【读点论文】ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,规则分组,有序混洗
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Abstract
- 本文介绍了一种称为ShuffleNet的计算效率极高的CNN架构,它是专门为计算能力非常有限(例如10-150 MFLOPs)的移动设备设计的。新架构利用两种新操作,逐点组卷积和信道混洗,在保持精度的同时大大降低了计算成本。
- 在ImageNet分类和MS COCO对象检测上的实验证明了ShuffleNet优于其他结构的性能,例如在40 MFLOPs的计算预算下,在ImageNet分类任务上比最近的MobileNetV1更低的top-1误差(绝对7.8%)。在基于ARM的移动设备上,ShuffleNet比AlexNet实现了13倍的实际加速,同时保持了相当的精度。
- ShuffleNet是旷视科技提出的一种计算高效的CNN模型,其和MobileNet和SqueezeNet等一样主要是想应用在移动端。所以,ShuffleNet的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。
- ShuffleNet的核心是采用了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。目前移动端CNN模型主要设计思路主要是两个方面:模型结构设计和模型压缩。
- ShuffleNet 是 Face++团队提出的,与 MobileNet 一样,发表于 CVPR-2017。https://arxiv.org/pdf/1707.01083.pdf
Introduction
- 构建更深更大的卷积神经网络(CNN)是解决主要视觉识别任务的主要趋势[AlexNet,VGG,ResNet,FCN,Faster-RCNN,Rich feature hierarchies for accurate object detection and semantic segmentation]。最精确的CNN通常有数百层和数千个通道,因此需要数十亿次浮点运算。
- 这份报告研究了相反的极端:在数十或数百MFLOPs的非常有限的计算预算中追求最佳精度,专注于常见的移动平台,如无人机、机器人和智能手机。请注意,许多现有的作品[Speeding up convolutional neural networks with low rank expansions,Speeding-up convolutional neural networks using fine-tuned cp-decomposition,Accelerating very deep convolutional networks for classification and detection,Efficient and accurate approximations of nonlinear convolutional networks,Learning structured sparsity in deep neural networks,Xnornet]集中于修剪、压缩或低秩表示“基本”网络架构。
- 在这里,本文的目标是探索一个高效的基础架构,专为本文期望的计算范围而设计,从头开始设计小的网络。
- 本文注意到,由于高成本的密集1 × 1卷积,Xception 和ResNeXt 等最先进的基本架构在极小的网络中变得效率较低。本文建议使用逐点组卷积来降低1 × 1卷积的计算复杂度。为了克服组卷积带来的副作用(通道之间的交流较少),本文提出了一种新颖的通道混洗操作来帮助信息在特征通道之间流动。
- 基于这两种技术,本文构建了一个高效的架构ShuffleNet。与[VGG,ResNet,ResNeXt]等流行的结构相比,对于给定的计算复杂度预算,本文的ShuffleNet允许更多的特征映射通道,这有助于编码更多的信息,并且对非常小的网络的性能尤其重要。
- shuffleNet在具有挑战性的ImageNet分类和MS COCO对象检测任务上评估本文的模型。一系列的控制实验表明了本文的设计原则的有效性和优于其他结构的性能。与最先进的架构MobileNet V1相比,ShuffleNet实现了显著的卓越性能,例如,在40 MFLOPs的水平上,ImageNet top-1误差绝对低7.8%。
- 本文还研究了实际硬件上的加速,即一个现成的基于ARM的计算核心。ShuffleNet模型比AlexNet 实现了13倍的实际加速比(理论加速比是18倍),同时保持了相当的精度。
Related Work
Efficient Model Designs
- 最近几年,深度神经网络在计算机视觉任务中取得了成功,其中模型设计发挥了重要作用。在嵌入式设备上运行高质量深度神经网络的日益增长的需求鼓励了对高效模型设计的研究[Convolutional neural networks at constrained time cost]。
- 与简单叠加卷积层相比,GoogLeNet 以低得多的复杂性增加了网络的深度。SqueezeNet 在保持精度的同时显著减少了参数和计算。ResNet 利用高效的瓶颈结构来实现令人印象深刻的性能。SENet 引入了一种架构单元,它以很小的计算成本提高了性能。
- 与本文工作开展同时,最近的一项工作[Learning transferable architectures for scalable image recognition]采用强化学习和模型搜索来探索有效的模型设计。提出的mobile NASNet模型实现了与本文的对应ShuffleNet模型相当的性能(26.0% @ 564 MFLOPs对26.3% @ 524 MFLOPs的ImageNet分类错误)。但是[NASnet]没有报告在极其微小的模型上的结果(例如,复杂度小于150 MFLOPs),也没有评估在移动设备上的实际推断时间。
- ShuffleNet的核心设计理念是对不同的channels进行shuffle来解决group convolution带来的弊端。Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积(组内卷积),这样会降低卷积的计算量。
- 因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。使用group convolution的网络如Xception,MobileNet,ResNeXt等。
Group Convolution
- 组卷积的概念最初是在AlexNet 中引入的,用于在两个GPU上分布模型,在ResNeXt 中已经很好地证明了它的有效性。Xception中提出的深度方向可分离卷积概括了Inception系列中可分离卷积的思想。最近,MobileNetV1利用深度方向可分离卷积,并在轻量模型中获得了最先进的结果。本文的工作以一种新的形式推广了组卷积和深度可分卷积。
Channel Shuffle Operation
- 据本文所知,在之前关于高效模型设计的工作中很少提到信道混洗操作的思想,尽管CNN库cuda-convnet支持“随机稀疏卷积”层,这相当于随机信道混洗后跟一个组卷积层。这种“random shuffle”操作具有不同的目的,后来很少被利用。最近,另一项并行工作[Interleaved group convolutions for deep neural networks]也采用了这一思想进行两级卷积。但[Interleaved group convolutions for deep neural networks]并没有专门考察通道混洗本身的有效性及其在微小模型设计中的使用。
Model Acceleration
-
这一方向旨在加速推理,同时保持预训练模型的准确性。修剪网络连接[Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,Learning both weights and connections for efficient neural network]或信道[Learning structured sparsity in deep neural networks]减少了预训练模型中的冗余连接,同时保持了性能。
-
文献中提出了量化和因式分解来减少计算中的冗余以加速推断。在不修改参数的情况下,通过FFT (普遍运用于多项式乘法和卷积运算)和其他方法[Lcnn: Lookup-based convolutional neural network]实现的优化卷积算法在实践中减少了时间消耗。提炼[Distilling the knowledge in a neural network]将知识从大模型转移到小模型,这使得训练小模型更容易。
- 通过量化(quantization)、裁剪(pruning)和压缩(compression)来降低模型的尺寸;通过高效的计算平台加速推理(inference)的效率,例如Nvidia TensorRT、GEMMLOWP、Intel MKL-DNN等以及硬件定制。
- 模型量化(model quantization)是通用的深度学习优化的手段之一,它通过将float32格式的数据转变为int8格式,一方面降低内存和存储的开销,同时在一定的条件下(8-bit低精度运算 low-precision)也能提升预测的效率。更少的存储开销和带宽需求。即使用更少的比特数存储数据,有效减少应用对存储资源的依赖。
- 更低的功耗。移动 8bit 数据与移动 32bit 浮点型数据相比,前者比后者高 4 倍的效率,而在一定程度上内存的使用量与功耗是成正比的。
- 更快的计算速度。相对于浮点数,大多数处理器都支持 8bit 数据的更快处理,如果是二值量化,则更有优势。
- 模型量化适用于绝大数模型和使用场景,对于训练后的量化,不需要重新训练模型,可以很快将其量化为定点模型,而且几乎不会有精度损失,因此模型量化追求更小的模型和更快的推理速度。
- pytorch中的量化:量化是指用于执行计算和以低于浮点精度的位宽存储张量的技术。量化模型以降低的精度而不是全精度(浮点)值对张量执行部分或全部运算。这允许更紧凑的模型表示,并在许多硬件平台上使用高性能矢量化操作。与典型的FP32型号相比,PyTorch支持INT8量化,允许将模型尺寸减小4倍,将内存带宽要求降低4倍。与 FP32 计算相比,对 INT8 计算的硬件支持通常快 2 到 4 倍。量化主要是一种加速推理的技术,量化运算符仅支持正向传递。量化 — PyTorch 主文档
-
FFT的一点记录
-
复数:z=a+bi,其中 a , b ∈ R , i = − 1 a,b\in\R,i=\sqrt{-1} a,b∈R,i=−1
-
加 法 法 则 : ( a + b i ) + ( c + d i ) = ( a + c ) + ( b + d ) i 乘 法 法 则 : ( a + b i ) ( c + d i ) = ( a c − b d ) + ( a d + b c ) i 除 法 法 则 : a + b i c + d i = a c + b d c 2 + d 2 + b c − a d c 2 + d 2 i 欧 拉 定 理 : e i θ = c o s θ + i s i n θ 复 数 可 以 写 作 为 : z = r e i θ , 其 中 r 为 它 的 模 , θ 为 它 的 幅 角 加法法则:(a+bi)+(c+di)=(a+c)+(b+d)i\\ 乘法法则:(a+bi)(c+di)=(ac-bd)+(ad+bc)i\\ 除法法则:\frac{a+bi}{c+di}=\frac{ac+bd}{c^2+d^2}+\frac{bc-ad}{c^2+d^2}i\\ 欧拉定理:e^{i\theta}=cos\theta+isin\theta\\ 复数可以写作为:z=re^{i\theta},其中r为它的模,\theta为它的幅角 加法法则:(a+bi)+(c+di)=(a+c)+(b+d)i乘法法则:(a+bi)(c+di)=(ac−bd)+(ad+bc)i除法法则:c+dia+bi=c2+d2ac+bd+c2+d2bc−adi欧拉定理:eiθ=cosθ+isinθ复数可以写作为:z=reiθ,其中r为它的模,θ为它的幅角
-

-
单位根-三个引理
- 消去引理 : w d n d k = w n k w_{dn}^{dk}=w_n^k wdndk=wnk,如 w n n 2 = w 2 = − 1 w_n^\frac{n}{2}=w_2=-1 wn2n=w2=−1.
- 折半引理: ( w n k + n 2 ) 2 = ( w n k ) 2 = w n 2 k (w_n^{k+\frac{n}{2}})^2=(w_n^k)^2=w^k_\frac{n}{2} (wnk+2n)2=(wnk)2=w2nk。
- 求和引理: ∑ i = 0 n − 1 ( w n k ) i = 0 \sum_{i=0}^{n-1}(w_n^k)^i=0 ∑i=0n−1(wnk)i=0。
-
Approach
Channel Shuffle for Group Convolutions
- 现代卷积神经网络通常由结构相同的重复构建块组成。其中,诸如Xception和ResNeXt 之类的最新网络将有效的深度可分离卷积或组卷积引入到构建块中,以在表示能力和计算成本之间取得良好的平衡。
- 然而,本文注意到两种设计都没有完全考虑1 × 1卷积(在[MobileNetV1]中也称为逐点卷积),这需要相当大的复杂性。例如,在ResNeXt 中,只有3 × 3层配有组卷积。因此,对于ResNeXt中的每个残差单元,逐点卷积占用了93.4%的乘法-加法(基数= 32)。在微型网络中,昂贵的逐点卷积导致有限数量的信道来满足复杂性约束,这可能会显著损害准确性。
- 为了解决这个问题,一个简单的解决方案是在1 × 1层上应用通道稀疏连接,例如组卷积。通过确保每个卷积仅在相应的输入通道组上操作,组卷积显著降低了计算成本。然而,如果多个组卷积堆叠在一起,会有一个副作用:某个通道的输出仅来自一小部分输入通道。下图 (a)示出了两个堆叠的组卷积层的情况。很明显,某个组的输出只与该组内的输入相关。这种特性阻碍了频道组之间的信息流,削弱了代表性。

- 具有两个堆叠组卷积的信道混洗。GConv代表组卷积。
- a)具有相同组数的两个堆叠卷积层。每个输出通道仅与组内的输入通道相关。没有cross talk;
- b)当GConv2从GConv1之后的不同组中取数据时,输入和输出通道是完全相关的;
- c)使用信道混洗的b)的等效实现。
- shuffle 具体来说是 channel shuffle,是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 是用 point-wise convolution 解决的这个问题)
- 利用channel shuffle就可以充分发挥group convolution的优点,而避免其缺点。
- 如果允许组卷积从不同组获得输入数据(如上图 (b)所示),则输入和输出通道将完全相关。具体来说,对于从前一个组层生成的特征图,可以先将每个组中的通道分成若干个子组,然后用不同的子组来馈给下一层的每个组。这可以通过信道混洗操作高效而优雅地实现(上图 ©):假设一个具有g个组的卷积层,其输出具有g × n个信道;首先将输出信道维度整形为(g,n ),转置,然后将其展平,作为下一层的输入。
- 请注意,即使两个卷积的组数不同,该操作仍然有效。此外,信道混洗也是可区分的,这意味着它可以嵌入到网络结构中进行端到端的训练。
- 信道混洗操作使得利用多组卷积层构建更强大的结构成为可能。本文将介绍一种具有信道混洗和组卷积的高效网络单元。
ShuffleNet Unit
- 利用信道混洗操作,本文提出了一种专门为小型网络设计的新型混洗网络单元。从图下(a)中瓶颈单元[ResNet]的设计原理开始。它是一个残差块。在其残差分支中,对于3 × 3层,本文在瓶颈特征图上应用计算经济的3 × 3深度方向卷积[Xception]。
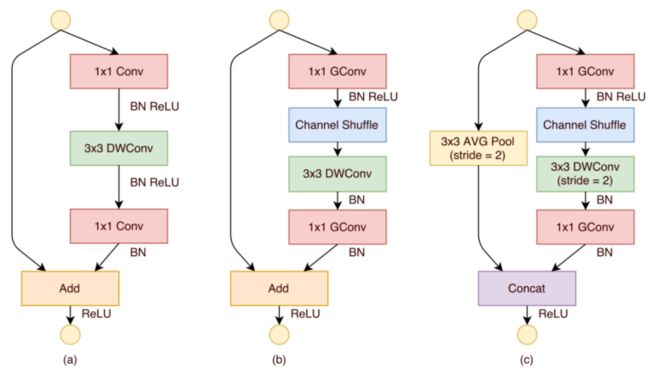
- ShuffleNet Units。
- a)具有深度方向卷积(DWConv) [Xception,MobilenetV1]的瓶颈单元[Resnet];
- b)具有逐点组卷积(GConv)和信道混洗的混洗网络单元;
- c)步幅= 2的ShuffleNet Units。
- 对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。
- 对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat) ,而不是相加。这样做的目的主要是降低计算量与参数大小。
- 然后,本文用逐点组卷积替换第一个1 × 1层,然后进行通道Shuffle操作,形成一个ShuffleNet Units,如上图 (b)所示。第二个逐点组卷积的目的是恢复通道尺寸以匹配残差路径。为了简单起见,本文在第二个逐点层之后不应用额外的通道混洗操作,因为它会导致可比较的分数。
- 批量归一化(BN)和非线性的用法与类似,只是本文没有像[Xceptiob]建议的那样在深度方向卷积后使用ReLU。至于ShuffleNet应用stride的情况,简单做两个修改(见上图 ©):
- (i)在残差路径上增加一个3 × 3的平均池;
- (ii)用信道级联代替逐元素相加,这使得很容易用很少的额外计算成本来扩大信道维度。
- 由于逐点组卷积与信道混洗,混洗单元中的所有分量都可以被有效地计算。与ResNet(瓶颈设计)和ResNeXt 相比,本文的结构在相同的设置下具有更小的复杂度。例如,给定输入大小c × h × w和瓶颈通道m,ResNet单元需要 h w ( 2 c m + 9 m 2 ) hw(2cm + 9m^2) hw(2cm+9m2)触发器,ResNeXt具有 h w ( 2 c m + 9 m 2 / g ) hw(2cm + 9m^2/g) hw(2cm+9m2/g)触发器,而本文的ShuffleNet单元只需要 h w ( 2 c m / g + 9 m ) hw(2cm/g + 9m) hw(2cm/g+9m)触发器,其中g表示卷积的组数。
- 换句话说,给定计算预算,ShuffleNet可以使用更广泛的特征图。本文发现这对小型网络至关重要,因为小型网络通常没有足够数量的通道来处理信息。
- 此外,在ShuffleNet中,深度方向卷积仅在瓶颈特征图上执行。尽管深度方向卷积通常具有非常低的理论复杂度,但本文发现它很难在低功率移动设备上有效地实现,这可能是由于与其他密集操作相比更差的计算/存储器访问比率。在[Xception]中也提到了这样的缺点,它有一个基于TensorFlow的运行时库[Tensorflow: Large-scale machine learning on heterogeneous distributed systems]。在ShuffleNet单元中,本文有意只在瓶颈上使用深度方向卷积,以尽可能避免开销。
Network Architecture
- 基于ShuffleNet单元,本文在下表中展示了ShuffleNet的整体架构。所提出的网络主要由分成三级的一堆洗牌网络单元组成。每个阶段中的第一个构建块以步幅= 2应用。一个阶段内的其他超参数保持不变,下一阶段的输出通道加倍。

- ShuffleNet architecture:复杂度用FLOPs来评估,即浮点乘加的数量。请注意,对于阶段2,本文没有在第一个逐点层上应用组卷积,因为输入通道的数量相对较少。
- 与[ResNet]类似,本文将每个ShuffleNet单元的瓶颈通道数量设置为输出通道的1/4。本文的目的是提供一个尽可能简单的参考设计,尽管本文发现进一步的超参数调整可能会产生更好的结果。
- 在ShuffleNet单元中,组号g控制逐点卷积的连接稀疏性。上表探讨了不同的组数,本文调整了输出通道,以确保总计算成本大致不变(140 MFLOPs)。显然,对于给定的复杂度限制,较大的组号导致更多的输出信道(因此更多的卷积滤波器),这有助于编码更多的信息,尽管它也可能由于有限的相应输入信道而导致单个卷积滤波器的降级。
- 为了将网络定制到期望的复杂度,可以简单地对信道数量应用比例因子s。例如,本文将上表中的网络表示为“ShuffleNet 1×”,那么“ShuffleNet s×”意味着将ShuffleNet 1×中的滤波器数量缩放s倍,因此总复杂度大约是ShuffleNet 1×的 s 2 s^2 s2倍。
Experiments
- 本文主要在ImageNet 2012分类数据集上评估本文的模型。本文遵循[ResNeXt]中使用的大多数训练设置和超参数,但有两个例外:
- (I)本文将权重衰减设置为4e-5而不是1e-4,并使用线性衰减学习率策略(从0.5降低到0);
- (ii)对于数据预处理,本文使用稍微不太激进的规模扩大。[MobileNetV1]中也提到了类似的修改,因为这种小网络通常会出现欠拟合而不是过拟合。在4个GPU上训练一个模型进行 3 × 1 0 5 3×10^5 3×105次迭代需要1、2天的时间,批量设置为1024。为了进行基准测试,本文在ImageNet验证集上比较了单裁剪top-1的性能,即从256×输入图像中裁剪224×224的中心视图并评估分类精度。本文对所有型号使用完全相同的设置,以确保公平的比较。
Ablation Study
- ShuffleNet的核心思想在于逐点组卷积和通道混洗操作。在这一小节中,本文分别对它们进行评估。
Pointwise Group Convolutions
- 为了评估逐点组卷积的重要性,本文比较了具有相同复杂度的ShuffleNet模型,这些模型的群数量从1到8不等。如果组号等于1,则不涉及逐点组卷积,然后ShuffleNet单元变成“Xception-like”[Xception]结构。为了更好地理解,本文还将网络的宽度扩展到3种不同的复杂度,并分别比较它们的分类性能。结果如下表所示。

- 分类误差与组数g的关系(组数越小,性能越好)
- 从结果中,本文看到具有组卷积(g > 1)的模型始终比没有逐点组卷积(g = 1)的模型表现得更好。较小的模型往往从群体中获益更多。例如,对于ShuffleNet 1倍的最佳条目(g = 8)比对应条目好1.2%,而对于ShuffleNet 0.5倍和0.25倍,差距分别变为3.5%和4.4%。
- 请注意,对于给定的复杂度限制,组卷积允许更多的特征映射通道,因此本文假设性能增益来自更宽的特征映射,这有助于编码更多的信息。此外,较小的网络涉及较薄的特征图,这意味着它从放大的特征图中获益更多。
- 上表还显示,对于一些模型(例如ShuffleNet 0.5×)来说,当组数变得相对较大(例如g = 8)时,分类分数饱和甚至下降。随着组数量的增加(因此特征映射更宽),每个卷积滤波器的输入通道变得更少,这可能损害表示能力。有趣的是,本文还注意到,对于更小的模型,如ShuffleNet 0.25×更大的组数往往会始终获得更好的结果,这表明更宽的特征图为更小的模型带来更多好处。
Channel Shuffle vs. No Shuffle
- 混洗操作的目的是为多个组卷积层启用跨组信息流。下表比较了具有/不具有信道混洗的混洗网络结构(例如组号被设置为3或8)的性能。评估是在三种不同的复杂程度下进行的。

- ShuffleNet with/without channel shuffle (smaller number represents better performance)
- 很明显,通道混洗持续提升不同设置的分类分数。特别地,当组数相对较大(例如g = 8)时,具有信道混洗的模型明显优于对应的模型,这显示了跨组信息交换的重要性。
Comparison with Other Structure Units
- 最近,VGG 、ResNet、GoogleNet 、ResNeXt 和Xception 的改进的卷积单元采用大型模型(例如≥ 1GFLOPs)追求最先进的结果,但没有充分探索低复杂性条件。在本节中,本文将考察各种构建模块,并在相同的复杂性约束下与ShuffleNet进行比较。
- 为了公平比较,本文使用表ShuffleNet architecture所示的整体网络架构。本文用其他结构替换阶段2-4中的shuffle网络单元,然后调整通道的数量以确保复杂度保持不变。本文探索的结构包括:
- VGG-like:遵循VGG网的设计原则,本文使用两层3×3卷积作为基本构造块。与[VGG]不同的是,本文在每个卷积后添加了一个批量归一化层,以使端到端的训练更容易。
- ResNet。本文在实验中采用了“瓶颈”设计,这在[Resnet]中已被证明更有效。与[Resnet]相同,bottleneck ratio也是1 : 4。
- Xception-like:[Xception]中提出的原始结构涉及不同阶段的花哨复杂设计或超参数,本文发现难以在小模型上进行公平比较。相反,本文从ShuffleNet(也等同于g = 1的ShuffleNet)中移除了逐点组卷积和信道混洗操作。导出的结构与[Xception]中的“深度方向可分离卷积”的思想相同,这里称为Xception-like结构。
- ResNeXt。本文使用[ResNeXt]中建议的基数= 16和bottleneck ratio= 1 : 2的设置。本文还探索了其他设置,例如bottleneck ratio= 1 : 4,并得到类似的结果。
- 本文使用完全相同的设置来训练这些模型。结果如下表所示。在不同的复杂程度下,本文的ShuffleNet模型比大多数其他模型表现出色。

- 分类误差与各种结构的关系(%,数字越小表示性能越好)。本文没有在较小的网络上报道类似VGG的结构,因为准确性明显更差。
- 有趣的是,本文发现了特征映射通道和分类精度之间的经验关系。例如,在38 MFLOPs的复杂度下,类VGG、ResNet、ResNeXt、Xception-like、ShuffleNet模型的阶段4(见表ShuffleNet architecture)的输出通道分别为50、192、192、288、576,这与精度的增加是一致的。由于ShuffleNet的高效设计,对于给定的计算预算,本文可以使用更多的通道,因此通常会产生更好的性能。
- 请注意,上述比较不包括GoogleNet或Inception系列。本文发现为小型网络生成这样的初始结构并不容易,因为初始模块的原始设计涉及太多的超参数。作为参考,第一个GoogleNet版本具有31.3%的top-1误差,代价是1.5 GFLOPs(见下表)。更复杂的初始版本[Rethinking the inception architecture for computer vision,Inceptionv4, inception-resnet and the impact of residual connections on learning]更精确,然而,包括显著增加的复杂性。最近,Kim等人提出了一个名为PVANET 的轻量级网络结构,它采用了初始单元。本文重新实现的PVANET(输入大小为224×224)的分类误差为29.7%,计算复杂度为557 MFLOPs,而本文的ShuffleNet 2x模型(g = 3)的分类误差为26.3%,计算复杂度为524 MFLOPs。

- Complexity comparison. *Implemented by BVLC (https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet)
- bottleneck ratio:在bottleneck-like的单元(如ResNet、ResNeXt或ShuffleNet)中,bottleneck-like意味着瓶颈通道与输出通道的比率。例如,瓶颈比率= 1 : 4意味着输出特征图的宽度是瓶颈特征图的4倍。
Comparison with MobileNets and Other Frameworks
- Howard等人提出了MobileNets ,主要关注移动设备的高效网络架构。MobileNet采用了[Xception]中深度方向可分离卷积的思想,并在小模型上实现了最先进的结果。
- 下表比较了不同复杂程度下的分类分数。很明显,本文的ShuffleNet模型在所有复杂性方面都优于MobileNet。虽然本文的ShuffleNet网络是专门为小模型(< 150 MFLOPs)设计的,但本文发现它在较高的计算成本方面仍优于MobileNet,例如,在500 MFLOPs的成本下,比MobileNet 1×高3.1%。对于较小的网络(40 MFLOPs),ShuffleNet比MobileNet快7.8%。
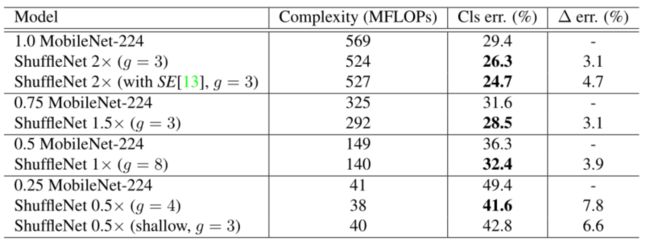
- ShuffleNet vs. MobileNet on ImageNet Classification
- 请注意,本文的ShuffleNet架构包含50层,而MobileNet只有28层。为了更好地理解,本文还通过在阶段2-4中移除一半的块,在26层架构上尝试ShuffleNet(参见上表中的“ShuffleNet 0.5× shallow (g = 3)”。结果表明,浅层模型仍然明显优于相应的MobileNet,这意味着ShuffleNet的有效性主要源于其有效的结构,而不是深度。
- Complexity comparison表比较了本文的ShuffleNet和一些流行的模型。结果表明,在相同的精度下,ShuffleNet比其他方法更有效。比如ShuffleNet 0.5×理论上比分类分数相当的AlexNet 快18倍。将在后文评估实际运行时间。
- 同样值得注意的是,简单的架构设计使得为ShuffeNets配备最新的技术变得容易,例如[Squeeze-and-excitation networks,Swish: a self-gated activation function]。例如,在[SENet]中,作者提出了在大型ImageNet模型上实现最先进结果的挤压和激发(se)模块。
- 本文发现SE模块在与主干shuffle网结合时也有效,例如,将洗牌网的top-1误差提高了2倍至24.7%(如上表所示)。有趣的是,尽管理论复杂度的增加可以忽略不计,但*本文发现具有se模块的ShuffleNets通常比移动设备上的“原始”ShuffleNets慢25 - 40 %,这意味着实际的加速评估对于低成本架构设计至关重要。在后文将作进一步的讨论。
Generalization Ability
- 为了评估迁移学习的推广能力,本文在MS COCO对象检测任务上测试了ShuffleNet模型。本文采用Faster-RCNN 作为检测框架,并使用公开发布的Caffe代码进行默认设置的训练。与[MobileNetV1]类似,在排除5000个minival图像的COCO train+val数据集上训练模型,并且本文在minival集上进行测试。
- 下表显示了在两种输入分辨率下训练和评估的结果的比较。将ShuffleNet 2X与复杂度相当的MobileNet(524对569 MFLOPs)进行比较,本文的ShuffleNet 2X在两种分辨率上都远远超过MobileNet;本文的ShuffleNet 1×在600×分辨率上也取得了与MobileNet相当的结果,但复杂度降低了4倍。本文推测这种显著的收益部分是由于ShuffleNet的简单的架构设计,没有花里胡哨的东西。

- MS COCO上的对象检测结果(数字越大表示性能越好)。对于MobileNets,本文比较两个结果:
- 1)由[MobileNet]报告的COCO检测分数;
- 2)从重新实现的MobileNets进行微调,其训练和微调设置与ShuffleNets完全相同。
Actual Speedup Evaluation
- 最后,本文在装有ARM平台的移动设备上评估了ShuffleNet模型的实际推理速度。尽管具有较大组数(例如g = 4或g = 8)的shuffleNet通常具有较好的性能,但本文发现在当前的实现中效率较低。
- 根据经验,g = 3通常在准确性和实际推断时间之间有一个适当的折衷。如下表所示,测试采用了三种输入分辨率。由于内存访问和其他开销,本文发现在本文的实现中,每4倍的理论复杂度降低通常会导致2.6倍的实际加速。

- 移动设备上的实际推理时间(数字越小,性能越好)。该平台基于单个高通骁龙820处理器。所有结果都用单线程评估。
- 尽管如此,与AlexNet相比,本文的ShuffleNet 0.5倍模型仍然在相当的分类精度下实现了13倍的实际加速比(理论加速比是18倍),这比以前的AlexNet级模型或加速方法(如[SqueezeNet,Speeding up convolutional neural networks with low rank expansions,Speeding-up convolutional neural networks using fine-tuned cp-decomposition,Accelerating very deep convolutional networks for classification and detection,Efficient and accurate approximations of nonlinear convolutional networks,Learning structured sparsity in deep neural networks])快得多。
- ShuffleNet的核心在于使用channel shuffle操作弥补分组间的信息交流,使得网络可以尽情使用pointwise分组卷积,不仅可以减少主要的网络计算量,也可以增加卷积的维度,从实验来看,是个很不错的work。
onal networks,Learning structured sparsity in deep neural networks])快得多。
- ShuffleNet的核心在于使用channel shuffle操作弥补分组间的信息交流,使得网络可以尽情使用pointwise分组卷积,不仅可以减少主要的网络计算量,也可以增加卷积的维度,从实验来看,是个很不错的work。