论文阅读 - SATAR: A Self-supervised Approach to Twitter Account(CIKM 2021)
SATAR: A Self-supervised Approach to Twitter Account Representation Learning and its Application in Bot Detection
推特账户表示学习的自监督方法及其在机器人检测中的应用
论文链接:https://arxiv.org/pdf/2106.13089.pdf
目录
摘要
1 绪论
2 相关工作
2.1 Twitter Bot Detection
2.2 Self-Supervised Learning
3 问题定义
4 SATAR 方法
4.1 Overview
4.2 Tweet-Semantic Sub-Network
4.3 Profile-Property Sub-Network
4.4 Following-Follower Sub-Network
4.5 Co-Influence Aggregator
4.6 Self-Supervised Learning and Optimization
5 实验
5.1 Experiment Settings
5.2 Bot Detection Performance
5.3 SATAR Generalization Study
5.4 SATAR Adaptation Study
5.5 Representation Learning Study
5.6 Case Study
6 结论和未来工作
摘要
自 2006 年推出以来,Twitter 已成为主要的社交媒体平台,而最近对机器人帐户的投诉也有所增加。尽管已经进行了广泛的研究工作,但最先进的机器人检测方法缺乏普遍性和适应性。
具体来说,以前的机器人检测器仅利用一小部分用户信息,并且通常在仅涵盖少数类型机器人的数据集上进行训练。因此,它们无法推广到 Twittersphere 上不同类型的机器人共存的真实场景。此外,Twitter 中的机器人不断发展以逃避检测。
以前的努力,虽然在他们的环境中曾经有效,但无法适应新一代的 Twitter 机器人。
为了解决 Twitter 机器人检测的两个挑战,我们提出了 SATAR,一种 Twitter 用户的自我监督表示学习框架,并将其应用于机器人检测任务。
特别是,SATAR 通过联合利用特定用户的语义、属性和邻域信息进行泛化。同时,SATAR 通过对大量自我监督用户进行预训练和对详细的机器人检测场景进行微调来适应。大量实验表明,SATAR 在不同信息完整性和收集时间的不同机器人检测数据集上优于竞争基线。 SATAR 也被证明可以在现实世界场景中泛化并适应不断发展的社交媒体机器人。
1 绪论
推特是一个流行的在线社交媒体平台,于2006年被重新发布。个人可以注册一个Twitter账户,查看和发布他们感兴趣的内容。根据Statista的报告,到2020年第二季度,美国每日活跃的Twitter用户数量将超过3500万。推特不仅成为人们日常生活中必不可少的社交平台,也成为信息发布场所。推特的开放性和广泛普及性使其成为自动程序(也称为机器人)的理想利用目标。这些机器人账户的运作往往是为了达到恶意的目的。机器人积极参与了许多重要事件,包括美国和欧洲的选举。机器人还负责传播假新闻和传播极端意识形态。这些恶意的机器人试图通过模仿正常用户的行为来掩盖其自动化的本质。据报道,在整个Twitter领域,机器人占总活跃用户的9%到15%。由于机器人危害了用户在Twitter中的体验,甚至可能诱发不良的社会影响,许多研究工作都致力于Twitter机器人的检测。
第一个检测社交媒体中自动账户的工作可以追溯到2010年。
早期的研究进行了特征工程并采用了传统的分类算法。考虑了三类特征:(1)用户属性特征;(2)来自推文的特征;以及(3)从邻居信息中提取的特征。
后来,研究人员开始提出基于神经网络的机器人检测框架。Wei等人采用长短期记忆从推文中提取语义信息。Kudugunta等人提出了一种结合特征工程和神经网络模型的方法。启发式的机器人检测方法最近也被提出来。Minnich等人提出了一种基于异常检测的机器人检测方法。Cresci等人将推文编码为一个字符串,以找出人类和机器人在推文行为上的差异。
尽管早期取得了成功,但不断变化的社交媒体给机器人检测的任务带来了两个新的挑战:概括和适应。
社交媒体机器人检测中的泛化挑战要求机器人检测器同时识别以多种不同方式攻击的机器人,并利用Twitter上的多样化特征。Cresci等人指出,Twitter机器人以不同的方式进行攻击,如转发欺诈、恶意标签推广和URL垃圾邮件。他们还模仿不同类型的真实用户的推特行为,以不同的方式填写个人资料项目,并相互关注以提高他们的粉丝数量。由于Twitter机器人确实变得更加多样化,因此一个强大的Twitter机器人检测器应该解决泛化的挑战,以诱发现实世界的影响。然而,以前的机器人检测方法未能普及,因为它们只利用了有限的用户信息,并且是在只有少数类型的机器人的数据集上训练的。
除此之外,机器人检测适应性的挑战要求机器人检测器在不同时间保持理想的性能并赶上快速的机器人进化。克雷斯奇等人的调查表明,过去的机器人程序简单易识别,拥有的个人资料和朋友信息太少而无法成为真实的机器人。然而,最近进化的机器人拥有大量的朋友和追随者,使用偷来的个人资料图片,并将恶意的推文与中性的推文相混淆。这些新进化的机器人经常躲避现有的检测措施,因此一个强大的机器人检测器应该解决适应性的挑战,以结束机器人进化和机器人检测研究之间的军备竞赛。然而,以前的机器人检测措施在很大程度上依赖于特征工程,并不是为了适应机器人进化的新趋势而设计的。
鉴于 Twitter 机器人检测的两个挑战,我们提出了一个新颖的框架 SATAR(Twitter 帐户表示学习的自我监督方法)。 SATAR 采用自我监督学习来获取用户表示并识别社交媒体上的机器人。具体来说,SATAR 在没有特征工程的情况下联合编码用户的推文、属性和邻域信息,以促进机器人检测泛化。 SATAR 遵循预训练和微调学习模式,以适应不同代的机器人。我们的主要贡献总结如下:
我们提出了一个新颖的框架 SATAR 来进行可推广和适应性强的 Twitter 机器人检测。 SATAR 是一个端到端的框架,它在没有特征工程的情况下联合使用用户的语义、属性和邻域信息;
据我们所知,本文是第一个引入自我监督表示学习以提高机器人检测性能的工作;
我们对三个真实世界的数据集进行了广泛的实验,以评估 SATAR 和竞争基线。 SATAR 在所有三个数据集上的表现都优于基线,并被证明可以通过进一步探索进行泛化和适应。
在下文中,我们首先在第二节中回顾了相关的工作,并在第三节中定义了Twitter机器人检测的任务。接下来,我们在第四节中提出了SATAR,并在第五节中进行了大量的实验。最后,我们在第6节中总结了整篇论文。
2 相关工作
在本节中,我们简要回顾了自我监督学习和Twitter机器人检测的相关文献。
2.1 Twitter Bot Detection
传统的机器人检测方法主要集中在从用户信息中提取基本特征。其中,高等人使用文本闪动和增量聚类将垃圾邮件合并到活动中以进行实时分类。李等人建议在推文中使用 URL 重定向。Thomas 等人专注于提到的网站的分类。还采用了其他功能,例如用户个人资料 [25]、社交网络 [31] 和帐户时间表 [4] 的信息。杨等人设计了几个新功能来对抗现代 Twitter 机器人的演变。克雷斯奇等人提出机器人检测器和机器人操作员之间的对抗是一场永无止境的军备竞赛。还有人认为,我们应该避免使用依赖后验观察的方法。
神经网络由于其强大的学习能力,也被用于检测Twitter机器人。Wei等人采用递归神经网络来有效地捕捉整个推文的特征。Kudugunta等人将用户特征分为账户级特征,如粉丝数,以及推特级特征,如标签数量。这两种特征和语义信息被用来建立一个基于LSTM的机器人检测框架。Stanton等人利用生成式对抗网络进行垃圾邮件检测,以避免注释成本和不准确的情况。Alhosseini等人提出了一个基于图卷积网络的垃圾邮件检测模型,以利用节点特征和邻居的信息。然而,这些监督方法在很大程度上依赖于注释的数据,而相关的数据集通常规模有限。我们从自我监督学习中吸取了大量的无标记数据。
2.2 Self-Supervised Learning
为了以有监督的方式使用无监督的数据集,自我监督学习构建了一个特殊的学习任务,利用其余的实体信息预测一个子集。作为一种有前途的学习范式,自监督学习因其出色的数据效率和泛化能力而引起了大量关注,许多最先进的模型都采用这种范式。Doersch等人将几个自我监督的任务结合起来,共同训练一个网络。Zhai等人提出,半监督学习可以从自我监督学习中获益。
自监督学习已被用于不同领域,如自然语言处理、计算机视觉和图分析。在自然语言处理中,自我监督的任务是根据接下来的词或整个句子来设计的。为了更好地关注一般的内容,也采用了屏蔽语言模型。在计算机视觉中,相邻的像素和完整的图像同样被用于预案任务。在图分析中,自监督任务是基于边缘属性或节点属性设计的。
3 问题定义
假设是一个 Twitter 用户,由用户信息U的三个方面组成:语义T、属性P和邻域N。
令![]() 为用户推文M的语义信息。每条推文
为用户推文M的语义信息。每条推文![]() 包含
包含![]() 个单词。令
个单词。令![]() 为用户的属性信息,共有R属性。每个属性
为用户的属性信息,共有R属性。每个属性 可以是数字的,例如关注者数量,也可以是分类的,例如用户是否经过验证;
可以是数字的,例如关注者数量,也可以是分类的,例如用户是否经过验证;
令![]() ,其中
,其中![]() 是用户u的关注,
是用户u的关注,![]() 是关注者。与之前的研究类似,我们将 Twitter 机器人检测视为二元分类问题,其中每个用户可以是人类 (y=0) 或机器人 (y=1)。形式上,我们可以将 Twitter bot 检测任务定义如下:
是关注者。与之前的研究类似,我们将 Twitter 机器人检测视为二元分类问题,其中每个用户可以是人类 (y=0) 或机器人 (y=1)。形式上,我们可以将 Twitter bot 检测任务定义如下:
问题:Twitter 机器人检测给定一个 Twitter 用户及其信息T , P和 N,学习机器人检测函数f:![]() ,使得
,使得 逼近groundtruth,以最大化预测精度。
逼近groundtruth,以最大化预测精度。
4 SATAR 方法
在这一节中,我们介绍了所提出的名为SATAR(Twitter账户表征学习的自我监督方法)的Twitter用户表征学习框架的细节。
4.1 Overview
图 1 说明了建议的框架 SATAR。它由四个主要组件组成:(1)推文语义子网络,(2)个人资料属性子网络,(3)追随者/关注子网络和(4)共同影响聚合器。具体来说,我们使用 Twitter API来获取有关用户语义、属性和邻域信息的相关数据。
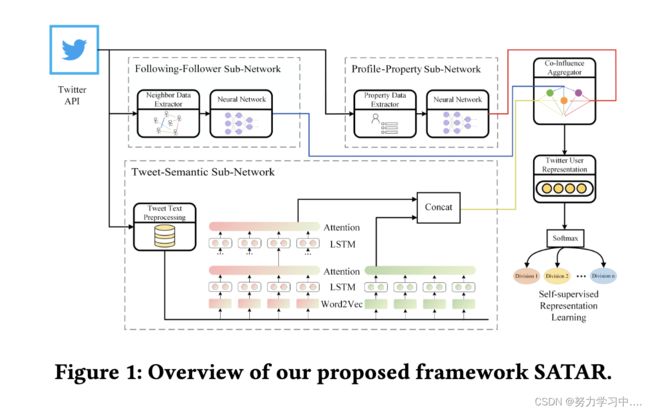
推文语义子网络将 Twitter 用户的文本信息编码为具有不同深度的分层 RNN,并伴随着注意机制;
profile-property 子网络将 Twitter 用户的个人资料属性编码为属性数据编码和完全连接的层;
关注者/关注子网络将 Twitter 用户的邻域关系编码为邻域信息提取器和全连接层;
最后,非线性 Co-Influence 聚合器将上述三个组件之间的相关性考虑在内,生成一个完全体现特定 Twitter 用户社会地位的表示向量;
然后将 softmax 层应用于用户分类并实现模型学习。
4.2 Tweet-Semantic Sub-Network
在本文中,我们利用两个不同级别(推文级别和单词级别)的用户语义信息来捕获用户的推文内容。具体来说,用户推文中的单词可以放入两个层次结构中。
对于第3节中定义的推文级特征,![]() 表示用户时间轴上第j条推文中的第i个词,
表示用户时间轴上第j条推文中的第i个词,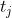 代表一个特定用户的第j条推文;
代表一个特定用户的第j条推文;
我们还将时间上相邻的推文连接起来。![]() ,其中总字数
,其中总字数 。
。
因此,对于单词级别的表征,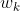 表示将用户推文历史中的第k个单词与时间相邻的推文连接起来形成一个序列。值得注意的是,推文级和词级的底层词是相同的,但它们的注释根据用户的推文行为而有所不同。为了共同利用这两个不同级别的用户推文信息,我们提出了分层 RNN 的推文级和词级编码器,分别对推文文本序列进行建模,并为 Twitter 用户得出整体语义表示。推特用户的整体语义表示与推特级和单词级的结果相连接。
表示将用户推文历史中的第k个单词与时间相邻的推文连接起来形成一个序列。值得注意的是,推文级和词级的底层词是相同的,但它们的注释根据用户的推文行为而有所不同。为了共同利用这两个不同级别的用户推文信息,我们提出了分层 RNN 的推文级和词级编码器,分别对推文文本序列进行建模,并为 Twitter 用户得出整体语义表示。推特用户的整体语义表示与推特级和单词级的结果相连接。 其中,
其中,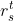 和
和![]() 是推文在推文层面和单词层面的代表。
是推文在推文层面和单词层面的代表。
推文级编码器。推文级编码器遵循自下而上的方法。对于特定用户的第 j-th 条推文,我们首先使用嵌入层得到单词的嵌入表示:

其中是第 j个推文的长度![]() ,我们使用 Word2Vec 作为嵌入层 emb(·)。为了对推文进行编码,双向 RNN 在前向传递和后向传递中处理推文。对于前向传递,为第j条推文生成一系列前向隐藏状态
,我们使用 Word2Vec 作为嵌入层 emb(·)。为了对推文进行编码,双向 RNN 在前向传递和后向传递中处理推文。对于前向传递,为第j条推文生成一系列前向隐藏状态 ,其中每个步骤的隐藏表示由以下方式生成
,其中每个步骤的隐藏表示由以下方式生成 ,在这里,我们使用 LSTM作为 RNN(·),它被广泛用于对序列中的长期依赖关系进行建模。对于后向传播,类似地生成一系列后向隐藏状态:
,在这里,我们使用 LSTM作为 RNN(·),它被广泛用于对序列中的长期依赖关系进行建模。对于后向传播,类似地生成一系列后向隐藏状态: ,我们将前向和后向的结果串联起来,形成第j条推文中的文字表述序列
,我们将前向和后向的结果串联起来,形成第j条推文中的文字表述序列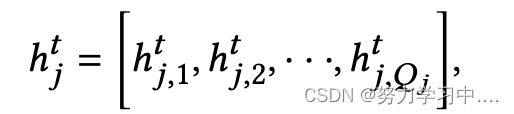
 ,由于推文中的单词对推文整体语义的贡献各不相同,因此采用注意力机制将单词隐藏表示聚合到推文向量中。具体来说
,由于推文中的单词对推文整体语义的贡献各不相同,因此采用注意力机制将单词隐藏表示聚合到推文向量中。具体来说 ,其中
,其中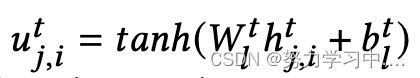 为每个单词转换向量,
为每个单词转换向量,![]() 和
和 ![]() 是可学习的参数,
是可学习的参数,![]() 表示第 - 条推文中第i个词的权重。最后,可以得到第j条推文的表示如下:
表示第 - 条推文中第i个词的权重。最后,可以得到第j条推文的表示如下:
在为每条推文推导出一个向量之后,推文级编码器将 RNN 类似地应用于推文表示![]() ,生成一个前向和后向序列。我们连接前向和后向结果以形成一系列推文表示:
,生成一个前向和后向序列。我们连接前向和后向结果以形成一系列推文表示:
其中![]() 。注意力层被用来模拟每条推文对用户整体语义的影响:
。注意力层被用来模拟每条推文对用户整体语义的影响: ,其中
,其中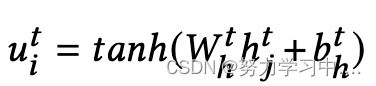 转换每条推文的向量,
转换每条推文的向量,![]() ,
,![]() 和
和![]() 是可学习的参数。
是可学习的参数。![]() 表示第i条推文的权重。最后,从面向推文的角度,可以得到用户推文语义的表示方法如下
表示第i条推文的权重。最后,从面向推文的角度,可以得到用户推文语义的表示方法如下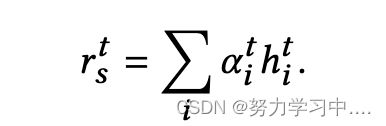 。
。
词级编码器。词级编码器将暂时相邻的推文连接成一个长的词序列。对于序列中的第i个词,我们首先用与推文级编码器相同的嵌入层得到其嵌入。 其中,K是时间上串联的推文中的总字数。采用具有注意力的双向 RNN 对级联序列进行编码。对于前向传递,我们有:
其中,K是时间上串联的推文中的总字数。采用具有注意力的双向 RNN 对级联序列进行编码。对于前向传递,我们有: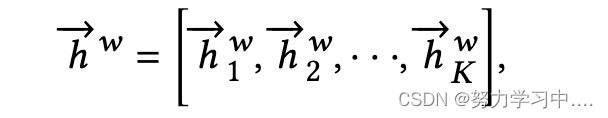 ,其中
,其中 ,LSTM在其特定长度方面采用RNN(-)。对于后向传递,我们有
,LSTM在其特定长度方面采用RNN(-)。对于后向传递,我们有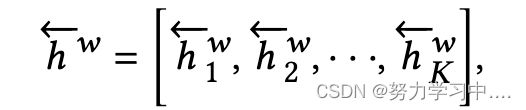 ,
, ,然后,我们将前向和后向的结果串联起来,形成用户推特历史中的单词表示序列
,然后,我们将前向和后向的结果串联起来,形成用户推特历史中的单词表示序列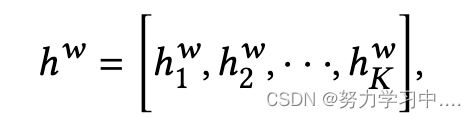
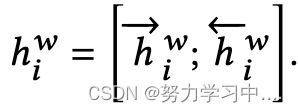 然后应用注意力机制:
然后应用注意力机制: ,
,
![]() ,
, ![]() 和
和![]() 是可学习的参数,
是可学习的参数,![]() 表示连接序列中第i个单词的权重。最后,从面向词的角度来看,用户的推文语义表示如下
表示连接序列中第i个单词的权重。最后,从面向词的角度来看,用户的推文语义表示如下
4.3 Profile-Property Sub-Network
为了避免特征工程中包含的不良偏差,配置文件属性子网络利用可以直接从 Twitter API 检索的配置文件属性。不同类型的属性数据采用不同的编码策略:
· 总共有 15 个真或假属性项。我们用 1 表示真,用 0 表示假。例如“个人资料使用背景图片”;
• 共有5 个数字属性项。我们将 z-分数归一化应用于整个数据集的数值属性。例如“最爱计数”;
• 有一个特殊的属性项:“位置”。我们在地理上将位置划分为不同的国家并应用 one-hot 编码.
值得注意的是,特定用户的关注者数量不会包含在属性向量中,这将是第 4.6 节中介绍的自我监督学习模式的一部分。
将编码的属性项连接起来形成一个原始的属性向量![]() ,然后对其进行转换以生成 Twitter 用户的属性表示
,然后对其进行转换以生成 Twitter 用户的属性表示
其中![]() (·)是全连接层,
(·)是全连接层,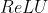 (·)是作为激活函数采用的非线性。
(·)是作为激活函数采用的非线性。
4.4 Following-Follower Sub-Network
对于用户的关注,根据Twitter的机制,他们的推文会出现在时间轴上,关注行为往往表明对他们的推文内容感兴趣。因此,我们建议![]() 对以下关系进行建模:
对以下关系进行建模: ,其中
,其中![]() 表示一组关注的(作者关注的人) Twitter 用户,TF(u)表示用户u的推文频率,
表示一组关注的(作者关注的人) Twitter 用户,TF(u)表示用户u的推文频率, ![]() 是推文语义子网络生成的用户语义表示。
是推文语义子网络生成的用户语义表示。
请注意, 代表用户u出现在一个人的时间线中的比例,因此
代表用户u出现在一个人的时间线中的比例,因此![]() 作为关注者语义信息的加权总和,根据其相对推特频率。
作为关注者语义信息的加权总和,根据其相对推特频率。
对于关注者,由于帐户关注者的平均质量定义了其社会地位,并且质量可以通过其属性进行评估,我们建议将关注者关系建模如下: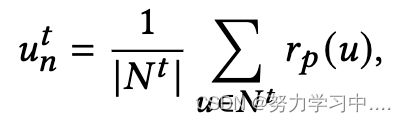 其中,
其中,![]() 表示Twitter用户的关注者集合,
表示Twitter用户的关注者集合,![]() 表示集合的基数,
表示集合的基数,![]() 是由profile-property子网络生成的用户的属性表示。
是由profile-property子网络生成的用户的属性表示。
然后,关注者子网络产生一个原始的隐性向量,以获取邻域信息 。然后转换中间向量以生成 Twitter 用户的邻域表示
。然后转换中间向量以生成 Twitter 用户的邻域表示![]() :
: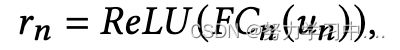
其中![]() (·) 是全连接层, ReLU(·) 是采用的激活函数。
(·) 是全连接层, ReLU(·) 是采用的激活函数。
4.5 Co-Influence Aggregator
到目前为止,我们已经获得了关于Twitter用户的三个方面的表征向量,即 、
、![]() 和
和![]() 关于推文语义、用户属性和关注关系。一个好的机器人检测器应该是全面的,并且对篡改有很强的鲁棒性。换句话说,独立考虑用户形成的每个方面将不可避免地危及机器人检测器的稳健性。Co-attention在处理两个序列之间的相关性方面是一个成功的机制,但它不是为多个表示向量之间的相互影响而设计的。因此,我们提出了一个共同影响聚合器,将推文语义、用户属性和关注关系之间的相互关联性考虑在内。
关于推文语义、用户属性和关注关系。一个好的机器人检测器应该是全面的,并且对篡改有很强的鲁棒性。换句话说,独立考虑用户形成的每个方面将不可避免地危及机器人检测器的稳健性。Co-attention在处理两个序列之间的相关性方面是一个成功的机制,但它不是为多个表示向量之间的相互影响而设计的。因此,我们提出了一个共同影响聚合器,将推文语义、用户属性和关注关系之间的相互关联性考虑在内。
首先,得出一对方面之间的亲和指数。

其中![]() ,
, ![]() 和
和![]() 是聚合器的可学习参数。得出了每个方面的隐藏表示,其中包含来自其他两个方面的相关信息:
是聚合器的可学习参数。得出了每个方面的隐藏表示,其中包含来自其他两个方面的相关信息:
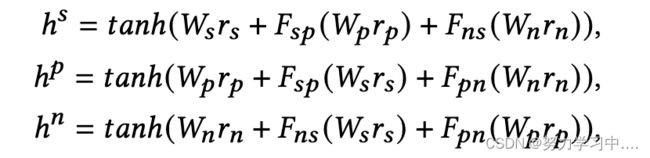
其中,![]() ,
, 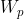 和
和![]() 是聚合器的可学习参数。最后,所提出的框架SATAR产生了如下的Twitter用户表示r:
是聚合器的可学习参数。最后,所提出的框架SATAR产生了如下的Twitter用户表示r:
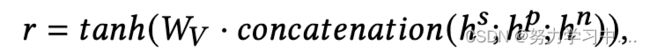
其中,![]() 是聚合器的一个可学习的参数
是聚合器的一个可学习的参数
4.6 Self-Supervised Learning and Optimization
推特用户表征学习试图用分布式表征对特定用户进行建模。我们采用关注者数量作为SATAR训练的自我监督信号。具体来说,一个用户的粉丝数根据其数字尺度和整体粉丝数的分布被分成几个类别。我们训练表征学习框架SATAR,将每个用户归入这些类别,在此过程中获得用户表征。我们相信,由于以下原因,粉丝数量将是一个理想的自我监督训练信号。
利用粉丝数进行自我监督训练是不分任务的。无论是机器人检测、内容推荐还是在线活动建模,粉丝数都与社交媒体上的所有任务有关,而不是专门针对其中任何一项;
粉丝数量最能代表一个Twitter用户。没有更好的选择可以更有效、更准确地描述一个Twitter用户,特别是当粉丝数还涉及到对其他用户的评价时;
关注者数量对大规模的篡改更为有力。虽然有可能购买假粉丝,但根据Cresci等人的调查,增加1000个粉丝往往需要花费13到19美元。因此,显著改变一个用户的粉丝数量的规模是很昂贵的,更不用说发起一个有许多活跃机器人的活动了。
具体来说,假设一个用户可以根据其关注者的数量被归类,一个softmax层被应用于用户表示r: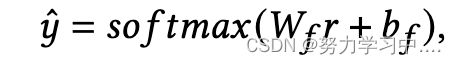
其中,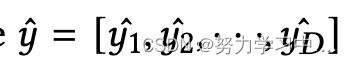 是每个类别的预测概率向量,
是每个类别的预测概率向量,![]() 是可学习的参数。
是可学习的参数。  表示这种分类在one-hot编码中的自我监督的groundtruth。我们最小化交叉熵损失函数如下:
表示这种分类在one-hot编码中的自我监督的groundtruth。我们最小化交叉熵损失函数如下:
其中表示所提出的SATAR框架中的参数。算法1展示了我们所提出的Twitter账户表现学习框架SATAR的整体训练模式。

5 实验
在本节中,我们对三个真实世界的机器人检测数据集进行了广泛的实验和深入分析。
5.1 Experiment Settings
在本节中,我们提供了有关实验中采用的数据集、机器人检测基线和评估指标的信息。数据集。我们使用三个数据集,TwiBot-20、cresci-17 和 PAN-19。由于 Twitter 机器人具有不同的用途并迅速发展,这些高质量的数据集被用来提供全面的评估和验证基线和我们提出的方法的普遍性和适应性。
TwiBot-20是当前Twitter领域的一个综合样本,用于评估机器人检测方法是否能在现实世界的场景中得到推广。TwiBot-20的用户一般可分为四个兴趣领域:政治、商业、娱乐和体育。在用户信息方面,TwiBot-20包含了Twitter用户的语义、属性和邻域信息。
cresci-17是一个公共数据集,包含 4 个组件:真实帐户、社交垃圾邮件机器人、传统垃圾邮件机器人和虚假粉丝。我们合并这四个部分并作为一个整体使用 cresci-17。 cresci-17 包含语义和属性信息。
PAN-19 是CLEF 2019年PAN研讨会上的一个机器人和性别分析共享任务的数据集。它用于机器人和性别剖析,只包含用户语义信息。
这三个数据集的摘要见表3。我们随机对三个数据集进行了7:2:1的分区,作为训练、评估和测试集。这样的分区在第5.2节、第5.3节和第5.4节的所有实验中共享。我们从众多的机器人检测数据集中选择了这三个基准,因为它们的规模较大,收集时间跨度大,而且注释质量高。

基线方法。我们将SATAR与以下机器人检测方法作为基线进行比较。
- Lee等人。Lee等人使用随机森林分类器与几个Twitter用户的特征,如账户的寿命;
- Yang等人。Yang等人使用随机森林与最小账户元数据和12个衍生特征;
- Kudugunta等人。Kudugunta等人提出了一个同时使用推文内容和元数据的架构;
- Wei等人。Wei等人使用词嵌入和三层BiLSTM来编码推文。采用全连接的softmax层进行二元分类。
- Miller等人。Miller等人从用户的推文和属性信息中提取107个特征。机器人用户被认为是不正常的异常值,并采用修改后的流聚类算法来识别Twitter机器人用户。
- Cresci等人。Cresci等人利用字符串来表示用户在线行动的序列。每个行动类型都可以用一个字符进行编码。通过识别具有最长共同子字符串的账户组,可以得到一组机器人账户。
- Botometer。Botometer是一个公开可用的服务,利用一千多个特征对账户进行分类。
- Alhosseini等人。Alhosseini等人利用图卷积网络来检测Twitter机器人。它使用关注信息和用户特征来学习表征并对Twitter用户进行分类。
对于以下基于SATAR的机器人检测方法,自监督的表征学习步骤采用了帕累托原则作为自监督的分类任务,框架学习预测一个Twitter用户的粉丝数是在前20%还是后80%。它是第4.6节中自监督表征学习策略的一个实例。
![]() :所提出的表征学习框架SATAR首先根据用户的关注者数量进行自监督用户分类任务的训练,然后对最后的softmax层进行重新初始化,并对机器人检测任务进行训练;
:所提出的表征学习框架SATAR首先根据用户的关注者数量进行自监督用户分类任务的训练,然后对最后的softmax层进行重新初始化,并对机器人检测任务进行训练;
![]() 。所提出的表征学习框架SATAR首先使用自我监督的用户进行训练,然后重新初始化最后的softmax层,并使用机器人检测的训练集对整个框架进行微调。
。所提出的表征学习框架SATAR首先使用自我监督的用户进行训练,然后重新初始化最后的softmax层,并使用机器人检测的训练集对整个框架进行微调。
评价指标。我们采用准确率、F1分数和MCC作为不同机器人检测方法的评价指标。准确率是分类器正确性的直接指标,而F1得分和MCC是更平衡的评价指标。
5.2 Bot Detection Performance
表1确定了每种比较方法所使用的用户信息。表2报告了不同方法在三个数据集上的机器人检测性能。表2表明。


(机器人检测方法的性能比较。 “/”表示用户信息不足以支持基线)
基于SATAR的方法与其他基线相比取得了有竞争力的表现,这表明SATAR在Twitter机器人检测中是普遍有效的。![]() 优于
优于![]() ,这证明了预训练和微调方法的功效。
,这证明了预训练和微调方法的功效。
![]() 可以推广到现实世界的场景,因为它在模仿现实世界的Twittersphere的全面和有代表性的数据集TwiBot-20上的表现优于最先进的方法。同时,
可以推广到现实世界的场景,因为它在模仿现实世界的Twittersphere的全面和有代表性的数据集TwiBot-20上的表现优于最先进的方法。同时,![]() 能够适应不断变化的机器人的生成,因为它在所有三个数据集上实现了最佳性能,收集时间从2017年到2020年不等。第5.3节和第5.4节将提供进一步的分析,以证明SATAR成功地解决了概括和适应的挑战,而SATAR的关键组件和设计选择是其成功背后的原因。
能够适应不断变化的机器人的生成,因为它在所有三个数据集上实现了最佳性能,收集时间从2017年到2020年不等。第5.3节和第5.4节将提供进一步的分析,以证明SATAR成功地解决了概括和适应的挑战,而SATAR的关键组件和设计选择是其成功背后的原因。
对于主要基于LSTM的方法,我们看到Kudugunta等人优于Wei等人。这表明Kudugunta等人可以通过纳入属性项目来更好地捕捉机器人。![]() 比Kudugunta等人利用了更多的用户信息,并取得了更好的性能,这表明机器人检测方法应该纳入更多的用户信息方面。
比Kudugunta等人利用了更多的用户信息,并取得了更好的性能,这表明机器人检测方法应该纳入更多的用户信息方面。
基于特征工程的方法,如Yang等人,在cresci-17上表现良好,但在TwiBot-20上却逊于![]() 。这表明强调特征工程的传统机器人检测方法不能适应新一代的机器人。
。这表明强调特征工程的传统机器人检测方法不能适应新一代的机器人。
Alhosseini等人和SATAR都使用邻域信息。基于SATAR的方法优于Alhosseini等人,这表明SATAR更好地利用了用户的邻域信息,将Twitter用户放入他们的社会环境中。
5.3 SATAR Generalization Study
在社交媒体机器人检测中,泛化的挑战要求机器人检测器同时识别以多种不同方式攻击,并利用多样化用户信息的机器人。为了证明SATAR的通用性,我们检查了SATAR和竞争基线在TwiBot-20上的表现。如表2所示,SATAR在TwiBot-20上的表现超过了所有基线。鉴于TwiBot-20包含多样化的机器人和人类,模仿了真实世界的Twitter世界,SATAR被证明在真实世界的情况下具有最好的通用性。
为了进一步证明SATAR的通用性,我们在四个用户领域中的一个领域训练SATAR和两个竞争基线,Alhosseini等人和Yang等人,并在其他领域进行测试。结果显示在图2中。这说明SATAR可以更好地捕捉其他类型的机器人,即使没有明确地对它们进行训练,这进一步证实了SATAR成功地概括了在社交媒体上共存的多样化的机器人的说法。

SATAR旨在通过联合利用所有三个方面的用户信息,即语义、属性和邻域信息来实现泛化。为了弄清楚我们提出的使用尽可能多的用户信息是否导致了SATAR的通用性,我们进行了一次删除一个方面的用户信息的消减研究。结果如图3所示。
图3的结果显示,从SATAR中删除任何方面的信息都会导致性能的相当大的损失,限制了SATAR对不同类型的机器人的通用能力。这表明SATAR利用更多方面的信息的策略在其泛化中是至关重要的。

(从 SATAR 中删除语义、属性和邻域子网络的消融研究)
5.4 SATAR Adaptation Study
机器人检测中的适应性挑战要求机器人检测器在不同时期保持理想的性能并赶上机器人的快速进化。为了证明SATAR的适应性,我们检查了SATAR和竞争基线在三个数据集上的表现,因为它们分别在2017年、2019年和2020年发布,可以很好地描述机器人的演变。表2的结果显示SATAR在所有三个数据集上都达到了最先进的性能,这表明SATAR在适应机器人进化方面比现有的基线更成功。
为了进一步证明SATAR的适应能力,我们检查了SATAR在数据集TwiBot-20的验证集和测试集中对用户的预测情况。我们在图4中展示了SATAR对特定用户的预测结果和SATAR在任意3个月的用户注册时间跨度内的准确性。图中显示SATAR对从2007年到2020年创建的用户保持了稳定的检测精度,这也进一步证实了SATAR成功地适应了不断进化的机器人的说法。

(SATAR对TwiBot-20中特定用户的预测。分散的点显示了SATAR对特定用户的预测,线表示SATAR在3个月内注册的机器人的总体准确度。)
SATAR的设计是通过对大量自监督的用户进行预训练和对特定的机器人检测场景进行微调来适应。为了弄清楚这种预训练和微调模式是否使SATAR能够适应新进化的机器人,我们进行了消减研究以移除自我监督的预训练步骤。SATAR在不同数据集上的表现如图5所示。

(消融研究从SATAR中移除自我监督的预训练步骤并在三个数据集上进行训练)
图 5 显示,SATAR 的性能随着采用自我监督的预训练步骤而提高,这种趋势在用户信息较少的数据集 PAN-19 上尤为突出。这表明SATAR的适应能力确实来自于使用追随者数量作为用户代表预训练的自我监督信号的创新策略。
5.5 Representation Learning Study
SATAR改善了Twitter用户的表征学习。内在的评估已经证明了SATAR的表示具有理想的质量。我们通过将SATAR表征与Alhosseini等人和Yang等人的表征进行对比,进一步进行内在评估,这些表征也提供了用户表征。我们使用k=2的k-均值对表征进行聚类,并计算同质性分数,即聚类包含单一类别的程度。较高的同质性分数表明,具有相同标签的用户更有可能彼此接近。
图6可视化了TwiBot-20的一个子图中的用户表示。图6(a)是SATAR表征的t-SNE图,显示了机器人和人类群体的适度搭配,而图6(b)和(c)显示了很少的搭配。从数量上看,SATAR取得了最高的同质性分数,这表明SATAR产生的用户表征质量更高。

(SATAR、Alhosseini等人和Yang等人的用户代表向量的二维t-SNE图。)
5.6 Case Study
为了进一步了解SATAR是如何识别机器人的,我们研究了几个机器人的特殊情况。我们使用方程中: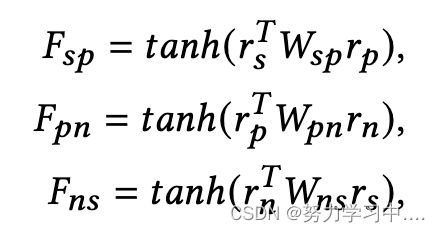 的亲和力指数值来定量分析SATAR的决策。图7显示了被抽样用户的详细信息。
的亲和力指数值来定量分析SATAR的决策。图7显示了被抽样用户的详细信息。

(一个示例机器人集群来解释 SATAR 的决定)
SATAR通过用户B和E重复或类似的推文来识别他们的自动化信号。例如,用户B的亲和力值为![]() =-0.9989,
=-0.9989,![]() =0.0017和
=0.0017和![]() =0.6376。
=0.6376。![]() 和
和![]() 的绝对值明显大于
的绝对值明显大于![]() ,这表明在这种情况下,语义信息是SATAR决定的主导因素。
,这表明在这种情况下,语义信息是SATAR决定的主导因素。
SATAR 通过其属性识别用户 C 和 D。 SATAR 检测到关注次数过多、默认背景图片等异常特征。 用户 D 的 和 的绝对值比 大,这表明属性信息在 SATAR 的判断中至关重要。
SATAR捕捉到用户A有四个机器人作为邻居,这对真正的用户来说是不可能的。用户A的![]() 和
和![]() 的绝对值大于
的绝对值大于![]() ,这也证明了用户A的不正常邻居导致了SATAR的决定。
,这也证明了用户A的不正常邻居导致了SATAR的决定。
图7中的案例研究表明,SATAR通过联合评估他们的语义、属性和邻域信息来识别机器人用户。我们提出的协同影响聚合器的亲和值为SATAR的决定提供了解释。
6 结论和未来工作
社会媒体机器人检测正在吸引越来越多的关注。我们提出了SATAR,一种自我监督的Twitter账户代表学习方法,并将其应用于机器人检测的任务。SATAR的目的是解决在现实世界场景中泛化和适应机器人进化的挑战,而之前的努力是失败的。
我们进行了广泛的实验来证明基于SATAR的机器人检测与竞争基线相比的有效性。进一步的探索证明,SATAR也成功地在真实的Twitter世界中进行了推广,并适应了不同年代的Twitter机器人。在未来,我们计划将SATAR代表学习框架应用于社交媒体领域的其他任务,如假新闻检测和内容推荐。