SCNN:A General Distribution based Statistical Convolutional Neural Network with Application to Video
目录
Video Object Detection: an Application
论文地址
SCNN:A General Distribution based Statistical Convolutional Neural Network with Application to Video
摘要
最近开发了各种卷积神经网络(CNN),其在图像识别,目标检测和跟踪等计算机视觉任务中的精度可与人类媲美。但是,这些网络中的大多数都可以在图像处理系统中处理一帧图像。时间,并且可能无法充分利用通常存在于同一图像或来自视频的相邻帧的多个通道中的时间和上下文相关性,因此限制了可实现的吞吐量。此限制源于以下事实:现有的CNN使用确定性数字进行运算。在本文中,我们提出了一种新颖的统计卷积神经网络(SCNN),该网络扩展了现有的CNN体系结构,但直接对相关分布而不是确定性数进行运算。通过引入参数化的规范模型对相关数据进行建模并定义CNN训练和推理所需的相应操作,我们证明了SCNN可以有效处理相关图像的多个帧,从而在现有CNN模型上实现了显着的加速。我们以基于CNN的视频对象检测为例,以说明所提出的SCNN作为通用网络模型的有用性。实验结果表明,即使是非优化的SCNN实施,仍然可以比现有的CNN加快178%的速度,而精度会略有下降。我们以基于CNN的视频对象检测为例,以说明所提出的SCNN作为通用网络模型的有用性。实验结果表明,即使是非优化的SCNN实施,仍然可以比现有的CNN加快178%的速度,而精度会略有下降。我们以基于CNN的视频对象检测为例,以说明所提出的SCNN作为通用网络模型的有用性。实验结果表明,即使是非优化的SCNN实施,仍然可以比现有的CNN加快178%的速度,而精度会略有下降。
引言
借助深度卷积神经网络(CNN)强大的特征提取功能以及相关的深度学习框架的许多优化实现(Xu等,2017),各种计算机视觉任务的性能得到了显着改善。例如,在图像识别和目标检测中,ResNet(He等人,2016),DenseNet(Huang等人,2017)和YOLO(Redmon和Farhadi 2017)等框架等深层CNN架构,更快的R-CNN(Ren等人。 (2015年)在出版时均以惊人的速度领先于当时的最先进技术。但是,任何基于CNN的框架的支柱都是它基于确定性的权重和输入进行操作(Xu等人2018a; Xu等人2018b)。这些框架在训练和推理期间一次处理一张图像。这显然是不理想的,因为它很大程度上忽略了信道和相邻帧之间存在的时间和上下文相关性。为了打破这一主流,本文提出了通过从相关输入(例如视频中的相邻帧)中提取参数化规范分布来显式地对这种相关进行建模的方法,并设计一个统计卷积神经网络(SCNN)直接传播这些相关分布。通过将我们的SCNN的确定性运算替换为对参数化规范分布进行操作的统计对应项,可以轻松地将我们的SCNN集成到现有的CNN架构中。然后,只需对现有的基于梯度下降的方案进行少量修改,就可以使用相同的前向和后向传播程序来训练我们的SCNN。
更具体地说,我们首先通过独立成分分析(ICA)构建线性参数化规范形式,以表示每个输入成分的统计分布,以捕获其时间和上下文相关性。然后,我们根据参数化的规范形式(包括其向后传播的各种局部梯度)定义所有必需的CNN操作(例如卷积,ReLU,批处理规范化等),从而使我们能够轻松地将SCNN与任何现有的CNN实现框架集成。为了展示所提出的SCNN的有效性,我们将其进一步应用于视频对象检测任务,并提出了一种新的目标函数,可以改进基于SCNN的训练。尽管在静态图像的目标检测方面已经取得了很多成功(Ren等人2015; Redmon和Farhadi 2017; Lin等人2018; Liu等人2016),但视频对象检测的性能仍有很大空间进行改进,尤其是其实时吞吐量。自从在ImageNet竞赛中引入以来,已经提出了多种解决方案(Kang等人2017; Han等人2016),其中大多数解决方案通过扩展静态图像对象检测方法来考虑相邻帧的时间信息来解决该问题。但是,它们的效率对于在线检测来说并不令人满意,并且对于训练而言,生成视频小管需要几天的时间(Kang等人2017)。最近的一项研究(Zhu et al.2017)提出了一种流引导的特征聚合,其中考虑了在特征级别而非框级别的相邻帧,但它需要重复采样和复杂建模。仍然希望有一种更直接有效的对相关相邻帧建模的方法。
(Our main contributions in this paper are as follows. 1) We propose a novel statistical convolutional neural network that can act as a backbone alternative to any existing CNN architectures and operates directly on distributions rather than deterministic numbers , 2) We use a parameterized canonical model to capture correlated input data for CNN and reformulate popular CNN layers to adapt their forward and backward computation for parameterized canonical models. 3) We adopt video object detection as an examplar application and introduce a new objective function for better training of SCNN. 4) We conduct experiments on an industrial UAV object detection dataset and show that SCNN backbone can achieve up to 178% speedup over conventional counterpart with slight accuracy degradation.)
我们在本文中的主要贡献如下。 1)我们提出了一种新颖的统计卷积神经网络,该网络可以充当任何现有CNN架构的骨干替代方案,并且可以直接在分布上运行,而不是在确定性数上进行操作; 2)我们使用参数化规范模型来捕获CNN的相关输入数据并重新制定流行度 CNN层将其正向和反向计算调整为参数化规范模型。 3)我们将视频目标检测作为示例应用程序,并引入了新的目标函数以更好地训练SCNN。 4)我们在工业无人机目标检测数据集上进行了实验,结果表明,SCNN骨架可以比传统的同类对象提高多达178%的速度,但精度会略有下降。
Review of ICA
ICA是信号处理中的一种众所周知的技术,用于将多元信号分离为一组统计上彼此独立的加性随机子分量。 通常将随机子组件建模为非高斯分布。 在某些情况下,这些随机子组件的概率分布的先验知识也可以合并到ICA中。 随机子分量也称为相应多元信号的基础。 我们将n维多元信号表示为随机向量D =(D1,D2,...,Dn)T。 随机子分量表示为随机向量X =(X1,X2,...,Xm)T。 对于多元信号随机向量D的给定的N个样本集(实现),可以将N个样本中的每个分量Di视为由m个独立随机子分量的某种实现之和生成,这由下式给出:
![]()
其中![]() 是相应随机子成分
是相应随机子成分![]() 的混合权重。 我们可以将它们紧凑地排列成矩阵形式,如下所示
的混合权重。 我们可以将它们紧凑地排列成矩阵形式,如下所示
![]()
其中A是混合矩阵。 ICA的目的是估计混合矩阵A和随机子分量X(即,X = WD)的相应实现。 基X的实现可以通过直接将A反转(即,![]() )或通过A的伪逆来获得。
)或通过A的伪逆来获得。
ICA也已扩展为考虑添加零均值不相关高斯噪声![]() 的情况。 在不失一般性的前提下,我们可以将所有基础(随机子组件)标准化为零均值和标准差为1。换句话说,我们拥有
的情况。 在不失一般性的前提下,我们可以将所有基础(随机子组件)标准化为零均值和标准差为1。换句话说,我们拥有
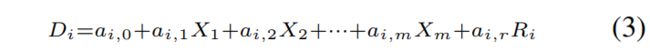
其中![]() 是
是![]() 的平均值,
的平均值,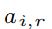 是建模的不相关高斯噪声项的权重。
是建模的不相关高斯噪声项的权重。
Statistical Convolutional Neural Network Correlated Inputs Modeling(统计卷积神经网络相关输入建模)
使用CNN模型的许多现有模型都具有表现出强大的时间和上下文(空间)相关性的输入,例如视频流中的多个相邻帧。 因此,我们可以将这些输入建模为多元信号。 对于给定的N个输入样本集(实现),例如视频片段的多个相关帧,我们可以通过ICA将输入的每个分量表示为m个独立随机子分量集的线性加法模型,如等式(3)所示。在本文的其余部分,我们将N定义为提取跨度,将m定义为基本维。 此外,由于随机子分量![]() 在所有输入分量之间共享,因此我们可以使用上述模型来紧凑地捕获时间和上下文相关性。 我们称这种模型为线性参数化典范模型,并将权重(如
在所有输入分量之间共享,因此我们可以使用上述模型来紧凑地捕获时间和上下文相关性。 我们称这种模型为线性参数化典范模型,并将权重(如![]() )称为参数。
)称为参数。
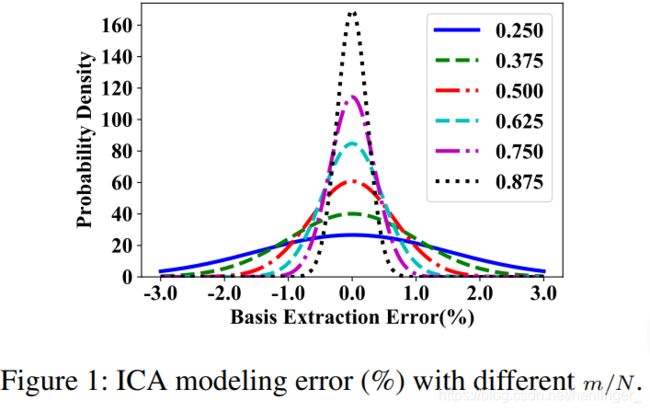
为了证明ICA对视频中相关帧进行建模的准确性,我们从实验数据集中的一些小视频片段中提取了分布(DAC-Contest 2018),并在图1中描述了原始数据与解混结果之间的误差分布。从图中我们可以看出,通常提高m / N的比率会减小误差,并且误差大多限制在3%以内。
在CNN的背景下,这种类型的相关输入建模引发了许多有趣的问题。 (1)对于给定的带有模型参数的经过训练的CNN网络,我们如何对这种参数化的规范模型进行推断? (2)如何训练这样的CNN网络,其中每个输入都以参数化规范形式表示? 在本文的其余部分,我们将提供解决以上两个问题的答案。
由于我们将输入建模为参数化统计分布的方式,我们将网络称为SCNN。 使用参数化的规范模型,我们的SCNN的总体结构如图2所示。在以下部分中讨论的细节中,输入视频流被分为多个片段,每个片段包含多个相关的相邻帧。 相同片段中的那些图像将由原始图像大小的一个图像建模,但其每个像素均采用规范形式。 这些规范形式通过CNN向前和向后传播,以进行训练和推理。 在网络的输出端,通过插入每个输入视频片段的随机子组件(X = WD)的估计实现,将所有规范形式转换为相应的标量值。 这样,我们获得了具有标量值的特征图,因此可以执行常规的目标函数评估。
Forward Propagation in SCNN(前向传播)
在典型的CNN网络中,有许多常用的层,例如完全连接层(FC),卷积层(CN),ReLU层,最大合并层,批归一化层。 接下来,我们将在SCNN中为这些常用层提供相应的实现细节。 同样,我们想强调的是,此处的讨论并不限于任何特定的CNN架构。 在我们的实验中,我们将展示我们在各种CNN架构上的实现。
在深入研究每一层实现的细节之前,我们注意到这些层有两个核心操作:(1)一组输入数字的加权和(这在FC和CN层中经常使用),和( 2)一组输入数字最大值(经常用于ReLU和max-pooling层)。在SCNN中,以上两个操作的输入数字不再是确定性数字,而是参数化统计分布。我们首先讨论如何为这两个核心业务提供解决方案。请注意,有关统计和分析的一些讨论已在统计时序分析领域的现有文献中进行了讨论(Xiong,Zolotov和Visweswariah 2008; Cheng,Xiong和He 2009; Visweswariah等2006)。 ; Singh和Sapatnekar 2006)。我们从他们的工作中获得了很多启发。为了完整起见,我们仅重复本文的要点,但请感兴趣的读者参考这些参考资料以获取更多详细信息和证据。
Sum operation 对于两个输入![]() 和
和![]() ,它们的和可以表示为:
,它们的和可以表示为:
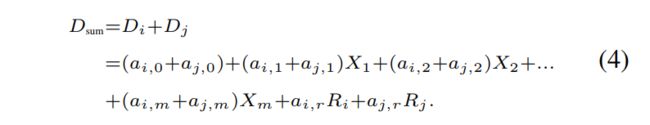
如我们所见,上面定义的和运算将给我们返回类似的参数化规范形式。 这很重要,因为它使我们能够跨层重复执行类似的操作。 因此,对于多个输入,可以轻松应用类似的求和运算。 最有趣的是,计算仅涉及那些参数,而不涉及随机子组件。
Max operation 最大操作涉及更多。 我们从最常见的场景开始,在该场景中,随机子分量![]() 的分布被建模为高斯分布。 在这种情况下,对于两个输入
的分布被建模为高斯分布。 在这种情况下,对于两个输入![]() 和
和![]() ,它们的最大值可以表示为:
,它们的最大值可以表示为:
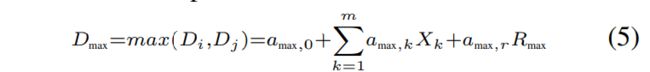
其中![]() 和
和![]() 是通过在两侧匹配上述方程式的第一和第二矩而获得的;
是通过在两侧匹配上述方程式的第一和第二矩而获得的; ![]() 是通过(Visweswariah等人,2006年)引入的紧密度概率获得的,表示一个分布大于(或支配)另一个分布的概率,由 (最后是正则)
是通过(Visweswariah等人,2006年)引入的紧密度概率获得的,表示一个分布大于(或支配)另一个分布的概率,由 (最后是正则)

值得注意的是,(Sinha,Shenoy和Zhou 2005)证明了![]() 总是非负的。 为简单起见,我们使用
总是非负的。 为简单起见,我们使用![]() 和
和![]() 表示
表示![]() (β)和
(β)和![]() (β),使用sum和max表示分布之间的统计运算,并且在没有歧义的情况下将使用该表示法。
(β),使用sum和max表示分布之间的统计运算,并且在没有歧义的情况下将使用该表示法。
与sum运算相同,上面定义的max运算将给我们返回类似的参数化规范形式。 这很重要,因为它允许我们跨层重复执行类似的max操作。 因此,对于多个输入,我们可以重复应用两个max输入操作,并获得最终的多输入最大结果,即

同样的想法,在参考文献 (Xiong et al. 2006; Mogal et al. 2007)中,讨论了更复杂的方法来处理多个输入和非高斯分布的最大运算。 为了节省空间,我们在此不再赘述。
FC & CN layers 两层操作的关键是sum运算的权重计算。 当输入参数化为规范形式时,我们可以通过两个逻辑步骤分解加权和:(1)对于每个输入,我们按权重对输入进行缩放,并获得相似的规范形式;(2)对于剩余的sum运算,其执行与一组规范形式的总和相同。
对于FC,给定在第l层具有p分布![]() 的输入,正向运算计算权重w的第j个输出分布
的输入,正向运算计算权重w的第j个输出分布![]() 为:
为:

对于CN,输入分布张量将给出为![]() ,并且卷积滤波器
,并且卷积滤波器![]() 对于下一层,我们在位置x,y处具有SCNN CN的前向传播,表示为:
对于下一层,我们在位置x,y处具有SCNN CN的前向传播,表示为:

ReLU and max-pooling layers 由于ReLU和max-pooling层中的关键操作都是max操作,因此我们可以轻松地如上所述扩展max操作来处理规范输入。 在ReLU的情况下,参考点不必为零,可以将其定义为分布。 但是在我们当前的实现中,我们仍然为ReLU选择一个常量引用。
在最大池化层中,使用max操作从mask下的先前层分布生成新分布。 给定输入分布张量![]() 和最大池化滤波器
和最大池化滤波器![]() ,问题是从分区张量获得max 分布的输出分布张量
,问题是从分区张量获得max 分布的输出分布张量![]() 。 因此,跨度为s而没有填充的前向传播可以表示为:
。 因此,跨度为s而没有填充的前向传播可以表示为:
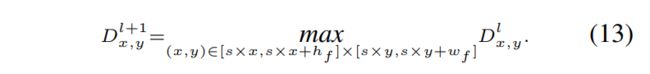
在传统的最大池化层中,卷积核mask下当前层的最大值位置被存储以用于反向传播。 在SCNN最大池实现期间,我们存储正向传播过程中相应分布之间的紧密度概率,这表明当前层对下一层分布的贡献。
Batch normalization layer 在SCNN中,我们不遵循传统的批处理规范化层 (Ioffe and Szegedy 2015)的定义。 取而代之,考虑到规范输入,我们定义以下操作:给定具有基本灵敏度![]() 和方差
和方差![]() 的输入分布
的输入分布![]() ,归一化输出分布
,归一化输出分布![]() 表示为:
表示为:

其中γ,β是学习系数。 代替评估小批量的值,我们对每个输入分布执行归一化。 注意,![]() 不参与规范化。
不参与规范化。
Back Propagation in SCNN(反向传播)
反向传播是通过计算成本函数相对于网络参数的各种梯度来训练SCNN的关键,术语梯度依赖于计算各种运算输出相对于其输入的偏导数。
Partial derivative for sum(偏导) 给定两个分布![]() 以及两个权重wi,wj,总和
以及两个权重wi,wj,总和![]() ,即
,即![]() 的偏导数。 Di的灵敏度表示为
的偏导数。 Di的灵敏度表示为
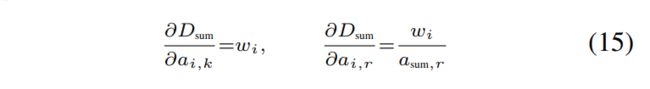
其中k∈{0,m}。 然后借助求和运算的梯度,得到了SCNN中FC和CN的导数。 给定层l+1处![]() 的梯度为
的梯度为![]()
![]() ,则层l处分布
,则层l处分布![]()
![]() 中每个灵敏度的梯度表示为:
中每个灵敏度的梯度表示为:
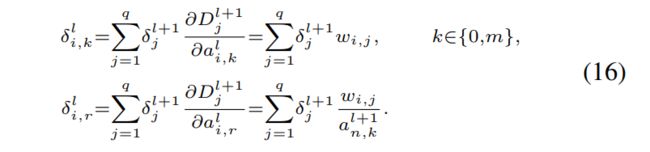
总cost L的偏导数
SCNN CN层的导数遵循相同的路径。 给定Dl 1 w.r.t. 总成本L为δl,位置x,y处的分布Dl x,y中的每个敏感度的梯度为δl x,y,显示为
卷积权重的梯度推导为

Partial derivative for max max在分布中的导数主要涉及SCNN ReLU和Max-pooling层的反向传播。 给定具有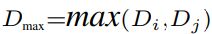 的两个分布
的两个分布![]() ,
,![]() 相对于
相对于![]() 的均值和方差的梯度由(Xiong, Zolotov, and Visweswariah 2008)得出。 我们遵循类似的程序,并得出
的均值和方差的梯度由(Xiong, Zolotov, and Visweswariah 2008)得出。 我们遵循类似的程序,并得出![]() 的各个灵敏度相对于
的各个灵敏度相对于![]() 的梯度。 对于p∈{1,m},我们首先计算θ,φ,Φ相对于
的梯度。 对于p∈{1,m},我们首先计算θ,φ,Φ相对于![]() 的梯度。 然后获得
的梯度。 然后获得![]() 相对于
相对于![]() 和
和![]() 的梯度为
的梯度为

ReLU and max-pooling layers 对于ReLU,由于在分布之间独立使用max,因此直接应用max的推导。 对于最大池,由于结果是通过重复应用两个输入max运算获得的,因此输入分布的梯度是通过迭代应用具有存储的紧密度概率的max的导数获得的。
Partial derivative for batch normalization 由于重新制定的批次归一化层不涉及分配操作,因此派生遵循传统方法。 给定损耗的梯度L,分布![]() 中的灵敏度梯度为
中的灵敏度梯度为
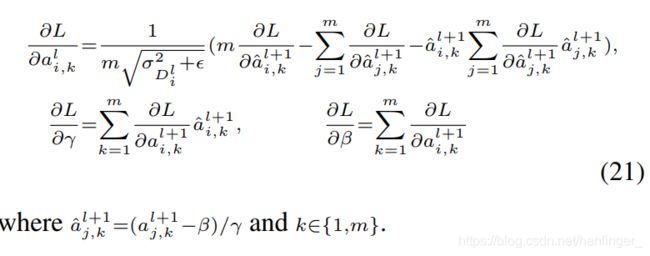
Training, Inference, and Complexity Analysis
通过如上所述的反向传播,可以如下容易地进行训练。 首先由ICA使用预定义的提取范围来提取分布。 然后,提取的分布将通过构造的SCNN层传播。 在进入评估模块之前,将传播的分布取消混合以形成时间特征图。 当使用建议的目标函数进行评估后获得损失时,误差会通过导出的路径向后传播。 计算规范形式分布的梯度以充当相应层的梯度输出。 然后,基于获得的梯度输出和预定义的学习率,更新具有确定性数的权重。
SCNN的加速主要来自以下事实:N个输入图像由相同大小的单个参数化规范模型建模。 另一方面,包括前向传播中的最大值,总和和分配权重在内的每一层的计算复杂度增加了O(m)。 此外,SCNN要求在输入端通过ICA提取参数化的规范模型,这会带来额外的复杂性开销。 幸运的是,有了在GPU上可用的快速ICA实现,与SCNN推理时间相比,执行时间可以忽略不计(Ramalho,Tomas和Sousa 2010; Kumara等人2016)。 因此,具有SCNN骨干的网络可以实现大约N / m的推理速度。稍后的实验将支持此类分析。
Extension to Nonlinear Canonical Form
请注意,到目前为止,我们仅讨论了从ICA获得的线性参数化规范形式及其对各种CNN层的扩展。 如在不同环境下(Singh和Sapatnekar 2006; Cheng,Xiong和He 2009)所建议的,还可以获得其他非线性参数化规范形式。 我们认为,这种扩展也可以用于拟议的SCNN。 为简单起见,我们将不在本文中进一步讨论它,而是将其作为我们未来的工作。
Video Object Detection: an Application
我们相信SCNN可以成为任何CNN网络的通用而强大的主干,并且它可以处理参数化的统计分布而不是确定性的值。 许多基于CNN的应用程序将从这种表示中受益。 为了证明这一点,我们将SCNN应用于视频对象检测任务以显示其有用性。 请注意,与TensorFlow,Caffe,PyTorch等现有框架中的那些成熟实现相比,我们最初的SCNN实现(即FC,CN,ReLU,Max-pooling和Batch规范化等统计版本)远非完美。 。 因此,我们当前用于解决视频对象检测的SCNN实现尚未进行优化。 因此,本文的目的不是要与最新的视频对象检测技术(如Faster R-CNN,YOLOv2)在训练性能或推理质量上竞争。
我们首先用提议的SCNN替换了一些用于对象检测的常用骨干CNN网络,包括VGG11,VGG16,ResNet18和ResNet34。 然后,我们添加一个简单的评估模块,该模块由conv-relu-convrelu-conv层组成,而无需填充。 由于SCNN可以同时有效地处理多个帧,因此在设计检测层和目标函数时需要进行一些更改。
为简单起见,我们从视频中只有一个目标对象的情况开始,并基于YOLOv2框架设计一个简化的检测层(Redmon和Farhadi 2017)。 在YOLOv2的检测层中,在每个子网格单元(总共13×13)处预测预定义的锚框及其置信度,以检测对象。 但是,这种方法不能直接应用于处理具有由单个规范模型捕获的连续移动对象的视频片段。 因此,我们提出了一个新的检测层,该层在地图的中心具有五个预定义的锚点![]() (有效地将地图视为单个大单元格)。 网络会预测盒子的坐标
(有效地将地图视为单个大单元格)。 网络会预测盒子的坐标![]()
![]() 及其置信度。 这些预测依次定义了预测的边界框,如下所示:
及其置信度。 这些预测依次定义了预测的边界框,如下所示:
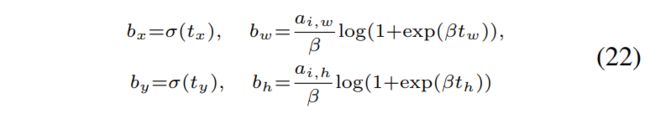
其中σ表示S型函数,β表示Softplus。 请注意,我们使用Softplus函数配置宽度bw和高度bh,而不是配置YOLOv2中使用的直接指数。 这种治疗方法可以使锚点尺寸更稳定,更平滑地转换,并且非常适合我们的一个大单元格设置。
由于SCNN同时处理多个帧,因此检测目标函数不仅应考虑单个帧的精度,还应考虑相邻帧之间对象的连续性。 因此,我们为SCNN提出了一个新的目标函数,它是坐标l2损失(Lcoord),置信度损失(Lconf),多项式拟合损失(Lfit)和IOU损失(LIOU)的组合。
IOU损失首先在UnitBox中引入(Yu等人,2016年),它通过将预测框作为一个整体回归来提高准确性。 但是,Unitbox中使用的自然对数曲线具有陡峭的斜率,当IOU变高并且需要微调时,该斜率会变弱。 此外,如果我们仅在目标函数中使用IOU损失,则当预测框超出目标区域时,它将保持恒定。 这将无助于提高培训的收敛性。 直观地讲,我们希望IOU损失可以补偿坐标损失,以进一步增加IOU。 因此,在这项工作中,我们建议使用IOU的负对数S型函数。 此外,与将IOU包括在置信度分数中的YOLOv2不同,我们使用置信度损失Lconf来检测是否存在对象。
为了进一步提高精度,我们观察到在提取跨度的帧内,对象边界框坐标的轨迹可以通过多项式曲线近似。 用等式22预测坐标后,我们采用最小二乘多项式拟合来获得校正后的坐标以及拟合损失Lfit。 然后,将损失作为惩罚项附加到目标函数。
总而言之,给定初始边界框预测z =![]() ,在拟合校正
,在拟合校正![]() 及其对应的地面真理
及其对应的地面真理![]() 之后,z和
之后,z和![]() 之间的IOU标记为
之间的IOU标记为![]() , 目标函数L(z,z〜)表示为:
, 目标函数L(z,z〜)表示为:
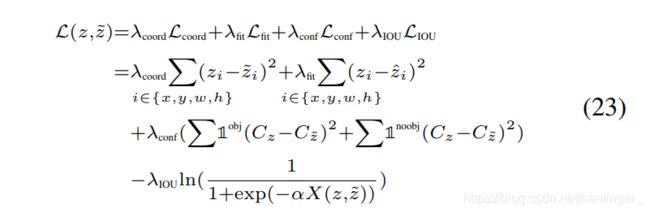
下标x,y,w,h分别代表中心坐标,边界框的宽度和高度; λ是损耗项的系数; C是客观置信度得分; LIOU中的α用于调整IOU损耗曲线。
Experiment Implementation Details
我们选择PyTorch作为我们实现所有模型的评估平台。 实验在Intel Xeon E5-2620 v4、256G内存和NVIDIA GeForce GTX 1080 GPU的16个内核上运行。 数据集(Xu et al.2018c)是DAC 2018系统设计竞赛中最新的视频对象检测数据集。 数据集极具挑战性,因为视频是通过空中捕捉的无人机捕获的,并且所捕获的对象很小,在对象类别,外观,环境和视频质量方面千差万别。
为了获得准确性,我们使用平均平均精度(mAP)来计算大于0.5的预测和实地边界框之间的IOU之比。 请注意,这样的度量标准实际上对SCNN不利,因为SCNN能够一次处理和评估多个图像帧(视频片段),而传统的对象检测一次只能处理一个静态图像,而静态图像具有 固有的精度优势。 尽管如此,我们的比较将显示SCNN可以实现很大的加速。
总体而言,SCNN视频对象检测框架遵循图2。输入图像大小为224×224,并获得7×7的时间特征图以进行评估。 随机梯度下降(SGD)求解器以初始学习率为0.001应用于SCNN训练。 动量和权重衰减始终分别设置为0.9和0.0005。
然后,我们在带有和不带有SCNN主干的情况下实现VGG(Simonyan和Zisserman 2014)和ResNet,以进行准确性和速度比较。 VGG以其简单的顺序网络而闻名,该网络仅使用3×3堆叠的卷积层进行特征提取。 ResNet的特征在于其网络中网络结构,可形成有效的极深网络。 为了使用SCNN实施,根据先前的讨论重新设计了这些网络中用于特征提取的所有层。 对于VGG和ResNet中的分类器,原始的完全连接层已替换为前面讨论的评估器。 评估模块中的内核数量根据相应网络的输出进行更新。 使用相同的优化程序设置从头开始培训所有网络。
Results

表1显示了具有不同基本尺寸m和相同提取范围(N = 16)的具有SCNN主干的网络的视频对象检测精度和速度,以及没有SCNN主干的对应对象。从表中可以看到,具有SCNN骨干的网络可以实现较高的推理速度,而精度会略有下降。例如,当m = 8时,与没有SCNN主干的VGG16相比,其mAP下降了4.8%,可实现178%的加速。这充分证明了SCNN的效率。 同样,具有较大的基本维度,具有SCNN主干的网络倾向于以较低的推理速度为代价实现更高的准确性。
为了进一步说明SCNN的性能,我们以VGG16为例,比较数据集中多个类别中有无SCNN主干的VGG16的mAP。 结果示于表2。
尽管SCNN作为具有较高FPS的CNN可以达到合理的精度,但从表1中我们可以看到SCNN的mAP比CNN低。 通过查看表2中的详细信息,我们发现SCNN实际上优于在诸如汽车和骑行之类的框架中相对平滑的对象类别的CNN。 这是因为SCNN可以通过ICA对时间相关性进行隐式建模,从而减轻对象遮挡和镜头眩光的影响。 相反,对于太大或太小的建筑物,滑翔伞或马术等物体,如图1所示,由于ICA引起的误差开始产生负面影响。 而不是使用ICA获得的线性参数化形式,未来改进的方向将是使用可以更明确地建模大规模空间相关性的非线性参数化分布。 另一个可能的方向是探索SCNN特定的网络架构,而不是than带现有的CNN架构。
Conclusion and Discussion
在本文中,我们提出了一种新颖的统计卷积神经网络(SCNN),该算法可对参数化规范模型中的分布进行运算。 通过视频对象检测示例,我们表明SCNN作为对任何现有CNN的扩展都可以有效地处理多个相关图像,与现有方法相比,可以大大提高速度。
通过不仅利用视频片段中的相邻帧之间,而且利用同一帧的通道之间的相关性,可以进一步提高SCNN的性能。 这将提供进一步的加速。 但是,由于输入维度现在不同,因此这种更改可能需要重新设计CNN网络拓扑,这是值得探索的未来研究方向。 有趣的是,如何将SCNN应用于其他应用程序,例如不确定性感知的图像分类或分割。
论文完(感谢谷歌翻译)
论文地址