【PyTorch】PyTorch中常见模块的学习(附实例)| 如何编写一个Pytorch程序 | PyTorch小Tips
Torch常见模块的学习
Torch中的常见模块
矩阵相关
Transpose,Permute,Squeeze,View,Eye,Flattern,Zeros,Arrange,Cat,Scatter,Rolls
-
np.arrange和Torch
>>> np.arange(3) array([0, 1, 2]) >>> np.arange(3.0) array([ 0., 1., 2.]) >>> np.arange(3,7) array([3, 4, 5, 6]) >>> np.arange(3,7,2) array([3, 5]) >>> y=torch.range(1,6) >>> y tensor([1., 2., 3., 4., 5., 6.]) >>> y.dtype torch.float32 >>> z=torch.arange(1,6) >>> z tensor([1, 2, 3, 4, 5]) >>> z.dtype torch.int64 -
Transpose:torch和numpy
tensor = torch.transpose(input, dim0, dim1) x = torch.randn(2, 3) >>> x tensor([[ 1.0028, -0.9893, 0.5809], [-0.1669, 0.7299, 0.4942]]) # 2 * 3 >>> torch.transpose(x, 0, 1) <==> torch.transpose(x, 1, 0) tensor([[ 1.0028, -0.1669], [-0.9893, 0.7299], [ 0.5809, 0.4942]]) # 3 * 2 x.transpose(0,1) # 3 * 2 x=np.random.rand(3,2,5,6) # 四个axes(轴),分别的维度是3,2,5,6 np.transpose(x,(0,2,1,3)) x.transpose(0,2,1,3) # 3,5,2,6 -
Permute
# Permute更换维度的位置 >>> x = torch.randn(2, 3, 5) -> int x[2][3][5], rand init >>> x.size() torch.Size([2, 3, 5]) >>> x.permute(2, 0, 1).size() torch.Size([5, 2, 3])- Permute和Transpose的区别:
torch.transpose只能对二维矩阵进行转置,permute可以对任意高维- Np里面的
transpose也可以对高维度。 - 相当于
permute只可以操作tensor的两个维度
- Permute和Transpose的区别:
-
View
# 把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的) # 然后按照参数组合成其他维度的tensor # 相当于得到一维数据再重新组织维度 a=torch.Tensor([[[1,2,3],[4,5,6]]]) b=torch.Tensor([1,2,3,4,5,6]) print(a.view(1,6)) print(b.view(1,6)) >>> tensor([[1., 2., 3., 4., 5., 6.]]) # 1 * 6 print(a.view(3,2)) >>> tensor([[1., 2.], [3., 4.], [5., 6.]]) # 3 * 2 a.view(-1,6) # 只保留一个[] >>> tensor([-,-,-,-,-,-]) a.view(-1) # 降成一维- 结合Permute和View
a=np.array([[[1,2,3],[4,5,6]]]) unpermuted=torch.tensor(a) print(unpermuted.size()) # ——> torch.Size([1, 2, 3]) ''' (2,0,1): 组合顺序。 先组合'2'(3-dim):[_,_,_] 再组合'0'(1-dim):[[_],[_],[_]] 再组合'1'(2-dim):[[[1,4],[[2,5]],[[3,6]]] // permute ''' permuted=unpermuted.permute(2,0,1) print(permuted.size()) # ——> torch.Size([3, 1, 2]) tensor([[[ 1, 4]], [[ 2, 5]], [[ 3, 6]]]) # print(permuted) view_test = unpermuted.view(1,3,2) print(view_test.size()) # ——> torch.Size([1, 3, 2]) tensor([[[ 1, 2], [ 3, 4], [ 5, 6]]]) # print(view_test) -
Squeeze, Unsqueeze
# Squeeze: 对维度压缩,去掉一的维度(就是[[[...[_]...]]] -> [_]) # Unsqueeze: 在指定维度(位置)加上1的维度(添加一层[[_]]) x = torch.rand(3, 2, 1, 2, 1) x = x.squeeze() or torch.squeeze(x) # 3,2,2 # 如果指定的维度为1则压缩,否则没有操作 x = torch.rand(3, 2, 1, 2, 1) x = x.squeeze(0) or torch.squeeze(x,0) # 3,2,1,2,1 x = x.squeeze(2) or torch.squeeze(x,2) # 3,2,2,1 # unsqueeze(0) : [] -> [[]] # unsqueeze(2) : (3,2,4,2,1) -> (3,2,1,4,2,1) -
Scatter
scatter_(input, dim, index, src)将src中数据根据index中的索引按照dim的方向填进input中- scatter() 和 scatter_() 的作用是一样的,不过 scatter() 不会直接修改原来的 Tensor,而 scatter_() 会
# dim就是对输入的哪一个维度进行沿着改变 self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0,下面就是这一种 self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1 self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2 x = torch.rand(2, 5) # x可以是标量(常数) #tensor([[0.1940, 0.3340, 0.8184, 0.4269, 0.5945], # [0.2078, 0.5978, 0.0074, 0.0943, 0.0266]]) torch.zeros(3, 5).scatter_(0, torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]), x) #tensor([[0.1940, 0.5978, 0.0074, 0.4269, 0.5945], # [0.0000, 0.3340, 0.0000, 0.0943, 0.0000], # [0.2078, 0.0000, 0.8184, 0.0000, 0.0266]]) # 过程:self[index[0][0]][0] = self[0][0] <- src[0][0] = 0.1940 # self[index[1][0]][0] = self[2][0] <- src[1][0] = 0.2078 # 常用于创建onehot,就是在label维赋值1 torch.zeros(batch_size, class_num).scatter_(1, label, 1) #tensor([[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], # [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], # [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], # [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.]]) -
Flattern:维度压缩
input = torch.randn(2,3,4,4) out = input.flattern(start_dim=1,end_dim=3) # 2,48 -
Tensor常见操作:Zeros,Eye,rand,empty,max,cat,stack
# 空向量 x = torch.empty(2,3) # 2*3 # 随机数 x = torch.rand(5,3) # 5*3, rand floar [0,1) x = torch.randn(5,3) # 5*3, normal distribution ~ N(0,1) torch.randint(low=0, high, size) # 返回shape=size,[low, high)之间的随机整数 # 零矩阵 x = torch.zeros(5, 3, dtype=torch.long) # 单位矩阵 I = torch.eye(3) # tensor([[1,0,0],[0,1,0],[0,0,1]]) # 1填充 x = torch.ones(5, 3, dtype=torch.double) # dtype制定数据类型(1.) # 运算 torch.mm(tensor1, tensor2, out=None) #tensor的矩阵乘法matrix multiplication torch.mul(tensor1, tensor2, out=None) #tensor的点乘Hadamard product # 最大值操作 a = torch.max(tensor) # tensor中所有元素的最大值,可用于Softmax输出 b = torch.max(input, dim, keepdim=False, out=None) #对dim维度上的元素取最大值,返回两个tensor,第一个是dim上的最大值,第二个是最大值所在的位置 # 拼接 torch.cat((a,b,c,...), dim=0, out=None) # dim是拼接的维度 一个技巧:inputs = torch.cat(inputs).view(len(inputs), 1, -1) #先cat再view torch.stack((a,b,c) ,dim = 2) #建立一个新的维度,然后再在该纬度上进行拼接 # like torch.*_like(input):返回一个和input shape一样的张量,*可以为rand、randn... # 转Numpy b = a.numpy() # torch tensor转numpy array b = torch.from_numpy(a) # numpy array转torch tensor(两种转都是没有复制,而是直接引用的 a , idx_sort = torch.sort(a, dim=0, descending=True) #排序,返回排序后的tensor和下标 # 求导 x = torch.ones(2, 2, requires_grad=True) # True,将x看成待优化的参数(权重) model.zero_grad() optimizer.zero_grad() loss.backward() # 反向传播 optimizer.step()
数据操作
Pooling(Avg,Max),Linear,Conv(1D,2D)
-
索引与切片操作
a = torch.rand(4, 3, 28, 28) print(a.shape) # torch.Size([4, 3, 28, 28]) # 索引 print(a[0, 0].shape) # torch.Size([28, 28]) print(a[0, 0, 2, 4]) # tensor(0.1152) # 切片 print(a[:2].shape) # torch.Size([2, 3, 28, 28]) - 切下来了0,1 print(a[:2, :2, :, :].shape) # torch.Size([2, 2, 28, 28]) print(a[:2, -1:, :, :].shape) # torch.Size([2, 1, 28, 28]) # ...的用法 print(a[...].shape) # torch.Size([4, 3, 28, 28]) print(a[0, ...].shape) # torch.Size([3, 28, 28]) print(a[:, 1, ...].shape) # torch.Size([4, 28, 28]) print(a[..., :2].shape) # torch.Size([4, 3, 28, 2]) -
掩码取值
masked_selectx = torch.rand(3, 4) # tensor([[0.0864, 0.8583, 0.9847, 0.6263], # [0.4546, 0.1105, 0.5902, 0.7919], # [0.3894, 0.8882, 0.3354, 0.1561]]) mask = x.ge(0.5) # ge 是符号 > # tensor([[False, True, True, True], # [False, False, True, True], # [False, True, False, False]]) print(torch.masked_select(x, mask)) # tensor([0.8583, 0.9847, 0.6263, 0.5902, 0.7919, 0.8882]) -
nn.Dropout(Prob)-
把输入向量的随机一部分置零
-
用法:
dropout = nn.Dropout(drop_prob) ... x = linear(x) x = dropout(x) -
如果仅仅使用F.dropout(x)而不改变training值,是没有启用dropout的
-
-
Pooling
- MaxPool2D, AvgPool2D
-
Conv2D, Conv1D
-
Conv2d(in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode=‘zeros’)- in_channels:输入的通道数目 【必选】
- out_channels: 输出的通道数目 【必选】
- kernel_size:卷积核的大小,类型为int 或者元组,当卷积是方形的时候,只需要一个整数边长即可,卷积不是方形,要输入一个元组表示 高和宽。【必选】
- stride: 卷积每次滑动的步长为多少,默认是 1 【可选】
- padding: 设置在所有边界增加 值为 0 的边距的大小(也就是在feature map 外围增加几圈 0 ),例如当 padding =1 的时候,如果原来大小为 3 × 3 ,那么之后的大小为 5 × 5 。即在外围加了一圈 0 。【可选】
- dilation:控制卷积核之间的间距(什么玩意?请看例子)【可选】
-
( N , C i n , H , W ) → ( N , C o u t , H o u t , W o u t ) (N,C_{in},H,W) \to (N,C_{out},H_{out},W_{out}) (N,Cin,H,W)→(N,Cout,Hout,Wout)
-
H out = ⌊ H in + 2 × padding [ 0 ] − dilation [ 0 ] × ( kernelsize [ 0 ] − 1 ) − 1 stride [ 0 ] + 1 ⌋ H_{\text {out }}=\left\lfloor\frac{H_{\text {in }}+2 \times \text { padding }[0]-\text { dilation }[0] \times(\text { kernelsize }[0]-1)-1}{\text { stride }[0]}+1\right\rfloor Hout =⌊ stride [0]Hin +2× padding [0]− dilation [0]×( kernelsize [0]−1)−1+1⌋
-
输入的数据(如采用
nn.module()则总是以minibatch的方式实现的(对应N,就是batch-size)。因此对于数据维度的操作就是要经常进行的。
-
-
Embedding
-
Linear
-
Softmax,LogSoftmax,Sigmoid
-
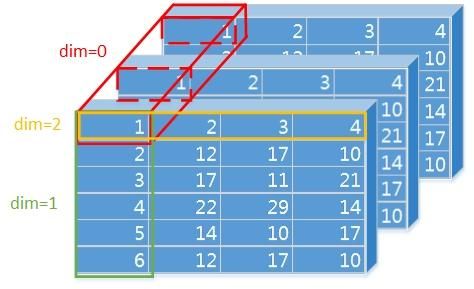
对Softmax
dim的理解 -
dim等于几就是在某dim上和为1。如果dim=-1就是默认在最里面(行)。- 实质上是
dim = input.dim() + 1 + dim = input.dim()
>>> a.size() torch.Size([2, 3, 4]) >>> d0 = F.softmax(a,dim=0) >>> d0 tensor([[[0.5254, 0.4864, 0.1925, 0.0818], [0.2934, 0.4182, 0.2627, 0.3536], [0.1150, 0.8950, 0.0199, 0.2185]], [[0.4746, 0.5136, 0.8075, 0.9182], [0.7066, 0.5818, 0.7373, 0.6464], [0.8850, 0.1050, 0.9801, 0.7815]]]) >>> d1 = F.softmax(a,dim=1) >>> d1 tensor([[[0.7253, 0.2791, 0.3565, 0.1441], [0.1937, 0.2429, 0.4506, 0.6355], [0.0809, 0.4780, 0.1930, 0.2203]], [[0.3756, 0.4279, 0.1220, 0.4535], [0.2674, 0.4906, 0.1032, 0.3257], [0.3570, 0.0815, 0.7748, 0.2209]]]) >>> d2 = F.softmax(a,dim=2) >>> d2 tensor([[[0.5081, 0.2552, 0.1646, 0.0722], [0.1535, 0.2512, 0.2353, 0.3599], [0.0818, 0.6306, 0.1285, 0.1591]], [[0.2060, 0.1209, 0.3097, 0.3634], [0.1814, 0.1715, 0.3241, 0.3229], [0.0829, 0.0097, 0.8325, 0.0749]]]) >>> d_ = F.softmax(a,dim=-1) >>> d_ tensor([[[0.5081, 0.2552, 0.1646, 0.0722], [0.1535, 0.2512, 0.2353, 0.3599], [0.0818, 0.6306, 0.1285, 0.1591]], [[0.2060, 0.1209, 0.3097, 0.3634], [0.1814, 0.1715, 0.3241, 0.3229], [0.0829, 0.0097, 0.8325, 0.0749]]]) - 实质上是
-
模型构建
Module list
-
self.layers = nn.ModuleList() for i_layer in range(self.num_layers): layer = BasicLayer(...) self.layers.append(layer) -
参数初始化
-
在模型外部初始化
for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.Linear)): # 卷积层和全连接层参数初始化 nn.init.normal(m.weight.data) m.bias.data.fill_(0) elif isinstance(m, nn.BatchNorm2d): # BatchNorm2d层参数初始化 m.weight.data.normal_() -
在网络内部初始化
def weights_init(m): classname = m.__class__.__name__ if classname.find("Conv") != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find("BatchNorm2d") != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) def my_model(nn.Module): def __init__(self): # 因为self代表类的实例化, # 也就是说谁调用这个类的方法,self就指向谁 # 我们可以在__init()__中,直接初始化模型,一般放在最后 self.apply(weights_init)
-
复杂链接的实现
- 例如Transformer Decoder
训练
- Criterion,optim;optim.zero_grad(),模式(train,eval)
其他
-
Detach
- 希望保持一部分的网络参数不变,只对其中一部分的参数进行调整。或训练部分分支网络,并不让其梯度对主网络的梯度造成影响。这时候我们就需要使用
detach()函数来切断一些分支的反向传播.
''' 返回一个新的tensor,从当前计算图中分离下来。但仍指向原变量的存放位置. 不同之处只是requirse_grad为false.得到的这个tensor永远不需要计算器梯度,不具有grad. 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad. 当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播. ''' a = torch.tensor([1, 2, 3.], requires_grad=True) print(a.grad) out = a.sigmoid() print(out) #添加detach(),c的requires_grad为False c = out.detach() print(c) #这时候没有对c进行更改,所以并不会影响backward() out.sum().backward() print(a.grad) # None # tensor([0.7311, 0.8808, 0.9526], grad_fn=) # tensor([0.7311, 0.8808, 0.9526]) # tensor([0.1966, 0.1050, 0.0452]) - 希望保持一部分的网络参数不变,只对其中一部分的参数进行调整。或训练部分分支网络,并不让其梯度对主网络的梯度造成影响。这时候我们就需要使用
-
参数打印
model.parameters()模型的所有参数;nn.parameter()人工定义一组需要被优化的值
-
人工修改参数
-
模型的保存和加载
torch.save(model.state_dict(), PATH) # 保存模型的参数 torch.save(model, PATH) # 保存整个模型 model.load_state_dict(torch.load(PATH)) # 加载模型的参数 model = torch.load(PATH) # 加载整个模型 # 保存 checkpoint = { 'epoch': epoch, 'model_state_dict': model.state_dict(), # 模型参数 'optimizer_state_dict': optimizer.state_dict(), # 优化器参数 'loss': loss, ... } PATH = './checkpoint/ckpt_best_%s.pth' %(str(epoch)) # path中要包含.pth torch.save(checkpoint, PATH) # 加载 model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss']
Torch面经
-
pytorch中train和eval有什么不同
model.train()——训练时候启用- 启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为True
model.eval()——验证和测试时候启用- 不启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为False
with optimizer.zero_grad()
- train模式会计算梯度,eval模式不会计算梯度(即不会反向传播
loss.backward())
编写一个PyTorch程序的步骤
定义神经网络
-
定义网络架构(模型的forward,通常用一个继承自torch.nn.Module的类)
__init__():将nn实例化(每一个nn都是一个类),参数自己定义forward(self, x):模型的forward,参数x为模型输入self.add_module("conv", nn.Conv2d(10, 20, 4))# self.conv = nn.Conv2d(10, 20, 4) 和这个增加module的方式等价torch.nn.Embedding(num_embeddings, embedding_dim, ...)#是一个矩阵类,里面初始化了一个随机矩阵,矩阵的长是字典的大小,宽是用来表示字典中每个元素的属性向量,向量的维度根据你想要表示的元素的复杂度而定。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。
-
定义输入输出
-
定义loss(如果用nn需要实例化才定义,否则用functional直接在训练中用)
-
定义优化器
训练
-
初始化,如model.zero_grad()将一些参数初始化为0
-
准备好输入 比如Dataloader实现
__getitem__(),__len__()以及__init__() -
将模型设置为train模式
-
将模型forward
-
计算loss和accuracy
-
back propagation并计算权重的梯度
-
做validation
-
打印Epoch、loss、acc、time等信息
验证或测试
-
准备好输入
-
将模型设置为eval模式
-
将模型forward
-
计算loss和accuracy
-
打印loss、acc等信息
Torch使用的7个Tips
-
直接在对应设备中创建Tensor
a = torch.ones((1,2,3), device = 'cuda:0') -
多使用Sequentiial
self.layers = nn.sequential(self.linear(in_dim, out_dim), nn.relu(), nn.linear(), ...) def forward(self,x): out = self.layers(x) return out -
不要只使用List存层
- Python List无法移动到GPU上
# 示例 # 建立: self.layers = [] for _i inn layers_count: self.layers.append() ... # 添加这一句: self.layers = nn.Sequential(*self.layers) def forward(self,x): z = self.input_layer(x) z = self.input_activation(z) for layer in self.layers: z = layer(z) # 当传入GPU上的数据时有些参数还是在CPU上的,List中的层不能被很好的跟踪从而更换device -
使用分布(
torch.distributions)dist = Categorical(logits=output) dist.probs() dist.sample() # 采样 dist_1 = Categorical(logits=output[0]) dist_2 = Categorical(logits=output[1]) kl_divergence(dist_1, dist_2) -
使用
detach()on long-term metrics''' 使用detach或者item获得结果的数值(去掉grad_fn),也就是把结果从计算图上剥离开来 ''' # training loop loss_log = [] for batch in batches: output = model(batch) target = _ loss = criterion(output, target) loss_log.append(loss.detach()) # loss.detach() or loss.item() # optimization print(loss_log) -
从GPU中删除模型
- 采用垃圾回收
gc.collect()
- 采用垃圾回收
-
在训练前使用
model.eval() -
如果在forward中需要生成一些新tensor,我们有如下方法:
- 生成在CPU上,在CPU上计算。
- 生成在cpu上,然后复制移动到GPU上。
- 直接生成在GPU上。(⭐️)
-
CPU瓶颈:
-
(Windows)如果设置num_workers不为0后出现boken pipe问题, 就将主程序包含进下面的代码
if __name__ == '__main__':
-