个函数在链表遍历时的通用性,这都是大量前辈实践总结出来的,理解它的产生过程后将它记住便可。
一、通过数据查找节点
我们要在链表中查找一个节点,首先要做的就是遍历整个链表,这时就要用到我们上面说的遍历函数了,然后将我们要找的数据与各个节点的数据进行逐一比对,看是否是我们要找的节点。
如果是我们要找的节点就返回该节点的地址,如果遍历完整个链表都未发现我们要找的数据,就在函数末尾返回NULL。
接下来就来实现这一功能
//通过数据查找节点
struct Code* find_data(struct Code* phead,int data_1)
{
//遍历链表
while(phead != NULL)
{
if(data_1 == phead->data)
{
//找到节点返回该节点地址
return phead;
}
phead = phead->pnext;
}
//遍历完整个链表未找到节点返回NULL
return NULL;
}
二、通过下标查找节点
与上一种查找节点方法类似,我们首先要利用链表遍历函数对整个链表进行遍历,然后将我们要找的节点下标与链表各个节点下标进行对比,看是否是我们要找的节点。
如果是我们要找的节点就返回该结点的地址,如果遍历完整个链表都未发现我们要找的数据,就在函数末尾返回NULL。
接下来就来实现这一功能
struct Code* find_index(struct Code* phead,int index)
{
//定义一个计数变量表示链表节点下标
int num = 0;
//遍历链表
while(phead != NULL)
{
if(num == index)
{
//找到节点返回该节点地址
return phead;
}
num++;
phead = phead->pnext;
}
//遍历完整个链表未找到节点返回NULL
return NULL;
}
接下来解释一下关于函数返回值和参数的传递问题
我们观察函数内部的返回值发现一种情况是phead,另一种是NULL,而在上一篇文章中解释过phead是结构体指针类型,所以这里传递进函数内的就是结构体指针类型的phead,而返回值也是结构体指针类型的phead,所以返回值相应的就是结构体指针类型。
但是我们会注意到上面写的两个函数都是针对没有数据重复的链表,如果节点中的数据有重复又该怎么办呢
三、统计重复数据的数量
int data_num(struct Code* phead,int data)
{
//定义一个计数变量
int i = 0;
while(phead != NULL)
{
if(phead->data == data)
{
i++;
}
phead = phead->pnext;
}
return i;
}
通过这个函数我们只能得到有多少个重复的数据,不能得到每个数据的详细信息,那么我们就需要再写一个函数来告诉我们每个重复数据的信息。
四、统计重复数据的详细信息
我们要统计信息,就要考虑经过函数处理得到了每个数据详细信息,那么这些信息怎么反馈给我们呢,也就是说这些信息要存储在哪里呢?毫无疑问,我们要选择数组,将信息存储在数组中,最后通过遍历数组来得到这些数据的信息。
//定义一个元素为结构体指针的数组去装数据信息
struct Code* arr[4] = {NULL};
void data_infor(struct Code* phead,struct Code* arr[4],int data)
{
//定义一个下标索引变量
int index = 0;
while(phead != NULL)
{
if(phead->data == data)
{
//若符合要求就将该节点地址存入数组中
arr[index] = phead;
}
phead = phead->pnext;
}
}
五、主函数框架
我们在上面已经实现了查找节点的功能并且将它们分别封装为函数,接下来我们需要在主函数中进行函数调用。
#include 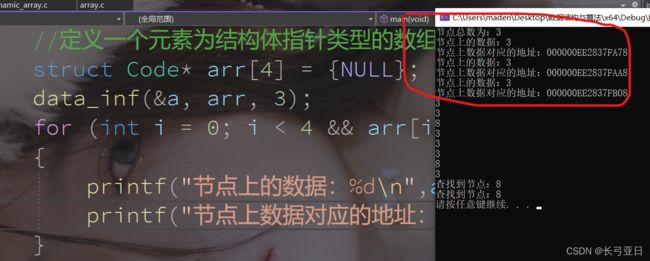
我们在这里再探讨一个细节问题,关于上面代码for循环
i < 4 && arr[i] != NULL中的一个顺序问题,我们为什么不把arr[i] != NULL放在前面而是把i < 4放到了前面?
这里涉及到了一个越界问题,上一次循环结束i为3,进入循环后执行一次i++,此时将i变为了4,此时如果把arr[i]放到了前面,就产生了arr[4]此时数组已经越界了,但是如果把i < 4放在前面,此时i < 4为假,即计算结果为0,则有0&&arr[i] != NULL则0把&&后边的语句短路了,就不再执行&&后边的语句。
六、重复部分的封装函数
在主函数框架中我们发现代码又出现了重复的部分,这样的重复使代码看起来不美观,所以我们可以将重复的部分单独封装成函数后进行调用,这会使代码看起来清晰美观,并且可读性提高。
void show_result(struct Code* pfind)
{
if(NULL == pfind)
{
printf("未查找到此节点\n");
}
else
{
printf("已查找到此节点:%d\n",pfind->data);
}
}
接下来将主函数中重复的部分用这个封装函数替换
#include 我们观察代码的可读性是不是提高了呢
总结
这篇文章详细介绍了链表中查找节点的两种方法,以及节点数据有重复情况的处理方法,以及对代码逻辑上的细节处理,读者一定要认真去理解,注意一些细节的地方,最重要的是要动手,动手,动手!!!
重要的事情说三遍。
下节预告
伪链表的增、删、改