ACL2022 | 利用中文语言层级异质图强化预训练语言模型

北京大学数据管理实验室李彦增博士《Enhancing Chinese Pre-trained Language Model via Heterogeneous Linguistics Graph》被ACL 2022收录。
这篇论文提出了一种用于表达中文字-词-句语言学结构关系的异质图(Heterogeneous Linguistics Graph, HLG)。并利用图神经网络建模,在该HLG异质图上实施多步信息传播(Multi-Step Information Propagation, MSIP)以在预训练语言模型的微调阶段训练神经网络的参数。使用这样的HLG建模中文自然语言的结构可以自然而有效地引入分词结构化信息,从而提升原生预训练语言模型在中文上的效果,实验证明该方法在多个基准数据集上得到了稳定的提升。同时,相比起前人发表在ACL 2020年的工作[1](MWA),此论文使用的MSIP和HLG建模在训练、推理速度上有着明显的优势,在不降低性能的情况下提升了约7倍的训练与推理速度。
01
—
问题背景
近年来,以BERT为代表的预训练语言模型方法在各个NLP任务中得到了广泛的应用。典型的预训练语言模型应用方法可以归结为预训练-微调两阶段模式,即先通过在大规模无标注语料库上进行无监督、自监督预训练,然后通过监督训练迁移到具体的下游任务中使用。而针对中文自然语言处理,研究者们提出了各类适配中文语言特性的预训练语言模型,如ERNIE[2]、Glyce[3]等,尽可能利用中文本身的一些性质(例如中文分词、中文字形等)来提升预训练任务的效果。Li等人[1]基于向预训练语言模型融入中文分词的动机提出了MWA模型,试图向原生的预训练语言模型中融入词汇级别特征,与其它专注与预训练的工作不同的是,MWA是在微调的阶段来进行外部信息的融入的,如下图所示:

这样的方式有个好处,可以避免重新预训练所带来的高昂代价,并且实验证明了这样的方法可以在多个中文自然语言处理任务上对原生的BERT等模型带来有效的提升。
MWA是利用一种非标准形式的分段式attention方法,将中文的分词切割信息应用到字符表示产生的attention权重上,对同一个词中的不同字进行mix-pooling聚合,从而让字的attention权重强行在词的级别上进行对齐。这样的设计有效地融入了分词的分段式的结构信息,但也带来了一些新的问题:由于需要逐词、逐样本地计算attention的聚合,会导致attention模型中原本可以向量化、并行化的标准矩阵运算变成需要各自运算、无法并行的高负载运算,并且这样的算子无法利用cudnn原语的加速,也无法享受当今非常重要的深度学习计算加速硬件(如GPU、TPU等)带来的速度提升。
此外,MWA使用了简单的mix-pooling来汇聚字级别的attention权重到词级别,这样简单的pooling方式会导致一部分分词结构上的信息损失,没有很好地反应字到词、字到字的层级化交互形式,而是以平均值的形式将字词进行了统一。
最后,MWA提出可以使用多个分词器,融合多个分词器带来的分词信息,以进一步提升模型的效果,但MWA中使用了非常原始的线性加权的形式,对不同分词器产生的MWA字符表示进行加权求和,这样的形式不仅没有体现出不同分词器所带来的分词纠错的效果,还会产生训练参数的膨胀。因此,作者希望重新思考MWA带来的效果提升与随之产生的副作用,试图以一种更加自然的方式来建模相同的中文语言学结构信息,同时避免上述提到的问题。
02
—
方法原理
受到MWA和多图集成(Multi Graph Ensemble)相关工作的启发,作者以“去噪”这一动机为核心,构建了中文语言学结构异质图(HLG)。在MWA中,作者提出了使用更多的分词器,会得到更好的效果;然而,无上限地加更多的分词信息难道能持续地带来性能提升吗?未必。当引入更多分词器的同时,也会引入更多的分词错误信息,即噪音。这些噪音信息会影响模型的训练效果,带来一定的副作用;如何让正确的分词结构在模型中起到更大的影响力,让错误的分词信息在模型中产生的影响被尽可能忽略,是构建HLG时所考虑的重点。
从模型集成(Model Ensemble)考虑,各个已经训练好的分词器是良好的学习者(well-learner),它们各自产生的结果可以假设为大部分正确而小部分错误。因此,可以以模型集成的观点将它们产生的结果合在一起,体现出“少数服从多数”的投票效果,即如果有更多的分词器认为某个词A应当分出来,那么就应当认为这是更加可信的结论,而少数几个分出不同结果的分词器,则在词A的切分上被认为是不那么可信的。在图(Graph)的性质上看,就是让这些正确的分词节点的桥接中心性(betweenness centrality)更大,这些节点在图的信息传递过程中起到的效果就越大。如下图所示:

以此为动机,作者设计了以字、词、句三个层次的节点构成的HLG,整体的结构如下图所示:

在HLG中,不同分词器产生的不同的词会产生不同的词节点,而在相同位置分出的相同的词会作为同一个词节点;由于一句话以不同的方式切割会自然地产生不同的语义,因此每个分词器分割的句子都作为一个单独的节点存在,分词器分出的词会与对应的句子节点相连。
HLG的构图方法在实质上就满足了前面提到的去噪的动机。以上图中“西山”节点,和“西”、“山”节点为例,前者(西山)有两个分词器支撑这个分词结果,而后者(西、山)只有一个分词器支撑,前者产生的节点在图中的度数会比后者更高。
得到HLG之后,需要使用图神经网络对这个图进行建模,而图神经网络通常处理的是只有一种节点类型的同构图(Homogeneous Graph),而HLG是有着多种节点类型、多种连边类型的异质图(Heterogeneous Graph)。因此,论文中使用了一种“多步”的信息传播方式,使用多个GCN层来控制不同层级的信息传播,从而实现了对HLG的建模。如下图所示:

整个信息传播过程的输入H^c是预训练语言模型的字符级别表示,输出H’^c是融入了分词信息后的字符级别表示;c、w、s节点分别代表字节点、词节点和句子节点;箭头构成的传播链与数字对应的公式对应,是多个GCN层分别对单跳中的节点信息进行建模,A为邻接矩阵(adjacency matrix)。这个传播过程可以分为两部分:(1)归纳化(Summarization),从字节点到词节点再到句子节点,HLG通过降低的节点数量将字符级别表示按照分词器构造出的路径汇总、归纳到句子级别上;(2)具体化(Concretization),从句节点到词节点再到子节点,HLG将归纳到句级别的表示再逐层根据分词器产生的路径具象化到词、字上。这两部分在上图中以不同的颜色标识。通过这两个步骤后,分词结构信息(以邻接矩阵的形式表达)被纳入到字符级别表示的输出中。
但是,由于句节点的数量(与使用的分词器数量相同)会远远小于词节点和字节点的数量,因此将分词结构表示到句子节点后很难再具象化回字级别,阻碍了信息在图中的传播。这一点在模型训练中会体现为难以训练、效果降低等情况,因此,为了降低这种负面影响,作者引入了ResNet[4]的Skip-Connection,以残差连接的形式在归纳化和具象化过程中相同层级的节点间建立了通路,如下图所示:
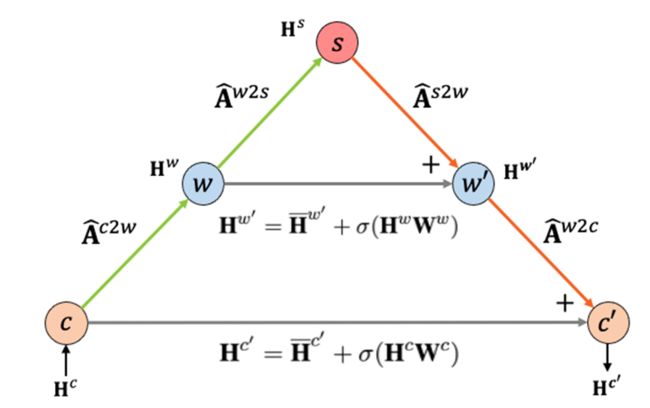
由此,MSIP可以对HLG进行建模,从而在具体任务的微调过程中对模型参数进行学习训练。
与MWA相比,HLG的主要区别是,增加了句子节点,并将信息聚合与分发的方式进行了调整,从对attention权重的分段pooling改成了对层级图的GCN。而它们的输入、输出,以及融入的外部知识实际上都是一致的。下图说明了MWA和HLG在文本表示信息和分词结构信息聚合-分发过程中的异同:

03
—
实 验
论文对提出的模型在多个预训练语言下游任务基准数据集上进行了实验验证,结果如下:

与原生的预训练语言模型相比,HLG带来了稳定的提升;与MWA相比,HLG的实验效果也并不逊色。而在训练和推理效率方面,HLG可以说是一骑绝尘,甩开MWA一大截:

速度上基本上有着7倍以上的提升。对前面提到的“去噪”的动机,作者也通过引入更多分词器的方式进行了验证:

从1个分词器向上提升分词器数量的同时,会得到更多的词节点(新的分词器分出了不同的词),而效果也有微幅提升;引入更多的分词器时,增加的新的词节点的数量开始逐渐下降(由于加入的新的分词器分出的词与已有分词器的大体相同),而带来的性能相对提升也在逐渐降低;引入5个或超过5个分词器,带来的性能提升基本上没有了,甚至可能会出现效果衰退的情况,可能是由于带来了过多的噪声。作者在权衡使用多分词器引入的噪声、提升的效果和增加的预处理开销后,最终还是只使用了3个分词器。
04
—
总 结
这篇论文的贡献点可以归结为几块:(1)对于MWA提出的在预训练模型微调过程中引入新的模块,从而引入外部知识的做法,作者将其总结为了一种强化模块(enhancement module)的适配器(adapter),这样的方法可能在其它领域也能发挥作用;(2)作者提出了HLG来表示中文的分词的结构,并且可以在引入多个分词器的情况下体现出一定的去噪效果。同时,作者以MSIP的方法,成功用图神经网络对HLG这种异质图进行了建模;(3)实验结果表明,这篇论文提出的HLG的方法与MWA带来的模型性能提升不分伯仲,但相比于MWA,HLG节省了至少一半的模型参数量,并且得益于标准的运算模式,HLG的训练、推理速度比MWA快了约7倍以上。这篇论文的代码已经开源,可以在https://github.com/lsvih/HLG 上找到。
参考文献
[1] Enhancing Pre-trained ChineseCharacter Representation with Word-aligned Attention, ACL 2020.
[2] Ernie: Enhanced representationthrough knowledge integration, ACL 2019.
[3] Glyce: Glyph-vectors forchinese character representations, NIPS 2019.
[4] Deep Residual Learning for Image Recognition,CVPR2016.