OpenCV学习指南
OpenCV学习指南
这个OpenCV教程是供初学者入门的基础知识。在本指南中,您将学习使用Python使用OpenCV库进行的基本图像处理操作。虽然本教程针对刚入门图像处理和OpenCV库的初学者,但即使您有经验,我还是鼓励您阅读它。快速复习OpenCV基础知识也将帮助您完成自己的项目。
在系统上安装OpenCV和Imutils
第一步是在系统上安装OpenCV,并设置新的OpenCV开发环境,然后通过pip安装imutils软件包。如果没有安装opencV,ubuntu下可通过下列命令安装:`
使用pip将OpenCV安装到您的Ubuntu系统中
$ sudo pip install opencv-contrib-python
使用pip将OpenCV安装到虚拟环境中
$ pip install virtualenv virtualenvwrapper
在我们继续之前,您首先需要使用nano、vim或emacs打开~/bashrc文件,并将下面的命令行追加到末尾:
vi ~/.bashrc
# virtualenv and virtualenvwrapper
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source /usr/local/bin/virtualenvwrapper.sh
$ source ~/.bashrc
$ mkvirtualenv cv -p python3
$ pip install opencv-contrib-python
在系统上安装Imutils
$ pip install imutils
加载并显示图像

图1:使用Python学习OpenCV基础知识是从加载和显示图像开始的,这是一个仅需要几行代码的简单过程。
首先, 在您喜欢的文本编辑器或IDE中打开 opencv_tutorial_01 .py.
# import the necessary packages
import imutils
import cv2
# load the input image and show its dimensions, keeping in mind that
# images are represented as a multi-dimensional NumPy array with
# shape no. rows (height) x no. columns (width) x no. channels (depth)
image = cv2.imread("jp.png")
(h, w, d) = image.shape
print("width={}, height={}, depth={}".format(w, h, d))
# display the image to our screen -- we will need to click the window
# open by OpenCV and press a key on our keyboard to continue execution
cv2.imshow("Image", image)
cv2.waitKey(0)
运行结果为:
width=600, height=322, depth=3
访问单个像素
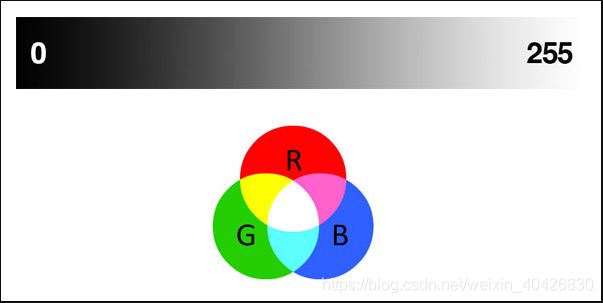
Figure 2: Top: grayscale gradient where brighter pixels are closer to 255 and darker pixels are closer to 0. Bottom: RGB venn diagram where brighter pixels are closer to the center.
什么是像素?
所有图像都由像素组成,这些像素是图像的原始构建块。图像由网格中的像素组成。640 x 480图像具有640列(宽度)和480行(高度)。具有这些尺寸的图像中有 640 * 480 = 307200 像素。
灰度图像中的每个像素都有一个代表灰度的值。在OpenCV中,有256种灰度(从0到255)。因此,灰度图像将具有与每个像素关联的灰度值。
彩色图像中的像素具有其他信息。在学习图像处理时,您很快就会熟悉几种色彩空间。为简单起见,我们仅考虑RGB颜色空间。
在OpenCV中,RGB(红色,绿色,蓝色)颜色空间中的彩色图像具有与每个像素(B ,G ,R ) 相关联的3元组 。
请注意,顺序是BGR而不是RGB。这是因为多年前首次开发OpenCV时,标准是BGR订购。多年来,标准现已成为RGB,但OpenCV仍保持这种“传统” BGR顺序以确保不存在现有代码中断。
在BGR 3元组的每个值的范围为 [ 0 ,255 ] 。OpenCV中RGB图像中的每个像素有多少种颜色可能性?这很容易: 256 * 256 * 256 = 16777216 。
既然我们已经确切知道什么是像素,那么让我们看一下如何检索图像中单个像素的值:
# access the RGB pixel located at x=50, y=100, keepind in mind that
# OpenCV stores images in BGR order rather than RGB
(B, G, R) = image[100, 50]
print("R={}, G={}, B={}".format(R, G, B))
如前所示,我们的图片尺寸为: 宽度= 600 ,高度= 322 ,深度= 3 。我们可以通过指定坐标访问数组中的单个像素值,只要它们在最大宽度和高度之内即可。
image[ 100 ,50 ] ,从位于像素产生BGR值的3元组 X = 50 和 ÿ = 100 (再次,注意,该高度是数行和宽度是数的列 )。如上所述,OpenCV以BGR顺序存储图像(例如,不同于Matplotlib)。看看提取第19行上像素的颜色通道值有多么简单 。
最终的像素值显示在此处的终端上:
R=41, G=49, B=37
数组切片和裁剪
提取“感兴趣区域”(ROI)是图像处理的一项重要技能。
举例来说,您正在识别电影中的人脸。首先,您将运行人脸检测算法以查找正在使用的所有帧中人脸的坐标。然后,您需要提取面部ROI,然后保存或处理它们。将所有包含Ian Malcolm博士的镜框放在侏罗纪公园将是一个不错的人脸识别小型项目。
现在,让我们手动提取ROI。这可以通过数组切片来实现。
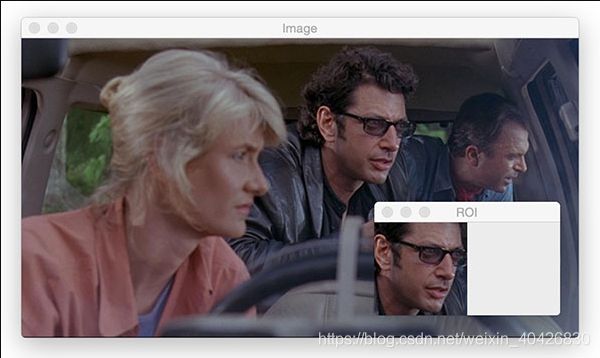
图3:使用OpenCV进行数组切片可让我们轻松提取感兴趣区域(ROI)。
# extract a 100x100 pixel square ROI (Region of Interest) from the
# input image starting at x=320,y=60 at ending at x=420,y=160
roi = image[60:160, 320:420]
cv2.imshow("ROI", roi)
cv2.waitKey(0)
调整图像大小
调整图像大小很重要,原因有很多。首先,您可能需要调整大图像的大小以适合屏幕。在较小的图像上,图像处理也更快,因为要处理的像素更少。在深度学习的情况下,我们经常忽略宽高比来调整图像的大小,以使体积适合网络,这要求图像是正方形且具有一定尺寸。
让我们将原始图像调整为200 x 200像素:
# resize the image to 200x200px, ignoring aspect ratio
resized = cv2.resize(image, (200, 200))
cv2.imshow("Fixed Resizing", resized)
cv2.waitKey(0)
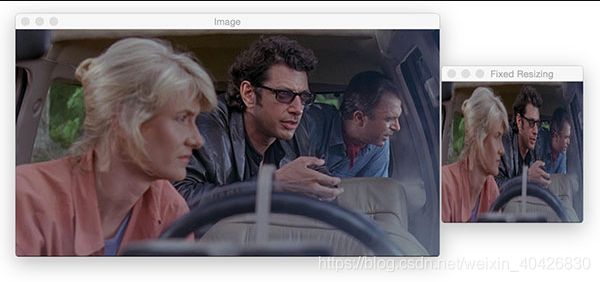
图5:在使用OpenCV保持宽高比的同时调整图像大小的过程分为三个步骤:(1)提取图像尺寸,(2)计算宽高比,(3 cv2.resize)沿一个尺寸调整图像()的大小,再乘以另一个尺寸由长宽比决定。
但是,我们是否可以使调整尺寸时保持宽高比的过程变得更加容易?
是! 每次我们要调整图像大小时,都要计算纵横比有点繁琐,我们可以使用imutils包。
# manually computing the aspect ratio can be a pain so let's use the
# imutils library instead
resized = imutils.resize(image, width=300)
cv2.imshow("Imutils Resize", resized)
cv2.waitKey(0)
在一行代码中,我们保留了宽高比并调整了图像的大小。很简单,您只需要提供目标 宽度 或目标 高度 作为关键字参数即可。
旋转影像
让我们旋转下一个示例的侏罗纪公园图像。
# let's rotate an image 45 degrees clockwise using OpenCV by first
# computing the image center, then constructing the rotation matrix,
# and then finally applying the affine warp
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, -45, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
cv2.imshow("OpenCV Rotation", rotated)
cv2.waitKey(0)
注: 我们使用 / / 于整数运算(即没有浮点值)执行。
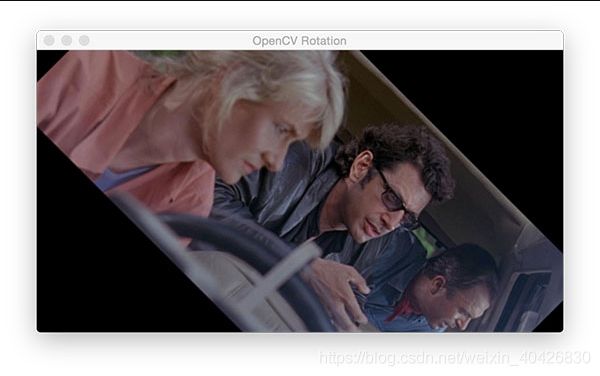
图7:使用OpenCV围绕中心点旋转图像需要三个步骤:(1)使用图像的宽度和高度计算中心点,(2)使用cv2.getRotationMatrix2D来计算旋转矩阵,以及(3)使用cv2.warpAffine旋转矩阵来扭曲图像。
# rotation can also be easily accomplished via imutils with less code
rotated = imutils.rotate(image, -45)
cv2.imshow("Imutils Rotation", rotated)
cv2.waitKey(0)
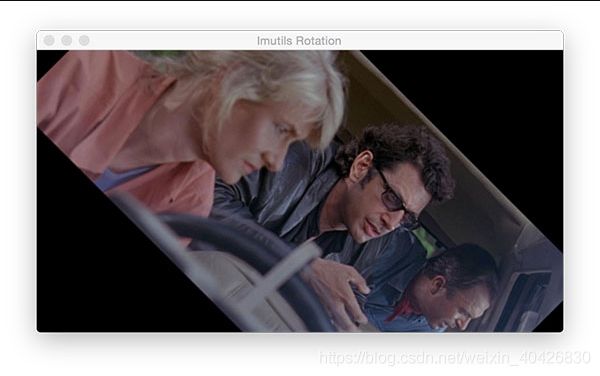
图8:使用imutils.rotate,我们可以通过一行代码方便地使用OpenCV和Python旋转图像。
究竟为什么图像会被剪掉?
问题是,OpenCV并不关心我们的图像在旋转之后是否被剪切并从视图中消失。这很麻烦,所以imutils版本,它将保持整个图像在视图中。称之为rotate_bound:
# OpenCV doesn't "care" if our rotated image is clipped after rotation
# so we can instead use another imutils convenience function to help
# us out
rotated = imutils.rotate_bound(image, 45)
cv2.imshow("Imutils Bound Rotation", rotated)
cv2.waitKey(0)

图9:imutils的rotate_bound功能将防止OpenCV在旋转过程中剪切图像。
完美!整个图像都在框架中,并且已正确地顺时针旋转45度。
平滑图像
在许多图像处理管道中,我们必须对图像进行模糊处理以减少高频噪声,这使我们的算法更容易检测和理解图像的实际内容,而不仅仅是 使“迷惑”我们算法的噪声。在OpenCV中,模糊图像非常容易,并且有多种方法可以完成图像。
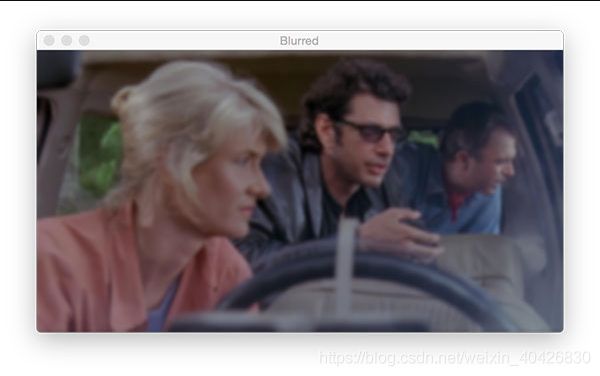
图10:使用OpenCV使用11 x 11内核对该图像进行了高斯模糊处理。模糊是许多图像处理管线减少高频噪声的重要步骤。
我经常使用 GaussianBlur 函数:
# apply a Gaussian blur with a 11x11 kernel to the image to smooth it,
# useful when reducing high frequency noise
blurred = cv2.GaussianBlur(image, (11, 11), 0)
cv2.imshow("Blurred", blurred)
cv2.waitKey(0)
在图像上绘图
在本节中,我们将在输入图像上绘制矩形,圆形和直线。我们还将在图像上覆盖文本。
在继续使用OpenCV在图像上进行绘制之前,请注意,在图像上进行绘制操作是就地执行的。因此,在每个代码块的开头,我们制作原始图像的副本,并将副本存储为 输出 。然后,我们继续 在原位输出图像上进行绘制, 以免破坏原始图像。
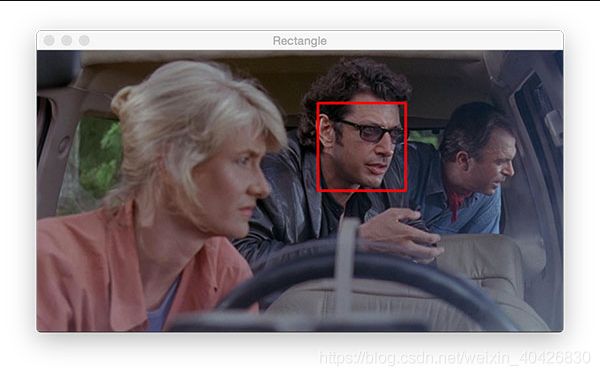
让我们在伊恩·马尔科姆(Ian Malcolm)的脸上绘制一个矩形:
# draw a 2px thick red rectangle surrounding the face
output = image.copy()
cv2.rectangle(output, (320, 60), (420, 160), (0, 0, 255), 2)
cv2.imshow("Rectangle", output)
cv2.waitKey(0)
现在让我们在Ellie Sattler博士的脸前放置一个蓝色实心圆圈:
# draw a blue 20px (filled in) circle on the image centered at
# x=300,y=150
output = image.copy()
cv2.circle(output, (300, 150), 20, (255, 0, 0), -1)
cv2.imshow("Circle", output)
cv2.waitKey(0)
要绘制圆,您需提供以下参数cv2.circle :
- img : 输出图像。
- center : 我们圆的中心坐标。(300 ,150 )
- radius : 圆半径,以像素为单位。 20 像素的值 。
- color : 圆形颜色。此时我与蓝色去如由255在BGR元组的G- + R组分B和0表示,(255, 0, 0), -1)。
- thickness : 线的粗细。
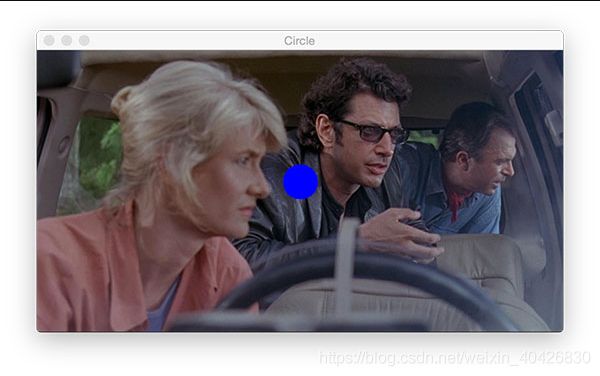
图12: OpenCV的cv2.circle方法允许您在图像上的任何地方绘制圆。为该示例绘制一个实心圆,由-1线宽参数表示(正值将使线宽变化为圆形轮廓)。
接下来,我们将画一条红线。这条线穿过艾莉的头,经过她的眼睛,一直到伊恩的手。
如果仔细查看方法参数并将它们与矩形的参数进行比较,您会发现它们是相同的:
# draw a 5px thick red line from x=60,y=20 to x=400,y=200
output = image.copy()
cv2.line(output, (60, 20), (400, 200), (0, 0, 255), 5)
cv2.imshow("Line", output)
cv2.waitKey(0)
就像在矩形中一样,我们提供两个点,一个颜色和一个线宽。OpenCV的后端完成其余的工作。
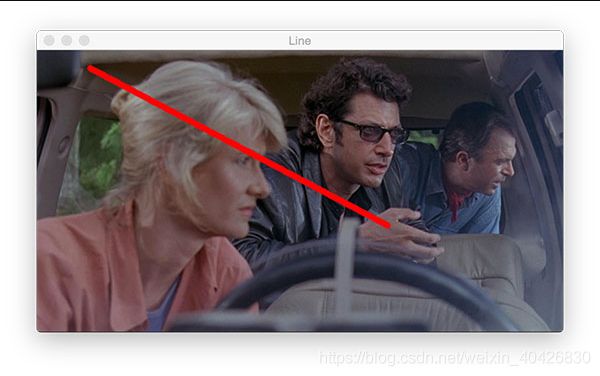
图13:类似于绘制矩形和圆形,在OpenCV中cv2.line仅使用起点,终点,颜色和厚度即可绘制一条线。
通常,您会发现要在图像上覆盖文本以用于显示。如果您正在进行人脸识别,则可能需要在该人的脸上方绘制该人的名字。或者,如果您在计算机视觉事业中取得进步,则可以构建图像分类器或对象检测器。在这些情况下,您会发现要绘制包含类名和概率的文本。
让我们看看OpenCV的putText函数如何工作:
# draw green text on the image
output = image.copy()
cv2.putText(output, "OpenCV + Jurassic Park!!!", (10, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow("Text", output)
cv2.waitKey(0)
OpenCV 的 putText函数负责在图像上绘制文本。让我们看一下所需的参数:
- img :输出图像。
- text :我们要在图像上写/画的文本字符串。
- pt :文本的起点。
- 字体 :我经常使用 cv2.FONT_HERSHEY_SIMPLEX 。可用字体在此处列出。
- scale :字体大小乘数。
- color :文字颜色。
- thickness :笔划的粗细(以像素为单位)。
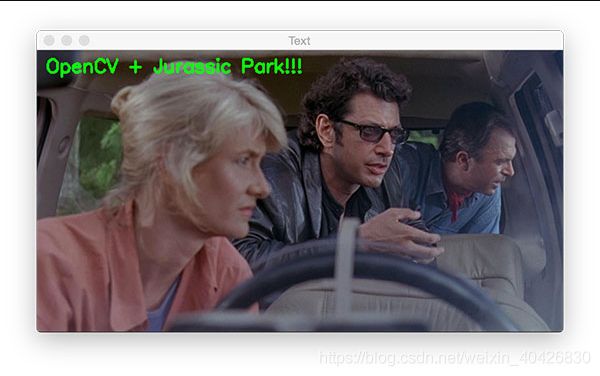
图14:通常,您会发现想要在图像上显示文本以进行可视化。使用cv2.putText上面显示的代码,您可以练习在图像上以不同的颜色,字体,大小和/或位置覆盖文本。
计数对象
在接下来的几节中,我们将学习如何使用创建简单的Python + OpenCV脚本来计算下图中的俄罗斯方块块数:

# import the necessary packages
import argparse
import imutils
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
将图像转换为灰度
# load the input image (whose path was supplied via command line
# argument) and display the image to our screen
image = cv2.imread(args["image"])
cv2.imshow("Image", image)
cv2.waitKey(0)
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Gray", gray)
cv2.waitKey(0)
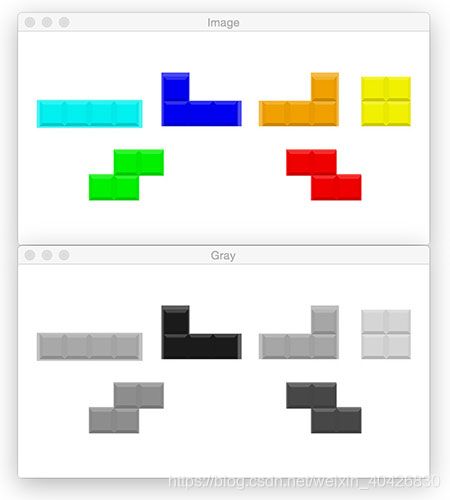
边缘检测
边缘检测可用于查找图像中对象的边界,对于分割目的非常有效。
让我们执行边缘检测以查看该过程如何工作:
# applying edge detection we can find the outlines of objects in
# images
edged = cv2.Canny(gray, 30, 150)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
使用流行的Canny算法(由John F. Canny在1986年开发),我们可以找到图像中的边缘。
我们为cv2.Canny提供的参数:
img : 灰色 图像。
minVal :最小阈值,在我们的示例中为 30 。
maxVal :最大阈值, 在我们的示例中为 150。
aperture_size :Sobel内核大小。默认情况下,此值为 3
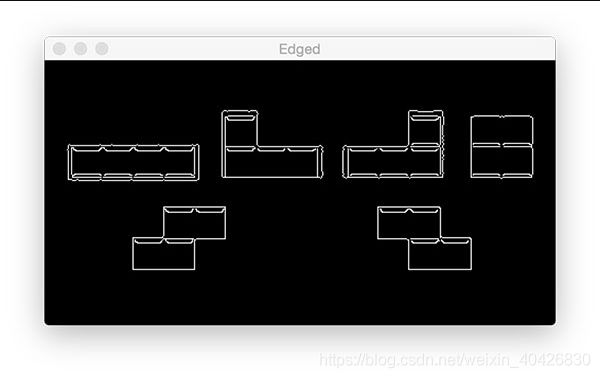
图18:为了使用OpenCV进行边缘检测,我们使用了Canny算法。
阈值
图像阈值化是图像处理管道的重要中间步骤。阈值处理可以帮助我们去除较亮或较暗的图像区域和轮廓。
# threshold the image by setting all pixel values less than 225
# to 255 (white; foreground) and all pixel values >= 225 to 255
# (black; background), thereby segmenting the image
thresh = cv2.threshold(gray, 225, 255, cv2.THRESH_BINARY_INV)[1]
cv2.imshow("Thresh", thresh)
cv2.waitKey(0)
将像素值大于225的灰度图像中的所有像素设置为0(黑色),这对应于图像的背景
将像素值为小于225灰度图像中的所有像素设置255(白色),该值对应于图像的前景(即,俄罗斯方块本身)
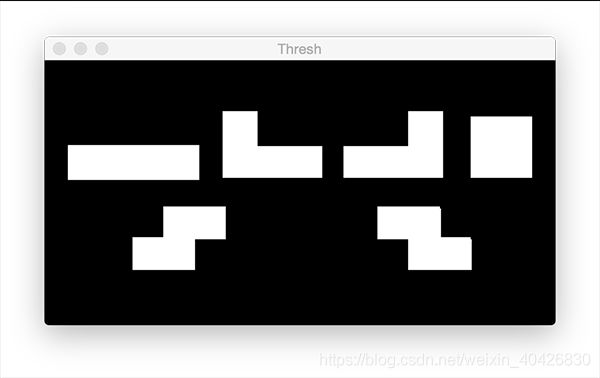
图19:在找到轮廓之前,我们先对灰度图像进行阈值处理。我们执行了二进制反阈值,以使前景形状变为白色,而背景变为黑色。
检测和绘制轮廓
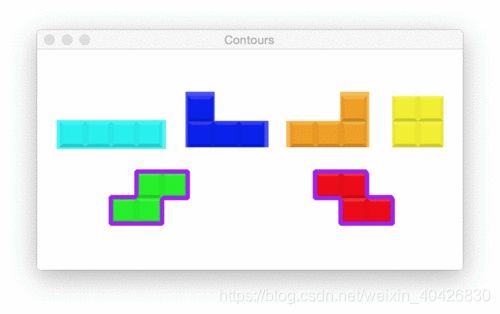
# find contours (i.e., outlines) of the foreground objects in the
# thresholded image
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# loop over the contours
for c in cnts:
# draw each contour on the output image with a 3px thick purple
# outline, then display the output contours one at a time
cv2.drawContours(output, [c], -1, (240, 0, 159), 3)
cv2.imshow("Contours", output)
cv2.waitKey(0)
# draw the total number of contours found in purple
text = "I found {} objects!".format(len(cnts))
cv2.putText(output, text, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(240, 0, 159), 2)
cv2.imshow("Contours", output)
cv2.waitKey(0)
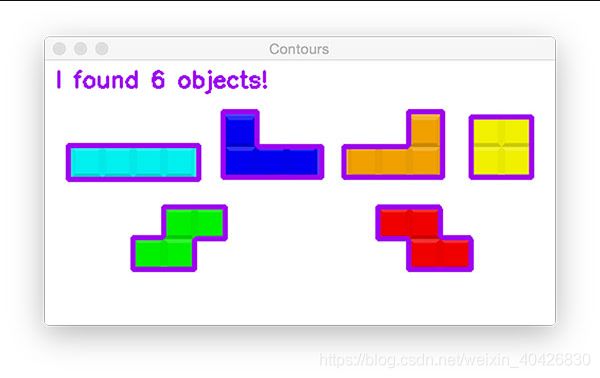
侵蚀和膨胀
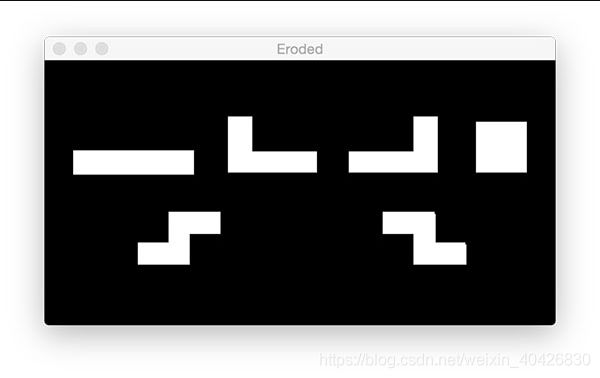
侵蚀和膨胀通常用于减少二进制图像中的噪声(阈值的副作用)。
为了减少前景对象的大小,我们可以通过多次迭代来侵蚀掉像素:
# we apply erosions to reduce the size of foreground objects
mask = thresh.copy()
mask = cv2.erode(mask, None, iterations=5)
cv2.imshow("Eroded", mask)
cv2.waitKey(0)
遮挡和按位运算
遮罩允许我们“遮罩”我们不感兴趣的图像区域。我们称它们为“遮罩”是因为它们将 隐藏我们不关心的图像区域。
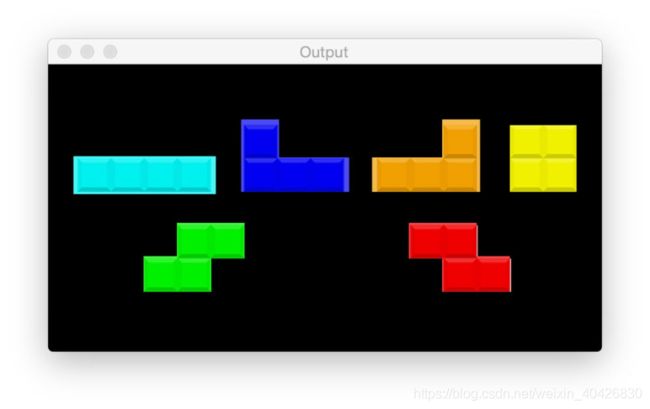
# a typical operation we may want to apply is to take our mask and
# apply a bitwise AND to our input image, keeping only the masked
# regions
mask = thresh.copy()
output = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Output", output)
cv2.waitKey(0)