TensorBoard可视化
在复杂的问题中,网络往往都是很复杂的。为了方便调试参数以及调整网络结构,我们需要将计算图可视化出来,以便能够更好的进行下一步的决策。
TensorBoard不会把代码展示出来,他只是一个日志展示系统,需要在session中运算图时,将各种数据类型的数据会中并输出到日志文件中。然后启动TensorBoard服务,TensorBoard读取这些日志文件,并开启6006端口提供服务,让用户可以在浏览器中查看数据
TensorBoard可以记录与展示以下数据形式:
(1)标量Scalars(2)图片Images
(3)音频Audio
(4)计算图Graph
(5)数据分布Distribution
(6)直方图Histograms
(7)嵌入向量Embeddings
相关函数:
tf.summary.scalar() 标量数据汇总,输出protobuftf.summary.histogram() 记录变化的var直方图,输出带有直方图的汇总的protobuf
tf.summary.image() 图像数据汇总 , 输出protobuf
tf.summary.merge() 合并所有的汇总日志
tf.summary.FileWriter 创建一个 FileWriter
Class summaryWriter 将protobuf写入文件的类
add_summary(), add_session_log(), add_event(), add_gragh()
TensorBoard 使用流程
添加记录节点:tf.summary.scalar/image/histogram()等汇总记录节点:merged = tf.summary.merge_all()
运行汇总节点:summary = sess.run(merged),得到汇总结果
日志书写器实例化:summary_writer = tf.summary.FileWriter(log_dir, graph=sess.graph),实例化的同时传入 graph 将当前计算图写入日志
调用日志书写器实例对象summary_writer的add_summary(summary, global_step=i)方法将所有汇总日志写入文件
调用日志书写器实例对象summary_writer的close()方法写入内存,否则它每隔120s写入一次
先看一个简单的例子:
import tensorflow as tf
tensor0 = tf.constant(3, tf.float32)
tensor1 = tf.Variable(tf.random_uniform([1]))
init = tf.global_variables_initializer()
add_tensor = tf.add(tensor0, tensor1)
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('logs/test0', sess.graph)
print(sess.run(add_tensor))
writer.close()
运行完上面的代码之后在项目目录中生成 logs/test0 目录结构,如下图:
在命令行中进入 logs 文件夹 : cd logs
然后键入命令: tensorflow --logdir test0/ # 也可以指定端口 在后面加入 --port=portId
在浏览器中输入:127.0.0.1:6006 就会看到下图:

从上图中可以看到生成了好几个节点,其中有几个跟我们的业务关系不大,却也显示出来了,如果训练的网络足够大,那么多节点都显示出来还不得看的眼花,所以就需要把不重要的或者我们不想看的隐藏起来。这就有了下面的的命名空间。
添加命名空间
使可视化效果图更有层次性,使得神经网络的整体结构不会被过多的细节所淹没,同一个命名空间下的所有节点会被缩略成一个节点,只有顶层命名空间中的节点才会被显示在 TensorBoard 可视化效果图上。
可通过tf.name_scope()(主要)或者tf.variable_scope()来实现
import tensorflow as tf
with tf.name_scope('tensor0'):
tensor0 = tf.constant(3, tf.float32)
with tf.variable_scope('tensor1'):
tensor1 = tf.Variable(tf.random_uniform([1]))
init = tf.global_variables_initializer()
add_tensor = tf.add(tensor0, tensor1)
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('logs/test0', sess.graph)
print(sess.run(add_tensor)) 生成的图如下:

节点是不是少了一个。其中tf.name_scope() 和 tf.variable_scope() 可以参考另一篇文章。
import tensorflow as tf
import numpy as np
# 构建实验数据
train_x = np.linspace(-1, 1, 100)
# y = 2 * x + b
train_y = 2. * train_x + np.random.randn(*train_x.shape) * 0.3
# 创建模型
# 占位符
with tf.name_scope('args'):
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# 模型参数
weights = tf.Variable(tf.random_normal([1]), name='weights')
biases = tf.Variable(tf.zeros([1]), name='biases')
z = tf.multiply(X, weights) + biases
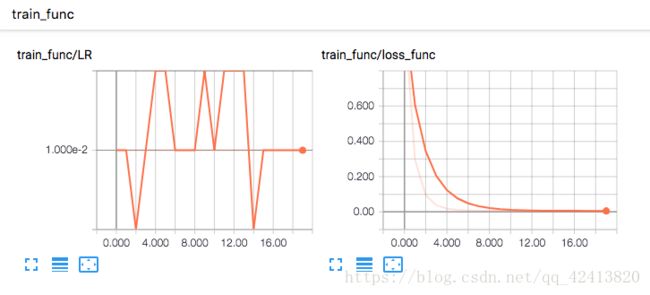
tf.summary.histogram('z', z) # 将预测之以直方图的形式显示 直方图名字是 'z'
# 构建损失函数
with tf.name_scope('train_func'):
loss = tf.reduce_mean(tf.square(Y - z))
tf.summary.scalar('loss_func', loss) # 将损失以标量形式显示 标量名字叫 loss_func
# 定义学习率
learning_rate = 0.01
tf.summary.scalar('LR', learning_rate)
# 构建优化函数
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
# 最小化损失函数
train = optimizer.minimize(loss)
# 初始化所有变量
init = tf.global_variables_initializer()
with tf.name_scope('other_args'):
# 定义 epochs
training_epochs = 20
# 每隔两步显示一次中间值
display_step = 2
# 启动Session
with tf.Session() as sess:
# 初始化全局变量
sess.run(init)
merged_summary_op = tf.summary.merge_all() # 合并所有 summary
# 创建 summary_writer 用于写文件
summary_writer = tf.summary.FileWriter('logs/mnist_summaries', graph=sess.graph)
# 向模型中 feed 数据
for epoch in range(training_epochs):
for (x, y) in zip(train_x, train_y):
feed_dict = {X: x, Y: y}
sess.run(train, feed_dict=feed_dict)
# 生成summary
summary_str = sess.run(merged_summary_op, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, epoch)
# 显示训练中的数据
if epoch % display_step == 0:
loss_ = sess.run(loss, feed_dict={X: train_x, Y: train_y})
print('epoch:', epoch + 1, 'loss = ', loss_, 'weights=',
sess.run(weights), 'biases=', sess.run(biases))
# 保存检查点
print('Finished...')
# 保存模型
print('loss=', sess.run(loss, feed_dict={X: train_x, Y: train_y}), 'weights=',
sess.run(weights), 'biases=', sess.run(biases))

注释掉程序中的 :
with tf.name_scope('args'):
with tf.name_scope('train_func'):
with tf.name_scope('other_args'):
输出结果如下,是不是比上图复杂多了,我只是简单省事的随便添加了命名空间,可能并不合理,但是大致要讲的就是这样。

