Multi-modal speech emotion recognition using self-attention mechanism and multi-scale fusion framwor
一、论文基础信息
青岛科技大学信息科学与技术学院的研究者发表在Speech Communication上的《基于自注意机制和多尺度融合框架的多模态语音情感识别》(Multi-modal speech emotion recognition using self-attention mechanism and multi-scale fusion framework)

二、摘要

2.1 Backgroud
Accurately recognizing emotion from speech is a necessary yet challenging task due to the variability in speech and emotion.
由于语音和情感的可变性,准确地从语音中识别情感是一项必要而富有挑战性的任务。
2.2 Methods and experiments
(1)整体结构
A novel method combined self-attention mechanism and multi-scale fusion framework is proposed for multi-modal SER by using speech and text information.
提出了一种结合自注意机制和多尺度融合框架的基于语音和文本信息的多模态SER算法
(2)语音特征
A self-attentional bidirectional contextual LSTM (bc-LSTM) is proposed to learn the context-sensitive dependences from speech. Specifically, the BLSTM layer is applied to learn long-term dependencies and utterance-level contextual information and the multi-head self-attention layer makes the model focus on the features that are most related to the emotions.
提出了一种自注意双向上下文LSTM (bc-LSTM),用于从语音中学习上下文敏感依赖。具体而言,BLSTM层用于学习长期依赖关系和话语级上下文信息,多头自我注意层使模型聚焦于与情绪最相关的特征。
(3)文本特征
A self-attentional multi-channel CNN (MCNN), which takes advantage of static and dynamic channels, is applied for learning general and thematic features from text.
采用自注意多通道CNN (MCNN),利用静态和动态两种通道,从文本中学习一般特征和主题特征。
(4)特征融合
A multi-scale fusion strategy, including feature-level fusion and decision-level fusion, is applied to improve the overall performance.
采用多尺度融合策略,包括特征级融合和决策级融合,以提高整体性能。
2.3 Results
Experimental results on the benchmark dataset IEMOCAP demonstrate that our method gains an absolute improvement of 1.48% and 3.00% over state-of-the-art strategies in terms of weighted accuracy (WA) and unweighted accuracy (UA), respectively.
三、引言
3.1 背景

The crucial part in affective computing is emotion recognition, which aims to analyze the emotion from collected data, such as human speech, speech segments and facial expressions.
情感计算的关键部分是情感识别,它旨在从收集到的数据中分析情绪,如人类的语音、语音片段和面部表情。
Speech is a valuable source of emotional information, contains rich linguistic and paralinguistic information that conveys implicit information such as emotions.
语音是一种有价值的情感信息源,它包含着丰富的语言和副语言信息,传递着情感等隐性信息。
SER technology is widely used in areas such as:
(1)human customer service (Lee and Narayanan, 2005),
(2)distance education (Luo and Tan, 2007)
(3)car driving (Schuller et al., 2004).
因此,语音情感识别(SER)技术被广泛应用于人类客户服务(Lee and Narayanan, 2005)、远程教育(Luo and Tan, 2007)和汽车驾驶(Schuller et al., 2004)等领域。
It is found that humans rely more on multi-modalities than uni-modality to understand emotions (Shimojo and Shams, 2001; Peng et al., 2021; Hossain and Muhammad, 2018). Therefore, we focus on multi-modal SER in this paper.
研究发现,人类更依赖于多模态而非单一模态来理解情绪(Shimojo and Shams, 2001;彭等人,2021年;侯赛因和穆罕默德,2018年)。因此,本文主要研究多模态SER。
3.2 Feature extraction

Feature extraction is a crucial step in multi-modal SER systems, which aims to derive effective feature representations for different emotions.
特征提取是多模态SER系统中的一个关键步骤,其目的是为不同的情绪获取有效的特征表示。
In the aspect of acoustic feature extraction for SER, various extensive feature sets on the basis of low-level descriptors (LLDs) (Demircan and Kahramanli, 2016; Gharavian et al., 2012; Song, 1949) have been developed including:
(1) INTERSPEECH-2010 (Kayaoglu and Erdem, 2015),
(2)GeMAPS (Eyben et al., 2017),
(3)AVEC-2013 (Schuller et al., 2013a),
(4)Com- ParE (Schuller et al., 2013b).
Research shows that the perception of emotion usually depends on the emotional information expressed in a certain period of time. In recent years, the extracted LLDs are converted to utterance-level vectors by utilizing high level statistics functions (HSFs), which describe temporal variations over consecutive frames.
研究表明,情绪的感知通常取决于一定时间内所表达的情绪信息。近年来,利用描述连续帧时间变化的高级统计函数(hsf)将提取的lld转换为词性向量。
However, all these features mentioned above are hand-designed features, which are not effective enough to represent the temporal dynamic characteristics of speech (Wang et al., 2020; Schuller, 2018; Liu et al., 2017).
然而,上述所有这些特征都是手工设计的特征,不足以有效地表示语音的时间动态特征(Wang et al., 2020;舒乐问,2018;Liu等,2017)。
3.3 Solution

To address these shortcomings, researchers rely on sequence models that can capture temporal dynamics, such as:
(1)recurrent neural network (RNN) (Schmidhuber, 2015),
(2)long–short term memory (LSTM) network (Sepp et al., 1997)
(3)Gated recurrent unit (GRU) (Chung et al., 2014).
However, these sequence models can only capture the forward information, while neglecting backward information which reflect the interactions between different words.
然而,这些序列模型只能捕获正向信息,而忽略了反映不同词之间相互作用的后向信息。
To tackle this issue, recently-developed bidirectional LSTM (BLSTM) combines complementary information from the past and future for feature extraction. 为了解决这一问题,最近发展起来的双向LSTM (BLSTM)结合了过去和未来的互补信息进行特征提取。
Meanwhile, modeling context-sensitive dependences remains an active research topic for SER.
同时,对上下文情感依赖进行建模仍然是SER的一个活跃的研究课题。
Poria et al. (2017) proposed a simple contextual LSTM (sc-LSTM) network, which models the relationship between contextual utterances for SER. Therefore, considering both the bidirectional and contextual information could be an appropriate candidate to further improve the performance of SER.
Poria等人(2017)提出了一个简单的上下文LSTM (sc-LSTM)网络,该网络为SER的上下文话语之间的关系建模。因此,同时考虑双向和上下文信息可能是进一步提高SER性能的合适方法。
3.4 Textual features

In the aspect of textual feature extraction for SER, traditional (Xu et al., 2019a) approaches usually utilized affective dictionaries,which contain a collection of labeled affective features , for SER.
在SER的文本特征提取方面,传统的(Xu等人,2019a)方法通常使用包含标记情感特征集合的情感字典进行语义分析。
However, these approaches not only fail to distinguish the degree of importance between common words and keywords in the text, but also ignores the location information of words.
然而,这些方法不仅不能区分常用词和关键词在文本中的重要程度,而且忽略了词语的位置信息。
To address the above mentioned issues, a number of researchers applied convolutional neural network (CNN) to automatically learn word vector representations. For example, Cho et al. (2018) used text to aid speech using the single-channel CNN for SER.
为了解决上述问题,许多研究者应用卷积神经网络(CNN)来自动学习词向量表示。例如,Cho等人(2018)使用文本辅助语音,使用单频道CNN进行SER。
However, single channel CNN only uses the pre-trained word vectors while neglecting the thematic information in specific corpus.
而单通道CNN只使用预先训练好的词向量,忽略了特定语料库中的主题信息。
To address this issue, Hazarika et al. (2018) used a multi-channel network which contains a static channel throughout training and a dynamic channel fine-tuned via backpropagation for emotion classification, achieving significant improvement compared with single-channel CNN.
The multi-channel structure allows the network to learn not only the general features, but also the thematic features relevant to the current corpus. The combination of both features could increase the robustness of the network.
Therefore, textual features extracted by multi-channel is suitable for further improving the performance of SER.
为了解决这个问题,Hazarika等人(2018)使用了一个多通道网络,其中包含一个贯穿训练的静态通道和一个通过反向传播进行优化的动态通道,用于情感分类,与单通道CNN相比,取得了显著的改进。多通道结构使得网络不仅可以学习一般特征,还可以学习与当前语料库相关的主题特征。这两种特性的结合可以提高网络的鲁棒性。因此,多通道提取文本特征适合于进一步提高SER的性能。
3.5 Attention mechanisms

It is noted that all the previously mentioned methods seldom distinguish between emotional and non-emotional frames in the speech, thus bringing interference for SER.
To address this issue, attention mechanisms (Vaswani et al., 2017) have been applied to focus on the emotionally-relevant parts instead of the whole utterance.
Zhao et al. (2018a,b) proposed attention-based BLSTM with fully convolutional networks (FCN) in order to automatically learn the best spatio-temporal representations of speech signals for deep spectrum feature extraction on SER tasks.
需要注意的是,上述所有方法都很少区分言语中的情感和非情感帧,这给SER带来了干扰。为了解决这个问题,注意力机制(Vaswani et al., 2017)被应用于关注与情感相关的部分,而不是整个话语。Zhao等人(2018a,b)提出了基于注意力的BLSTM和全卷积网络(FCN),以自动学习语音信号的最佳时空表示,用于SER任务中的深度频谱特征提取。
However, the information selected by the attention mechanism is the expectation of all input information under the attention distribution, which greatly relies on external information. Recently, Te et al. proposed a framework that combines multi-task 3D CNN and selfattention mechanism to implement SER tasks, where the self-attention mechanism could capture longer temporal dynamics that typical RNNbased models.
而注意机制所选择的信息是注意分布下所有输入信息的期望,对外界信息的依赖性很大。最近,Te等人提出了一个将多任务3D CNN和自注意机制相结合的框架来实现SER任务,其中自注意机制可以捕获典型的基于rnn的模型更长的时间动态。
Self-attention mechanism focuses on the relationships between elements internally, thus reducing the dependence on external information, and capturing relevant information among features. In addition, the self-attention mechanism can be computed in parallel, which greatly improves the computational efficiency. In this paper, we adopt the self-attention mechanism to focus on the salient features.
自我注意机制关注内部元素之间的关系,从而减少对外部信息的依赖,在特征之间捕获相关信息。此外,自注意机制可以并行计算,大大提高了计算效率。在本文中,我们采用自我注意机制来关注显著特征。
3.6 Feature Fusion

We implemented a fusion strategy on the extracted textual and acoustic features to make a decision in classification for SER.
我们对提取的文本特征和声学特征进行融合,以做出SER分类决策。SER的融合方法可以分为两类:特征级融合(Zhao et al., 2018a;Pan等人,2020年)和决策级融合(Su等人,2018年;张等人,2020)。
In feature-level fusion, the features extracted from different models are combined to form a more informative representation vector.
在特征级融合中,将从不同模型中提取的特征组合在一起,形成信息量更大的表示向量。
As for decision level fusion, multiple classifiers need to be trained to jointly analyze the prediction results of each classifier to make dynamic decisions.
对于决策级融合,需要训练多个分类器,联合分析每个分类器的预测结果,做出动态决策。
It has been shown that feature-level fusion and decision-level fusions are equally important and strongly complementary in terms of improving SER classification performance (Farhoudi and Setayeshi, 2020; Yao et al., 2020).
研究表明,在提高SER分类性能方面,特征级融合和决策级融合同样重要,而且具有很强的互补性(Farhoudi和Setayeshi, 2020;姚等人,2020)。
The combination of feature-level and decision-level fusion might be superior to either pure feature-level fusion or decision-level fusion. If all the information is concatenated in feature-level fusion, then it could not take advantages of the abilities of different classifiers to handle emotional states. Similarly, if only decision-level fusion is used, the poor performance of each classifier can be predictable. Therefore, feature-level fusion and decision-level fusion should be combined to obtain better classification results.
特征级和决策级融合的结合可能优于单纯的特征级融合或决策级融合。如果所有的信息都是在特征级融合中连接,那么它就不能利用不同分类器处理情绪状态的能力。同样,如果只使用决策级融合,则可以预测每个分类器的不良性能。因此,为了获得更好的分类结果,需要将特征级融合与决策级融合相结合。
3.6 contributions of this paper

The main contributions of this paper are summarized as follows:
(1) A self-attentional bc-LSTM network is proposed to capture both the utterance-level bidirectional and contextual information from speech.
(2) A self-attentional MCNN is proposed to extract the general features and thematic features for specific corpus from text.
(3) A multi-scale fusion framework, including feature-level fusion by concatenation and decision-level fusion based on Dempster–Shafer (DS) strategy, is proposed to integrate the results of three classifiers for recognizing different emotional states.
(4) Experimental results on the benchmark dataset IEMOCAP demonstrate that our method gains an absolute improvement of 1.48% and 3.00% over state-of-the-art strategies in terms of WA and UA, respectively. The rest of this paper is structured as follows.
本文的主要研究成果如下:
(1)提出了一种自注意bc-LSTM网络,用于从语音中获取话语层面的双向信息和上下文信息。(2)提出了一种自注意MCNN算法,用于从文本中提取特定语料的一般特征和主题特征。
(3)提出了一种多尺度融合框架,包括基于级联的特征级融合和基于Dempster-Shafer (DS)策略的决策级融合,整合了三种分类器识别不同情绪状态的结果。
(4)在基准数据集IEMOCAP上的实验结果表明,我们的方法在WA和UA方面比现有策略分别获得了1.48%和3.00%的绝对改进。
其中**Dempster-Shafer (DS)**是证据理论,关于证据理论可以参考下面两篇博客:
博客1:D-S envidence theory(DS 证据理论)的基本概念和推理过程
博客2:D-S证据理论学习笔记
4 提出的方法

4.1 语音特征提取
基于IS09特征进行提取,我怀疑作者使用的就是IS09特征。

Xi代表一个视频里所有句子对应的特征,Li代表这个视频里的句子数,k代表特征的维度。Xi,t代表第i个视频的第t句话。
2.1.2 Self-attentional bc-LSTM
自注意bc-LSTM子网络的细节包括四个部分:
(1)使用Librosa工具包提取的声学特征作为BLSTM层的输入。
(2)采用BLSTM层进行话语级双向上下文特征提取。
(3)利用注意层发现特征的情感相关部分。
(4)使用全连接层层来获得更高级别的语音表示,以便更好地分类。
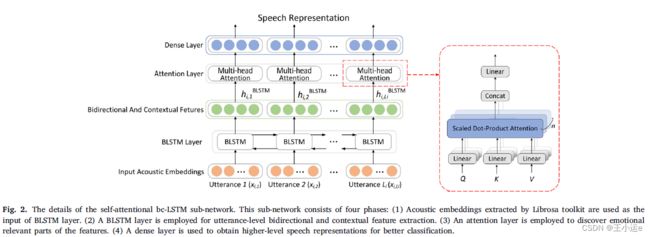
BLSTM层:考虑到语音中情绪变化的复杂性,使用BLSTM层,它使用两个向前和向后方向的LSTM网络,从之前提取的声学特征中学习话语级上下文特征和长期依赖关系。在某一时刻,输入第t条语音,LSTM网络更新如下:
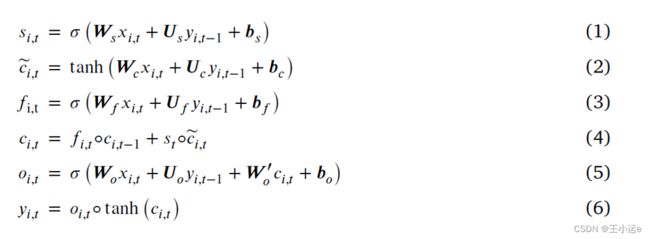
其中、、分别表示输入门、遗忘门和输出门的输出。~表示内存单元的候选值。表示更新后的内存单元状态。是LSTM单元格的输出。和表示权重矩阵。表示偏置。和tanh分别代表sigmoid函数和双曲正切函数。◦代表哈达玛积。
哈达玛积(Hadamard product)是矩阵的一类运算,若A=(aij)和B=(bij)是两个同阶矩阵,若cij=aij×bij,则称矩阵C=(cij)为A和B的哈达玛积,或称基本积。
双向LSTM网络的通过下面的公式进行更新:

LSTM代表公式1-公式6的运算,公式(7)(8)分别代表前向和后向隐藏LSTM单元的输出
使用八头注意力机制:

每个头的尺寸设置为ℎ=∕,其中为BLSTM网络的隐藏单元数
4.2 文本特征提取
4.2.1 Input textual embeddings
We use the transcription of the spoken words as the source of textual modality.
我们使用语音的转录作为文本模态的来源。
We represent each utterance as the concatenation of vectors of constituent words.
我们将每句话表示为构成词的向量的串联。
These vectors are publicly available 300-dimensional word2vec vectors trained from Google News (Mikolov et al., 2013) based on 100 billion words.
这些向量是公开的300维word2vec向量,从谷歌News (Mikolov et al., 2013)训练而来,基于1000亿个单词。
Word vector matrix is used as the input textual embeddings of MCNN.
采用词向量矩阵作为MCNN的输入文本嵌入。
4.2.2. Self-attentional MCNN
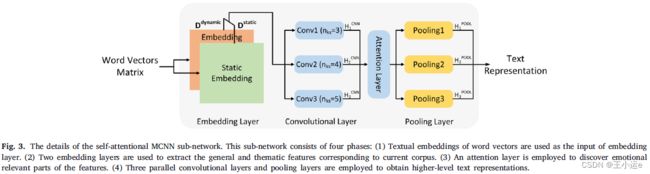
(对于文本特征提取流程图和文本描述部分有点差异,我个人觉得注意力层应该放在卷积层前面)
自注意MCNN子网络包括四个部分:
(1)使用词向量的文本嵌入作为嵌入层的输入。
(2)采用两个嵌入层提取当前语料库对应的一般特征和主题特征。
(3)利用注意层发现特征的情感相关部分。
(4)采用三个并行卷积层和池化层来获得更高层次的文本表示
We propose a self-attentional multi-channel CNN to further extract textual features from input textual embeddings, which consists of two
embedding layers, an attention layer, three convolutional layers and three pooling layers。
MCNN: 自注意多通道CNN从输入文本特征中进一步提取文本特征,由两个嵌入层、一个注意层、三个卷积层和三个池化层组成。

MCNN 包含静态嵌入和动态嵌入层,其中静态嵌入层保持静态(不作任何处理),动态嵌入层通过训练进行微调,它们被看两通道。其中动态通道通过提供当前语料库的的主题信息,作为静态通道的补偿。两个通道都是通过预训练好的词向量进行初始化。

n代表第n条句子,ei∈R^dcnn,其中dcnn代表词向量的维度。最后一句话将两种特征送入注意力层,我觉得应该是卷积层不是注意力层。

这里我也觉得写错了,应该嵌入层的输出作为卷积层的输入,根据流程图,卷积层前并没有注意力层。
将嵌入层得到的特征分别输入三个卷积层(区别:卷积核不一样)然后用ReLU激活函数避免梯度消失的问题,然后分别送入注意力层。

注意层采用了多头自注意机制,目的是学习句子中的单词依赖关系。然后输入三个并行的池化层,目的是降低纬度,然后将三路特征进行拼接得到最后的文本特征。
4.3 Classifiers
使用了三个分类器:文本分类器,语音分类器、语音文本分类器,三个分类器最后的到维度分别是128, 128,64。
4.4 Decision-level fusion layer based on DS
DS strategy of belief functions, also known as evidence strategy, is a well-established formalism for reasoning and making decisions with uncertainty.
信念函数的DS策略,也称为证据策略,是一种用于推理和做出不确定性决策的成熟方式(形式主义貌似不恰当,将formalism翻译为形式或者方式)。
It is based on representing independent pieces of evidence by completely monotone abilities and combining them using Dempster’s rule. In the last two decades, DS strategy has been widely applied to classifier fusion (Zhou et al., 2016).
它的基础是用完全单调的能力表示独立的证据片段,并使用登普斯特规则将它们组合起来。在过去的二十年中,DS策略被广泛应用于分类器融合(Zhou et al., 2016)。
In particular, the outputs of several classifiers are transformed into belief functions and fused by an appropriate combination rule (Liu et al., 2018). Therefore, DS strategy is very suitable for decision-level fusion of multiple classifiers.
具体而言,将多个分类器的输出转换为信念函数,并通过适当的组合规则进行融合(Liu et al., 2018)。因此,DS策略非常适合于多分类器的决策级融合。
As shown in Fig. 1, DS strategy is utilized to fuse the prediction results from three classifiers at decision level. The final prediction result ,, is calculated as follows: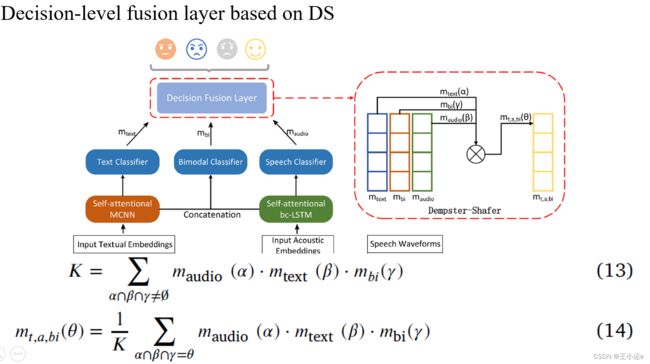

首先计算归一化系数K,其中maudio, mtext,mbi代表基本概率分配也叫mass函数(个人觉得是三个分类器得到情感概率),mt,a,bi代表当前预测结果在四类情绪上的概率分布,最后选择四个概率中最大值作为预测值。
5 Experiments
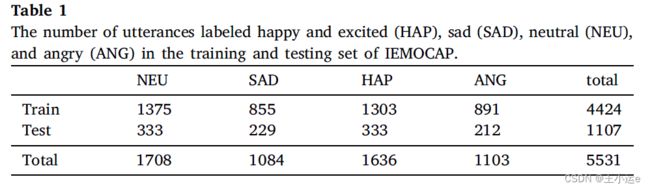
5.1 数据集
数据集:IEMOCAP的四类情感:
5.2 实验设置
Optimizer: Adam
learning rate: 0.001
Epochs: 100
Batch size: 256
Evaluation: UA & WA

5.3. 消融研究

研究文本特征提取模块,对比了三种情况,基于MCNN分别:不使用自注意力机制,不使用动态通道,不使用静态通道。
首先对比S1和S2: 通过自我注意机制来学习情绪的显著特征,能够提高识别性能。
然后对比S1和S3: 通过动态通道对特定语料库中的主题信息进行补充,提高了分类性能。
最后再对比S1和S4: 说明静态通道对于提高分类性能是必不可少的。


对比了四个方法的混淆举证,后面两个消融实验也列出了四个混淆矩阵,觉得没多大作用,我省略了。
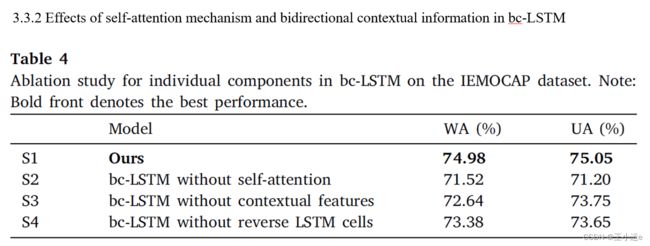
这里主要对比语音特征提取模块,三种情况:(1)不使用自注意力机制(2)不使用句子层面的语境特征(应该是不使用动态通道)(3)不使用反向的LSTM单元
对比S1和S2: 自我注意机制来学习情绪的显著特征,能够提高识别性能。
对比S1和S3:该方法通过提取句子层面的上下文情感特征,显著提高了情感识别性能
对比S1和S4: 提取用于句子级建模的双向特征提高了预测性能
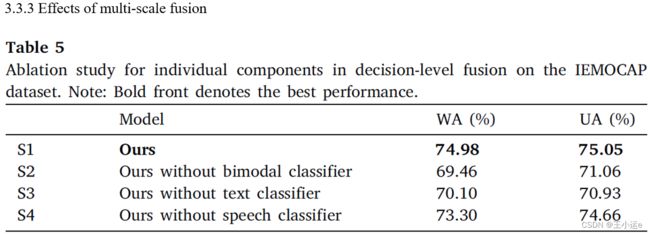
在决策层上进行实验:(1)不使用双模态的分类器(2)不使用文本分类器(3)不使用语音分类器。除了S1以外,每次都是用两个分类器进行决策。
S1和S2对比验证了特征级融合的有效性;(语音特征和文本特征的融合)
S1和S3/S4对比验证了决策级融合的有效性;
5.4 与最好的方法进行对比

作者提出的方法显示,相对于最先进的策略,WA和UA的绝对改善率分别为1.48%和3.00%。这些结果有力地证明了提出的方法可以得到有前景的SER性能。
6 Discussion
In order to investigate what kind of patterns are important in the attention layer for speech, we randomly selected samples from a batch and performed a Student’s t-test (ttest) on the mean values for each kind of original features and the features activated by the self-attention mechanism.
为了研究什么样的模式对语音的注意层是重要的,我们从一批样本中随机抽取样本,对每种原始特征和被自我注意机制激活的特征的平均值进行了T检验。


As shown in Fig. 7 and Table 7, the results of ttest revealed significant differences for MFCC (p = 0.046), MFCC (p = 0.049), F0 (p = 0.024), and F0 (p = 0.028) under the significance level of 0.05 ( = 0.05) between the original features and features activated by the self-attention mechanism,implying that the self-attention mechanism mainly highlight MFCCs, F0 and the delta coefficients of both features, which is consistent with the experimental results in Schuller et al. (2009).
如图7和表7所示,在原始特征与自我注意机制激活的特征之间显著性水平0.05(= 0.05)下,测试结果显示MFCC存在显著差异(p=0.046),MFCC(p=0.049)、F0(p=0.024)和F0(p=0.028)这意味着自我注意机制主要突出MFCC、F0和这两个特征的一阶微分特征。
α称为显著性水平(Significance level),显著性水平是数学界约定俗成的,α =0.05代表显著性检验的结论错误率必须低于5%。 参考博客:显著性检验:P值和置信度
we visualized four samples in the test set of IEMOCAP to explain how the self-attention mechanism works for text.
我们将IEMOCAP测试集中的四个样本可视化,以解释文本的自我注意机制是如何工作的。
The depth of the color indicates how important the word is. The lighter the color is, the more important the word is

In (a), the self attention mechanism highlights the words of ‘‘out’’ and ‘‘control’’ for angry emotional sentence.
In (b), the self-attention mechanism does not highlight any word for neural emotional sentence.

In ©,the self-attention mechanism highlights the word of ‘‘worthless’’ for sad emotional sentence.
In (d), the self-attention mechanism highlights the word of ‘‘romantic’’ for happy emotional sentence.
The observations for the examples above are all consistent with our intuition.
此外还讨论了模型的缺点和将来可以改进的地方
Despite the advantages mentioned above, the proposed method suffers from high computational time complexity and low convergence speed in the learning process.
In addition, memory usage is one of the criteria for judging a strategy and the high memory space requirement is the main drawback of the method.
尽管有上述优点,但该方法在学习过程中存在计算时间复杂度高、收敛速度慢的问题。
此外,内存使用情况是判断策略的标准之一,对内存空间的要求过高是该方法的主要缺点。
缺点

改进

7 Conclusion

后记
这篇论文用到了几个我之前从未见过的技术,比如:
(1)用于决策级融合的技术证据理论DS;
(2)使用T假设来分析LSTM对特征的作用;
(3)将IEMOCAP测试集中的四个样本可视化,解释文本的自我注意机制是如何工作的。
最后
我对文本这种模态不太了解,前面内容可能有错,以后有机会会去学习文本模态的使用。