- 元宇宙该洗牌了
产业深观
文/孟永辉轰轰烈烈的元宇宙大潮终究还是没有逃脱洗牌的命运,随着Meta股价的下跌以及诸多泛元宇宙概念的失色,元宇宙将无可幸免地进入到一场深度洗牌期。在目前这样一个背景之下,我们谈论元宇宙的洗牌似乎早了些,尽管如此,这种现象却正在发生着。我们不妨可以大胆想象在未来的某一个时间点,我们还将会看到更多有关元宇宙洗牌的事件的出现。如果拿互联网行业的洗牌与元宇宙行业的洗牌作对比,似乎元宇宙的洗牌来得稍微早了
- melody-canvas:实时音频可视化与创意画布
melody-canvas:实时音频可视化与创意画布项目介绍melody-canvas是一个开源项目,致力于为用户提供一个强大的音频可视化与画布编辑平台。通过该平台,用户可以利用Web技术实时地将音频信号转换成视觉元素,同时支持画布上的图像和文本编辑,创作出独一无二的音频艺术作品。项目技术分析melody-canvas的核心功能基于现代Web技术构建,主要包括以下技术组件:WebAudioAPI:
- Python 并行新思路:不移除 GIL 的多核并发之道
清水白石008
pythonPython题库python服务器开发语言
Python并行新思路:不移除GIL的多核并发之道引言大家好,我是[您的名字],一位在Python领域深耕多年的软件专家。今天,我们来探讨一个Python开发者经常面临的挑战:全局解释器锁(GIL)以及如何在它的限制下,充分利用多核CPU的并行计算能力。GIL,这个Python语言的“老朋友”,长期以来一直备受争议。它确保了在CPython解释器中,同一时刻只有一个线程执行Python字节码。这简
- 《我都要死了你让我觉醒前世记忆》林寻安妙汐_(我都要死了你让我觉醒前世记忆)全集在线阅读
热门小说_2
书名:我都要死了你让我觉醒前世记忆主角:林寻安妙汐简介:她有心中的白月光,却无法与之相伴,只能选择他作为合约替身。他拿着工资为白月光做饭,两人相处得很愉快。然而,合约即将结束时,他却被诊断出重病,只剩两个月的寿命。此时,合约老婆却希望假戏真做。可以关注微信公众号【书香名斋】去回个书名或主配角,即可免费阅读【我都要死了你让我觉醒前世记忆】小说全文!>>>>>>>>>>戳我继续阅读>>>>>>>>>戳
- 雨天日更、学习与提升,
生字游戏
首先应该注明,致自己,说成小心眼最合适,因文化成度低有些文字的词语难易运用好,所以才有如此的霞小的心思,说自私不为过只是想找个提升自己满足心理的需求,致自己安慰一翻。艺多不压身、是有意还是无意进入写的提升之门。应该说无意事实是有意的,只能说好心之人常善有,介绍进入了这个写的程序。经过看到写群里的人于事才发现、自己走进一辉煌时代年青人群里,这是他们年青人的摇蓝梦想之地,但我也仿佛佣有了一个青年人的梦
- python学智能算法(二十四)|SVM-最优化几何距离的理解
引言前序学习过程中,已经对几何距离的概念有了认知,学习链接为:几何距离这里先来回忆几何距离δ的定义:δ=mini=1...myi(w∥w∥⋅xi+b∥w∥)\delta=\min_{i=1...m}y_{i}(\frac{w}{\left\|w\right\|}\cdotx_{i}+\frac{b}{\left\|w\right\|})δ=i=1...mminyi(∥w∥w⋅xi+∥w∥b)对上
- 全新开发范式:uni-app X助力全平台原生应用
程序媛夏天
小白学鸿蒙uni-app
在2025年数字技术发展的关键节点上,国产操作系统正在经历从愿景走向现实的深刻变革。DCloud于5月12日发布的HBuilderX4.64正式版,标志着uni-appx已实现对鸿蒙、Android、iOS、Web、微信小程序等主流平台的全覆盖,为开发者带来了全新的跨平台开发体验。一、技术革新:Web技术栈与原生性能的完美融合uni-appx的突破性在于其独特的设计理念:“开发态基于Web技术栈,
- stm32内存分析
1、0x00-0x7FFFF有什么用??为什么是512KMbyteSRAMSystem-MemoryFlash的内存映射;映射中最大的内存大小2、SystemMemory有什么用出厂预置的Bootloader系统启动控制固件更新支持调式与恢复3、I-busD-BUSS-BUS能不能访问SRAM?当启动模式是SRAM时可以4、初始化flash时,用的是那个总线去访问??I-busD-busS-BUS
- Kotlin flow实践总结
Android技术圈
Flow是什么按顺序发出多个值的数据流。本质就是一个生产者消费者模型,生产者发送数据给消费者进行消费。冷流:当执行collect的时候(也就是有消费者的时候),生产者才开始发射数据流。生产者与消费者是一对一的关系。当生产者发送数据的时候,对应的消费者才可以收到数据。热流:不管有没有执行collect(也就是不管有没有消费者),生产者都会发射数据流到内存中。生产者与消费者是一对多的关系。当生产者发送
- 树莓派i2c通信C语言,基于I2C的STM32与树莓派通信
茶话股经
树莓派i2c通信C语言
传统的串口通信会丢失数据,不可靠,故采用I2C(同步串行总线)通信。树莓派上使用python脚本,后期将使用c或java重写,目前没有需求。树莓派作主机(Master),stm32作从机(Slave)。特别需要注意的是,I2C的通信虽然只需要两根线就能通信,但是需要第三根线接地GND(提供判断低电位的能力),否则不能正常识别stm32从机使用ArduinoIDE编程以下是STM32的代码:#inc
- 如何提高JPA项目的扩展性:模块解耦的实践与策略
在企业级开发中,JPA(JavaPersistenceAPI)因其对象关系映射的强大能力,常被用于构建业务层与数据层之间的桥梁。然而,随着项目复杂度增加,JPA项目常常面临模块之间强依赖、跨模块实体耦合、难以演进等问题,严重影响系统的可扩展性和可维护性。相比之下,MyBatis项目由于其“SQL即服务”的特性,天然具备更强的解耦性。本文将分析JPA项目中常见的模块依赖问题,探讨其背后的原因,并提供
- 高省、好省、粉象、福袋生活、高佣联盟、美逛佣金显示与下单时不一样?
高省APP
最近很多高省、好省、粉象、福袋生活、高佣联盟、美逛的宝宝反馈下单后,佣金显示与下单时不一样。导致这个问题的原因是用了小红包,提交订单时,红包选项一定要关闭,切记不要勾选红包,用红包没佣金或者佣金变得很低。高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。古楼导师高省邀请码555888,注册送2皇冠会员,送万元推广大
- 我与《写作》的故事
开心果子
要想提高写作能力,就要磨练写故事的能力,昨天读了叶老师与阅读的故事,今天又再写作的故事里相逢,跟叶老师隔着书本进行了一场对话,我就是那大部分小伙伴中的一员,在微信读书《认知觉醒》的书评里认识了叶老师,通过叶老师的写作,来到这里与大家相聚。我也来讲讲,我与写作的故事。2022年8月7日,我读到了《逆熵增成长之路》的写作篇,开始注册写下第一篇文章《日更百天挑战》,到今天24天,写了28篇小短文,2.2
- 2020-07-25
京心达_周莎
2020.7.25今日体验:每个人都有可能犯错,彼此之间的伤害很难避免。凡事看淡一些,不要满怀怨恨,怒气冲天。生气就是拿别人的过错来惩罚自己。心中装满怨恨,也就失去了阳光与温暖。
- 高佣联盟是怎么赚钱的?和高佣联盟一样的平台有哪些?
氧惠评测
高佣联盟是怎么赚钱的?高佣联盟主要通过以下几种方式赚钱:推广佣金:高佣联盟与多个电商平台(如淘宝、京东、天猫等)建立合作关系。每当用户通过高佣联盟进入这些电商平台并完成购物后,高佣联盟会从电商平台上获得一定的推广佣金。这是高佣联盟最主要的盈利方式之一。推广者通过在高佣联盟平台上分享购物体验、使用心得等,引导消费者购买商品或服务。当消费者完成购买后,推广者将获得相应的佣金。商家佣金:当商家在高佣联盟
- 树莓派与stm32进行串口通信
黄昏489
stm32嵌入式硬件单片机
目前很多大学电子类的比赛中,进行通信的大部分是用到串口进行通信,因此打算出一期有关stm32与树莓派进行通信的博客,目前这是第一篇,因此这一篇博客主要简单讲讲stm32的串口通信,其中包含硬件的接线图,以及相关程序,后续有时间会继续出stm32与树莓派的串口通信,原理都是一样的。与其他博客不相同的地方在于,对于串口的解释上我不作过多解释,重点主要在于能“拿来就用”,以及我在使用stm32时候所踩过
- 2023-03-21 好消息
快乐的老猫
昨天上午,国义发了朋友圈,原文转载如下。各位领导、同事、朋友,本人去年12月27日起,多次感染新冠,两次昏迷,四进ICU,一直在与死神赛跑,经过两个半月的长时间住院治疗,在医护人员的努力和朋友们祝福的加持下,终于在上周稳定下来,出院回到家中。感恩你们的爱使我能够战胜病魔。祝愿大家新的一年开心、健康、幸福、快乐,这是个迟来的祝福,确是最真诚的祝福,希望大家理解。今日春分。
- 华为OD机试2025C卷 - 计算三叉搜索树的高度 (C++ & Python & JAVA & JS & GO)
无限码力
华为OD机试真题刷题笔记华为od华为OD机试2025C卷华为OD2025C卷华为OD机考2025C卷
计算三叉搜索树的高度华为OD机试真题目录点击查看:华为OD机试2025C卷真题题库目录|机考题库+算法考点详解华为OD机试2025C卷100分题型题目描述定义构造三叉搜索树规则如下:每个节点都存有一个数,当插入一个新的数时,从根节点向下寻找,直到找到一个合适的空节点插入。查找的规则是:如果数小于节点的数减去500,则将数插入节点的左子树如果数大于节点的数加上500,则将数插入节点的右子树否则,将数
- 华为OD面试手撕真题 - 字符串解码 (C++ & Python & JAVA & JS & GO)
无限码力
华为OD面试手撕代码真题合集华为od面试手撕真题华为OD面试手撕真题
题目描述给定一个经过编码的字符串,返回它解码后的字符串。编码规则为:k[encoded_string],表示其中方括号内部的encoded_string正好重复k次。注意k保证为正整数。你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数k,例如不会出现像3a或2[4]的输入。示例1输入:s="
- 《随园诗话》学习与译注
意趣与刺点
卷六八十三原文前朝番禺黎美周,少年玉貌,在扬州赋《黄牡丹》诗。某宗伯品为第一人,呼为“牡丹状元花主人”。郑超宗,故豪士也,用锦舆歌吹,拥“状元”游廿四桥。士女观者如堵。还归粤中,郊迎者千人。美周被锦袍,坐画舫,选珠娘之丽者,排列两行,如天女之拥神仙。相传:有明三百年真状元,无此貌,亦无此荣也。其诗十章,虽整齐华赡,亦无甚意思。惟“窥浴转愁金照眼,割盟须记赭留衣”一联,稍切“黄”字。后美周终不第,陈
- 七、Uniapp+vue+腾讯IM+腾讯音视频开发仿微信的IM聊天APP,支持各类消息收发,音视频通话,附vue实现源码(已开源)-聊天消息项的实现
智密科技
uniapp插件IM源码音视频微信uni-app源码im
会话好友列表的实现1、项目引言2、腾讯云后台配置TXIM3、配置项目并实现IM登录4、会话好友列表的实现5、聊天输入框的实现6、聊天界面容器的实现7、聊天消息项的实现8、聊天输入框扩展面板的实现9、聊天会话管理的实现10、聊天记录的加载与消息收发11、定位SD配置与收发定位消息12、贴图表情的定制化开发13、腾讯云后台配置TRTC功能14、集成音视频通话功能15、集成仿微信的拍照,相册选择插件16
- 《你走出了自己的路》
清秋原创诗文
你走出了属于自己的路作者/经典清秋zh图片发自App图片发自App每个人在现实的生活里都有烦心事,只是不想说出来,回忆这些年的是非恩怨过往,我似是清澈明了,一味的固执己见其实并非如我想那般能得圆满。如果说人要坚定不移的维护自己的自尊心去自圆其说的与对方争辩,只为了所谓的自尊心,赢了又如何,失去了信任,那我宁愿说一句我错了,不是将就,不是怜惜,只是想温和的方式解决问题。记得《狐妖小红娘》里,有一句台
- SPI 与API,以及java,spring,dubbo 三者SPI的区别
✅SPI机制详解:Java/Spring/Dubbo/Maven一、什么是SPI(ServiceProviderInterface)SPI=一种扩展机制,框架通过接口+注册,让你实现并插入自己的逻辑。API(ApplicationProgrammingInterface):框架实现,开发者调用(下行)。SPI(ServiceProviderInterface):框架定义接口,开发者实现,框架调用(
- 返利APP佣金比拼:氧惠与粉象生活,谁更胜一筹?
氧惠好项目
返利APP佣金对比:氧惠与粉象生活,谁更胜一筹?**尽享优惠,就选氧惠APP——购物、观影、点餐全覆盖!氧惠,一个颠覆传统的优惠平台,将抖客与淘客完美结合,为您带来2024年全新的优惠体验!在这里,您的直接推荐将自动归入您的团队,享受1:1的超级补贴政策——您的朋友自购多少,您就能获得相应的推广奖励,如此强大的激励机制,绝对让您惊喜连连!我们诚挚邀请各位团队长前来体验,共同见证氧惠的非凡魅力。同时
- 12306系统架构的演进
演进过程12306系统架构的演进是中国铁路信息化建设的重要里程碑,其核心围绕高并发处理、数据一致性保障、跨地域容灾三大挑战展开。以下是其分阶段的技术演进过程:第一阶段:单机架构与双机热备(2011年)背景2011年上线初期,12306仅支持京津城际列车购票,日均售票量不足百万。系统采用传统单体架构,依赖小型机和集中式数据库,缺乏分布式设计。架构特点技术栈:JavaServlet+JSP+Sybas
- 《你要活成一束光》读书笔记
彩云悦读乐教
这是一本很有温度的书。本书以写信的形式道出了人间条条真理,语言朴实却给人感触至深,书中的四十封书信,有写给女儿、儿子的;有写给老爸、妈妈的;有写给爱人、亲人、朋友的;还有写给陌生的兄弟的,每一封信都会有不同的感悟与体会,每一封信都传达着真挚的爱意,它像是一束光,周身散发着巨大而美好的能量…该书文笔流畅,语言清新优美,画面感十足,字里行间充满了浓浓的亲情、友情、爱情,让人感动!读的时候会让人大笑,会
- Java 领域 Dubbo 服务注册与发现机制详解
Java大师兄学大数据AI应用开发
javadubbo开发语言ai
Java领域Dubbo服务注册与发现机制详解关键词:Dubbo、服务注册、服务发现、微服务、RPC、Zookeeper、负载均衡摘要:本文深入剖析了Dubbo框架中的服务注册与发现机制,从核心概念到实现原理,再到实际应用场景和最佳实践。我们将通过源码分析、架构图解和实战案例,全面讲解Dubbo如何实现高效的服务治理,包括注册中心的作用、服务提供者与消费者的交互流程、负载均衡策略等关键内容。文章还将
- Python编程:从入门到实践
YC运维
Python_studypython学习开发语言
这是基于《Python编程:从入门到实践》这本书以一个初学者的视角去学习而记录的笔记,浓缩了精华的部分以及分享了一些我自己的见解。做这个既是为了让自己边学边记录也是为了保留自己的问题去和小伙伴一起谈论。一,python是什么以及核心作用Python是一种高级、解释型、面向对象的编程语言,由荷兰人GuidovanRossum于1989年圣诞节期间创建,第一个公开发行版发行于1991年。它的设计哲学强
- NAT的核心原理以及配置
YC运维
华三运维实验服务器网络华三NAT
NAT(NetworkAddressTranslation,网络地址转换)是解决IPv4地址资源枯竭的关键技术,其核心作用是在私有网络(内部网络)与公共网络(外部网络)的边界设备上,对数据包的IP地址和端口信息进行转换,实现私有IP地址与公网IP地址的映射,从而让多个内部主机共享少量公网IP访问外部网络,或让外部网络访问内部特定服务。一、NAT核心原理概述1.NAT的核心作用节省公网IP资源:通过
- 一种健全的人格,比一百种智慧更有力量
背着壳爬行的乌龟
生活中总会看到一些明明很聪明的人却不如别人过得好,虽然这个好并不是和别人攀比显得的好,有的是因嫉妒别人而处处与别人为敌,有的因自卑情节觉得自己再怎么努力也敢不上别人而迟迟不肯行动,如果我们都能用横向关系看待每一种关系,比如人际关系、工作关系等等,相信自己并勇敢行动,不在意别人的看法,我们就能更有力量。
- 遍历dom 并且存储(将每一层的DOM元素存在数组中)
换个号韩国红果果
JavaScripthtml
数组从0开始!!
var a=[],i=0;
for(var j=0;j<30;j++){
a[j]=[];//数组里套数组,且第i层存储在第a[i]中
}
function walkDOM(n){
do{
if(n.nodeType!==3)//筛选去除#text类型
a[i].push(n);
//con
- Android+Jquery Mobile学习系列(9)-总结和代码分享
白糖_
JQuery Mobile
目录导航
经过一个多月的边学习边练手,学会了Android基于Web开发的毛皮,其实开发过程中用Android原生API不是很多,更多的是HTML/Javascript/Css。
个人觉得基于WebView的Jquery Mobile开发有以下优点:
1、对于刚从Java Web转型过来的同学非常适合,只要懂得HTML开发就可以上手做事。
2、jquerym
- impala参考资料
dayutianfei
impala
记录一些有用的Impala资料
1. 入门资料
>>官网翻译:
http://my.oschina.net/weiqingbin/blog?catalog=423691
2. 实用进阶
>>代码&架构分析:
Impala/Hive现状分析与前景展望:http
- JAVA 静态变量与非静态变量初始化顺序之新解
周凡杨
java静态非静态顺序
今天和同事争论一问题,关于静态变量与非静态变量的初始化顺序,谁先谁后,最终想整理出来!测试代码:
import java.util.Map;
public class T {
public static T t = new T();
private Map map = new HashMap();
public T(){
System.out.println(&quo
- 跳出iframe返回外层页面
g21121
iframe
在web开发过程中难免要用到iframe,但当连接超时或跳转到公共页面时就会出现超时页面显示在iframe中,这时我们就需要跳出这个iframe到达一个公共页面去。
首先跳转到一个中间页,这个页面用于判断是否在iframe中,在页面加载的过程中调用如下代码:
<script type="text/javascript">
//<!--
function
- JAVA多线程监听JMS、MQ队列
510888780
java多线程
背景:消息队列中有非常多的消息需要处理,并且监听器onMessage()方法中的业务逻辑也相对比较复杂,为了加快队列消息的读取、处理速度。可以通过加快读取速度和加快处理速度来考虑。因此从这两个方面都使用多线程来处理。对于消息处理的业务处理逻辑用线程池来做。对于加快消息监听读取速度可以使用1.使用多个监听器监听一个队列;2.使用一个监听器开启多线程监听。
对于上面提到的方法2使用一个监听器开启多线
- 第一个SpringMvc例子
布衣凌宇
spring mvc
第一步:导入需要的包;
第二步:配置web.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi=
- 我的spring学习笔记15-容器扩展点之PropertyOverrideConfigurer
aijuans
Spring3
PropertyOverrideConfigurer类似于PropertyPlaceholderConfigurer,但是与后者相比,前者对于bean属性可以有缺省值或者根本没有值。也就是说如果properties文件中没有某个bean属性的内容,那么将使用上下文(配置的xml文件)中相应定义的值。如果properties文件中有bean属性的内容,那么就用properties文件中的值来代替上下
- 通过XSD验证XML
antlove
xmlschemaxsdvalidationSchemaFactory
1. XmlValidation.java
package xml.validation;
import java.io.InputStream;
import javax.xml.XMLConstants;
import javax.xml.transform.stream.StreamSource;
import javax.xml.validation.Schem
- 文本流与字符集
百合不是茶
PrintWrite()的使用字符集名字 别名获取
文本数据的输入输出;
输入;数据流,缓冲流
输出;介绍向文本打印格式化的输出PrintWrite();
package 文本流;
import java.io.FileNotFound
- ibatis模糊查询sqlmap-mapping-**.xml配置
bijian1013
ibatis
正常我们写ibatis的sqlmap-mapping-*.xml文件时,传入的参数都用##标识,如下所示:
<resultMap id="personInfo" class="com.bijian.study.dto.PersonDTO">
<res
- java jvm常用命令工具——jdb命令(The Java Debugger)
bijian1013
javajvmjdb
用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。
现在应该说日常的开发中很少用到JDB了,因为现在的IDE已经帮我们封装好了,如使用ECLI
- 【Spring框架二】Spring常用注解之Component、Repository、Service和Controller注解
bit1129
controller
在Spring常用注解第一步部分【Spring框架一】Spring常用注解之Autowired和Resource注解(http://bit1129.iteye.com/blog/2114084)中介绍了Autowired和Resource两个注解的功能,它们用于将依赖根据名称或者类型进行自动的注入,这简化了在XML中,依赖注入部分的XML的编写,但是UserDao和UserService两个bea
- cxf wsdl2java生成代码super出错,构造函数不匹配
bitray
super
由于过去对于soap协议的cxf接触的不是很多,所以遇到了也是迷糊了一会.后来经过查找资料才得以解决. 初始原因一般是由于jaxws2.2规范和jdk6及以上不兼容导致的.所以要强制降为jaxws2.1进行编译生成.我们需要少量的修改:
我们原来的代码
wsdl2java com.test.xxx -client http://.....
修改后的代
- 动态页面正文部分中文乱码排障一例
ronin47
公司网站一部分动态页面,早先使用apache+resin的架构运行,考虑到高并发访问下的响应性能问题,在前不久逐步开始用nginx替换掉了apache。 不过随后发现了一个问题,随意进入某一有分页的网页,第一页是正常的(因为静态化过了);点“下一页”,出来的页面两边正常,中间部分的标题、关键字等也正常,唯独每个标题下的正文无法正常显示。 因为有做过系统调整,所以第一反应就是新上
- java-54- 调整数组顺序使奇数位于偶数前面
bylijinnan
java
import java.util.Arrays;
import java.util.Random;
import ljn.help.Helper;
public class OddBeforeEven {
/**
* Q 54 调整数组顺序使奇数位于偶数前面
* 输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半
- 从100PV到1亿级PV网站架构演变
cfyme
网站架构
一个网站就像一个人,存在一个从小到大的过程。养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原则。本文结合我自已14年网站人的经历记录一些架构演变中的体会。 1:积累是必不可少的
架构师不是一天练成的。
1999年,我作了一个个人主页,在学校内的虚拟空间,参加了一次主页大赛,几个DREAMWEAVER的页面,几个TABLE作布局,一个DB连接,几行PHP的代码嵌入在HTM
- [宇宙时代]宇宙时代的GIS是什么?
comsci
Gis
我们都知道一个事实,在行星内部的时候,因为地理信息的坐标都是相对固定的,所以我们获取一组GIS数据之后,就可以存储到硬盘中,长久使用。。。但是,请注意,这种经验在宇宙时代是不能够被继续使用的
宇宙是一个高维时空
- 详解create database命令
czmmiao
database
完整命令
CREATE DATABASE mynewdb USER SYS IDENTIFIED BY sys_password USER SYSTEM IDENTIFIED BY system_password LOGFILE GROUP 1 ('/u01/logs/my/redo01a.log','/u02/logs/m
- 几句不中听却不得不认可的话
datageek
1、人丑就该多读书。
2、你不快乐是因为:你可以像猪一样懒,却无法像只猪一样懒得心安理得。
3、如果你太在意别人的看法,那么你的生活将变成一件裤衩,别人放什么屁,你都得接着。
4、你的问题主要在于:读书不多而买书太多,读书太少又特爱思考,还他妈话痨。
5、与禽兽搏斗的三种结局:(1)、赢了,比禽兽还禽兽。(2)、输了,禽兽不如。(3)、平了,跟禽兽没两样。结论:选择正确的对手很重要。
6
- 1 14:00 PHP中的“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误
dcj3sjt126com
PHP
原文地址:http://www.kafka0102.com/2010/08/281.html
因为需要,今天晚些在本机使用PHP做些测试,PHP脚本依赖了一堆我也不清楚做什么用的库。结果一跑起来,就报出类似下面的错误:“Parse error: syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM in /home/kafka/test/
- xcode6 Auto layout and size classes
dcj3sjt126com
ios
官方GUI
https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/AutolayoutPG/Introduction/Introduction.html
iOS中使用自动布局(一)
http://www.cocoachina.com/ind
- 通过PreparedStatement批量执行sql语句【sql语句相同,值不同】
梦见x光
sql事务批量执行
比如说:我有一个List需要添加到数据库中,那么我该如何通过PreparedStatement来操作呢?
public void addCustomerByCommit(Connection conn , List<Customer> customerList)
{
String sql = "inseret into customer(id
- 程序员必知必会----linux常用命令之十【系统相关】
hanqunfeng
Linux常用命令
一.linux快捷键
Ctrl+C : 终止当前命令
Ctrl+S : 暂停屏幕输出
Ctrl+Q : 恢复屏幕输出
Ctrl+U : 删除当前行光标前的所有字符
Ctrl+Z : 挂起当前正在执行的进程
Ctrl+L : 清除终端屏幕,相当于clear
二.终端命令
clear : 清除终端屏幕
reset : 重置视窗,当屏幕编码混乱时使用
time com
- NGINX
IXHONG
nginx
pcre 编译安装 nginx
conf/vhost/test.conf
upstream admin {
server 127.0.0.1:8080;
}
server {
listen 80;
&
- 设计模式--工厂模式
kerryg
设计模式
工厂方式模式分为三种:
1、普通工厂模式:建立一个工厂类,对实现了同一个接口的一些类进行实例的创建。
2、多个工厂方法的模式:就是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式就是提供多个工厂方法,分别创建对象。
3、静态工厂方法模式:就是将上面的多个工厂方法模式里的方法置为静态,
- Spring InitializingBean/init-method和DisposableBean/destroy-method
mx_xiehd
javaspringbeanxml
1.initializingBean/init-method
实现org.springframework.beans.factory.InitializingBean接口允许一个bean在它的所有必须属性被BeanFactory设置后,来执行初始化的工作,InitialzingBean仅仅指定了一个方法。
通常InitializingBean接口的使用是能够被避免的,(不鼓励使用,因为没有必要
- 解决Centos下vim粘贴内容格式混乱问题
qindongliang1922
centosvim
有时候,我们在向vim打开的一个xml,或者任意文件中,拷贝粘贴的代码时,格式莫名其毛的就混乱了,然后自己一个个再重新,把格式排列好,非常耗时,而且很不爽,那么有没有办法避免呢? 答案是肯定的,设置下缩进格式就可以了,非常简单: 在用户的根目录下 直接vi ~/.vimrc文件 然后将set pastetoggle=<F9> 写入这个文件中,保存退出,重新登录,
- netty大并发请求问题
tianzhihehe
netty
多线程并发使用同一个channel
java.nio.BufferOverflowException: null
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:183) ~[na:1.7.0_60-ea]
at java.nio.ByteBuffer.put(ByteBuffer.java:832) ~[na:1.7.0_60-ea]
- Hadoop NameNode单点问题解决方案之一 AvatarNode
wyz2009107220
NameNode
我们遇到的情况
Hadoop NameNode存在单点问题。这个问题会影响分布式平台24*7运行。先说说我们的情况吧。
我们的团队负责管理一个1200节点的集群(总大小12PB),目前是运行版本为Hadoop 0.20,transaction logs写入一个共享的NFS filer(注:NetApp NFS Filer)。
经常遇到需要中断服务的问题是给hadoop打补丁。 DataNod
 的建模就是用的标准正态分布,统计学的学生分布就是从正态分布中导出。随着贝叶斯统计学的广泛应用,相乘的高斯分布(高斯先验)等形式也出现在公式中,例如高斯线性系统,本文就这些形式进行说明。
的建模就是用的标准正态分布,统计学的学生分布就是从正态分布中导出。随着贝叶斯统计学的广泛应用,相乘的高斯分布(高斯先验)等形式也出现在公式中,例如高斯线性系统,本文就这些形式进行说明。 的高斯分布,现计算高斯分布的乘积
的高斯分布,现计算高斯分布的乘积

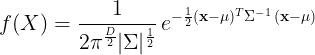




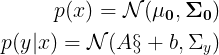
 由
由

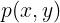 逆协方差矩阵:
逆协方差矩阵: