机器学习实战(十一)——使用Apriori算法进行关联分析
机器学习实战(十一)——使用Apriori算法进行关联分析
一、关联分析
关联分析是在一个大规模的数据集中寻找有趣关系的任务。而这些“有趣关系”可以有两种形式来表达:频繁项集或者关联规则。下面由一个例子来说明:
| 交易号码 | 商品 |
|---|---|
| 0 | 豆奶,莴苣 |
| 1 | 莴苣,尿布,葡萄酒,甜菜 |
| 2 | 豆奶,尿布,葡萄酒,橙汁 |
| 3 | 莴苣,豆奶,尿布,葡萄酒 |
| 4 | 莴苣,豆奶,尿布,橙汁 |
该表格为某简单交易清单。那么可以由这个例子来说明定义:
- 频繁项集:经常出现在一块的物品的集合,例如表格中经常出现葡萄酒、尿布、豆奶就是一个例子
- 关联规则:两种物品之间可能存在很强的关系,例如上面尿布总是和葡萄酒一起出现,那么就可能存在尿布->葡萄酒的关联规则。
那么如何定义一个商品集合属不属于频繁项集,以及如何定义有趣关系呢?则由支持度和可信度来完成。
- 支持度:一个项集的支持度定义为数据集中包含该项集的记录所占有的比例,例如上表中{豆奶}的支持度为 4 / 5 4/5 4/5,而{豆奶,尿布}的为 3 / 5 3/5 3/5。因此可以定义定义一个最小支持度,那些出现次数太少的项集就不考虑了,可以降低计算复杂度
- 可信度(置信度):用以定义关联规则,例如{尿布}->{葡萄酒}这条关联规则的可信度被定义为支持度{尿布,葡萄酒} / 支持度{尿布} ,有点类似于条件概率的定义。
虽然定义了量化定义的方法,但是如果对每一个项集都计算的话将会有很大的计算量,因为随着物品数量的增加,它们之间的组合数据是呈现指数级增加的。因此就引入了Apriori原理。
二、Apriori原理
例如当前有4种商品,那么它们可能有的项集如下:
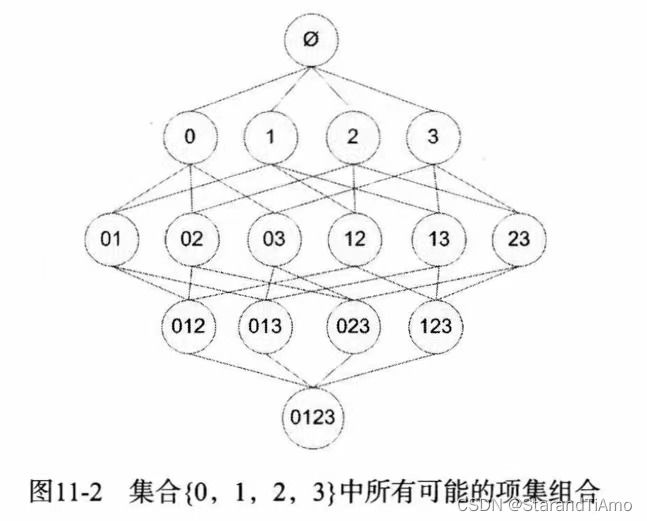
因此如果我们要计算各种项集的支持度,最简单的方法当然是通过不断遍历数据集来统计每一个项集所出现的次数。但对于包含 N N N种物品的数据集就会有 2 N − 1 2^N-1 2N−1种项集组合,这个计算量过大。因此可以利用Apriori原理
- Apriori原理:如果某一个项集是频繁的(支持度大于最小支持度),那么它的所有子集也都是频繁的
例如项集{0,2}是频繁的,那么{0}和{2}也一定是频繁的。
那么如果我们反过来看这个思路,即可得:
- 如果一个项集是非频繁,那么它的所有超集(包含它的集合)就一定是非频繁的
例如如果{2,3}是非频繁的,那么{1,2,3}就一定也是非频繁的。因此可以从图中最上层的集合开始计算支持度,一旦发现非频繁的集合那么它的所有超集也就不用计算了,可以很好地减低计算量。

例如上图如果{2,3}是非频繁的,那么它的超集{0,2,3}、{1,2,3}、{0,1,2,3}就一定也是非频繁的,就不用计算了。
三、使用 Apriori算法来发现频繁集
经过前文的叙述我们不难发现,必须先找到频繁项集才能够获得关联规则。因此我们需要先用Apriori 算法来发现频繁项集。该算法有两个输入参数,分别是最小支持度和数据集。具体的流程大概为:先生成所有单个物品的项集列表,然后扫描数据集计算各个物品的支持度,把那些不满足最小支持度的去除掉;再对剩下的集合生成含有两个物品的项集,再扫描剔除,依次循环直到所有项集都被去除掉。
3.1、生成候选项集
在运行Apriori 算法之前需要辅助函数,包括构建初始集合的函数,扫描数据集以寻找交易记录子集的函数。其中数据集扫描的伪代码如下:
遍历数据集中的每天交易记录tran:
遍历每个候选项集can:
检查can是否是tran的子集:
如果是则增加can的计数值
遍历每个候选项集:
如果其支持度大于最小支持度则保留
返回所有频繁项集列表
接下来为辅助函数的代码:
def loadDataSet():
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
# 用于对数据集构建初始项集
def createC1(dataSet):
C1 =[] # 用来存放初始项集
for transaction in dataSet: # 遍历每一个交易记录
for item in transaction: # 遍历记录中的每一个物品
if not [item] in C1: # 以列表作为元素,因为不能单独对一个int执行set
C1.append([item]) # 不在则作为新物品添加
C1.sort() # 排序函数
return list(map(frozenset,C1)) # frozenset是不可变集合,将C1中的每一个物品的变成不可变的集合
def scanD(D,Ck,minSupport):
ssCnt = {} # 空字典
for tid in D: # 遍历数据集的所有交易记录
for can in Ck: # 遍历当前的项集
if can.issubset(tid): # can中的所有元素是否都在tid中
ssCnt[can] = ssCnt.get(can,0) + 1
# python3废除了has_key方法,可以用get 方法代替
numItems = float(len(D))
retList = [] # 用来存放满足支持度的那些项集
supportData = {} # 用来存放所有项集与其对应的支持度
for key in ssCnt:
support1 = ssCnt[key] / numItems
if support1 >= minSupport: # 如果满足最小支持度的要求
retList.insert(0,key) # 将key插入到索引为0的位置
supportData[key] = support1
return retList,supportData
原文中的has_key方法在python3中已经废弃了,它的主要目的就是判断集合can是否在字典ssCnt中,那我们可以通过get方法,如果不在的话默认值是返回None,这里我们让它不存在就返回0即可。
3.2、组织完整的Apriori算法
具体的代码如下:
def aprioriGen(Lk,k):
retList = [] # 用来存放新的项集
lenLk = len(Lk)
# 构建新项集的思路是遍历每个元素,两两之间如果只有1个不相同就可以加在一起
# 当前项集中每一个元素的长度为k
for i in range(lenLk): # 外层遍历
for j in range(i+1, lenLk): # 内层遍历
L1 = list(Lk[i])[:k-2] # 取出前k-1个元素,就是索引到k-2
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1 == L2: # 如果相等,说明Lk[i]和Lk[j]只有第k个元素不等
retList.append(Lk[i] | Lk[j])
# 采用集合的并方法将其添加到新集合中
return retList
def apriori(dataSet,minSupport=0.5):
C1 = createC1(dataSet)
D = list(map(set,dataSet)) # 这里set不是将dataSet中的重复交易记录去除掉
# 而是将dataSet的每一个交易记录中重复购买的东西去除掉
L1, supportData = scanD(D,C1,minSupport)
L = [L1]
k = 2
while len(L[k - 2]) > 0: # 直到下一个项集为空
Ck = aprioriGen(L[k-2],k) # 新的项集
Lk, supK = scanD(D,Ck,minSupport) # 选取符合最小支持度的
supportData.update(supK) # 将新的项集和对应的支持度更新到支持度字典中
L.append(Lk) # 直到Lk为空,下一次循环的时候就退出了
k += 1
return L,supportData
重点解释第一个函数中为什么要索引到k-2:像我其中备注的那般,因为合并的原则就是两个集合之间只有一个元素不相同,那么合并之后大小才会只增加1,那么这里的思路就是当前集合都有k个元素,只要前k-1个元素相同,由于集合的互异性,第k个元素必然不相同,那么就可以合并。那么这里就会有一个问题,为什么只合并最后一个元素不相同的情况,如果是中间的元素不相同呢?例如有没有可能存在 :
- {1,2,4},{1,3,4},然后没有{1,2,3},那么这样如果将{1,2,4}和{1,3,4}合并,也可以达成{1,2,3,4}。而按照前面的思路就不能合并
有没有上述这种情况呢?不可能,因为如果没有{1,2,3},那么集合{1,2}和集合{1,3}就不可能存在了,那么{1,2,4}和{1,3,4}也就不可能存在了。因此直接找只有最后一个不相同就可以了。
四、从频繁项集中挖掘关联规则
首先需要先明确一个定义,如果有一个频繁项集{豆奶,莴苣},那么就可能会有一条关联规则”豆奶->莴苣“,但是返回来并不一定成立,就是不一定会有"莴苣->豆奶”。
类似于前面支持度的定义,本处对于关联规则的定义为可信度,一条规则 P − > H P->H P−>H的可信度定义为: s u p p o r t ( P ∣ H ) / s u p p o r t ( P ) support(P | H) /support(P) support(P∣H)/support(P),就是 P , H P,H P,H两个集合的并集的支持度除以 P P P集合的支持度。而类似的也有最小可信度的要求,对于不满足的规则同样要去除掉。
那么应该找哪些规则呢?或者说从频繁项集中可以生成多少条规则呢?
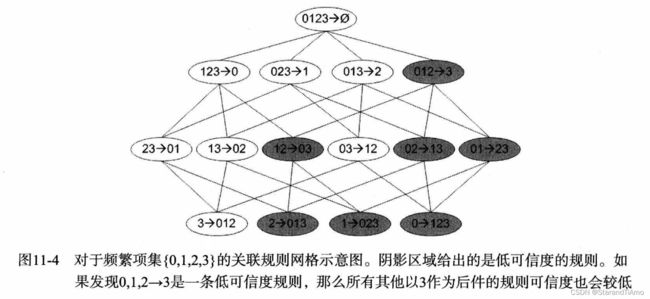
这只是由频繁项集{0,1,2,3}所生成的关联规则,理论说对于每一个频繁项集都可以生成许多关联规则。那么与之前类似,也需要通过某些定理来降低计算的复杂度。具体为:
- 如果某条规则并不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求
如上图,如果规则 0 , 1 , 2 − > 3 {0,1,2}->{3} 0,1,2−>3并不满足规则度要求(黑色),那么其子集也都通通不满足。
具体的代码为:
def generateRules(L, supportData, minConf = 0.7):
bigRuleList = [] # 用来存储符合条件的规则
for i in range(1,len(L)): # 索引0中只有单个元素无法构建规则,从索引1有两个元素的开始
for freqSet in L[i]: # 遍历当前的每一个频繁项集
#print("freqSet = ",freqSet)
Hl = [frozenset([item]) for item in freqSet] # 拆成单个元素的集合构成的列表
#print("Hl = ",Hl)
if i > 1: # i>1,则说明每个频繁项集大小大于2,那么可能有右端大于1的可能
rulesFromConseq(freqSet,Hl,supportData,bigRuleList,minConf)
else: # i=1的话,频繁项集只有2的元素,只有右端为1的可能
calcConf(freqSet,Hl,supportData,bigRuleList,minConf)
return bigRuleList
def calcConf(freqSet,H,supportData,brl,minConf = 0.7):
# freqset为当前的频繁项集,H存放其子集,不是全部的,长度不断增加的
#print("进入calcConf函数")
prunedH = [] # 用来存放那些规则的可信度满足要求的右端
for conseq in H: # 遍历freqset当前H长度的子集
#print("conseq = ",conseq)
conf = supportData[freqSet] / supportData[freqSet - conseq]
# 计算可信度,-代表集合的去除操作
#print("conf = ",conf)
if conf >= minConf:
print(freqSet-conseq,"--->",conseq,' conf: ',conf)
brl.append((freqSet-conseq,conseq,conf)) # 存放所有的满足条件的规则
prunedH.append(conseq) # 用来放当前满足的,返回可以进入下一次迭代
return prunedH
def rulesFromConseq(freqSet, H,supportData,brl,minConf = 0.7):
#print("进入rulesFromConseq函数")
m = len(H[0]) # 当前子集的长度
if len(freqSet) > (m+1): # 如果大于说明还能移除大小为m+1的子集来构建规则
Hmp1 = aprioriGen(H,m+1) # 用H中的集合取拼凑成长度为m+1的子集
#print("Hmp1 = ",Hmp1)
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)
# 计算当前频繁项集与Hmp1这些子集的规则的可信度,返回的符合条件的规则的右端放入Hmp1中
#print("Hmp1 = ",Hmp1)
if len(Hmp1) > 1:
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
具体的思路就是:
- 从前面构建出来的频繁项集的集合中,按照长度去遍历,第一次取长度为2的频繁项集(长度为1的频繁项集没办法构建规则)
- 遍历其中的每一个频繁项集can:
- 将其拆分成单个元素的集合构成的列表H
- 如果can的长度为2,那么直接计算每一个频繁项集与所有子集H的可信度即可,因为can没办法再去移除元素到右端来计算可信度
- 如果can的长度大于2,那么就需要考虑将can的部分元素移动到右端,使右端能够形成新的子集从而来判断新的规则
- 遍历其中的每一个频繁项集can:
这里目前我仍然有一个问题,就是例如当can的长度大于2,那么会直接进入rulesFromConseq函数,进入之后就会将子集H进行合并成Hmq1,再用Hmq1的元素去计算可信度,那么开始计算可信度的子集的最短长度为2,是不是就没有计算右端长度为1的情况,例如 f r e q s e t = 1 , 2 , 3 , H = [ 1 , 2 , 3 ] freqset = {1,2,3} ,H=[{1},{2},{3}] freqset=1,2,3,H=[1,2,3],那么进入rulesFromConseq函数后也没有计算 1 , 2 , 3 − > 1 {1,2,3} -> {1} 1,2,3−>1, 1 , 2 , 3 − > 2 {1,2,3} -> 2 1,2,3−>2, 1 , 2 , 3 − > 3 {1,2,3} -> 3 1,2,3−>3,直接就H拿去合并了
这个疑问想请各位大佬解答!
六、示例:发现毒蘑菇的相似特征
fr = open("mushroom.dat")
mushDateSet = [line.split() for line in fr.readlines()]
L,suppData = Apriori.apriori(mushDateSet,minSupport=0.3)
print(L[1])
for item in L[1]:
if(item.intersection('2')):
print(item)
解释一下这行代码:
item.intersection('2')
intersection的语法为:
set.intersection(set1,set2,...)
返回一个新集合,该集合的元素是set、set1、set2等集合的交集
那么回到那行代码,其意义就是:返回集合item和集合{“2”}的交集
如果item中有“2”,那么返回值就可以通过if的判断,那么就可以将其输出。