利用PyG实现图池化minCUT Pool(图分类任务)
文章目录
- 图池化
- 论文介绍
-
- 技术原理Spectral Clustering with GNNs
- 基于PyG实现图池化minCUT Pool
-
- 导入需要的包
- 数据集导入和处理
- ** *模型搭建* **
- 模型训练函数
- 模型测试函数
- 模型训练与测试
图池化
在我的理解,图池化就是利用聚类的方法,将强连通的节点簇进行合并,从而将图中的有效信息进行池化提取。也可以认为,利用一定的聚类方法,生成图的粗化版本。 池化在具有大量节点的数据集上更为有效,因为它可以有效地从大规模图形中提取有用的信息。
论文介绍
《Spectral Clustering with Graph Neural Networks for Graph Pooling》为2020年发表在国际机器学习大会ICML的论文。谱聚类(SC)是一种流行的聚类技术,用于在图上找到强连通的社区。SC可用于图形神经网络(GNN),以实现聚合属于同一集群的节点的池操作。然而,Sc的聚类方法基于拉普拉斯的特征分解,这在训练中是昂贵的,并且由于聚类结果是特定于图的,基于SC的池方法必须对新的样本执行新的优化。
而作者在本文中提出了一种可以在样本外的图上快速评估的聚类函数。根据所提出的聚类方法,作者设计了一个图池算子minCUT,并在有监督和无监督任务上都取得了极佳的性能。通俗来讲,作者提出的基于GNN的实现是可微分的,不需要计算频谱分解,并且学习了一个可以在样本外图上快速评估的聚类函数。
—————————————————————————————————————————
用本人的理解,作者的方法在实质上是将节点特征空间通过神经网络映射到了聚类分配空间。
—————————————————————————————————————————
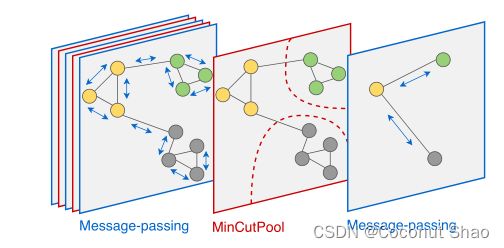
技术原理Spectral Clustering with GNNs
首先,作者对聚类问题进行了分解:
1、图拓扑——同一集群的节点直接应当互相具有强连接
2、节点特征——同一集群的节点应有类似的特征
作者的方法假设节点特征表示计算集群分配的良好初始化。**核心在于通过 集群(社区/簇)分配矩阵S 来计算出聚类(池化)后的邻接矩阵和特征(把每个簇融合成一个节点生成新的特征和邻接矩阵),然后可利用该邻接矩阵和特征进行下游任务。 通过多加 n 层 MinCutPool 即可实现 n 层的池化迭代。**总体结构图如下:
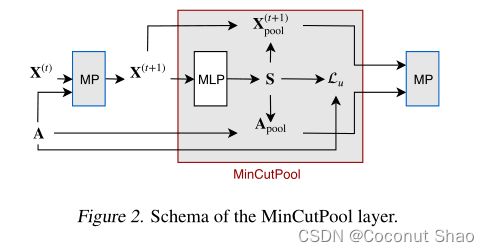
首先,设X为一个或多个MP层产生的节点表示矩阵。这里的X既拥有节点特征信息,也有拓扑信息。然后使用输出层具有softmax的多层感知器(MLP)计算节点的群集分配S(该感知器将每个节点特征xi映射到软群集分配矩阵S的第i行):
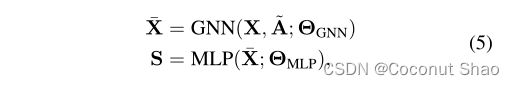
通过最小化由两个项组成的无监督损失函数Lu来联合优化上面GNN和MLP的参数。 左边的损失函数鼓励类间的节点尽可能的接近,右边则是鼓励类间正交且每个类具有相同数量的节点。

||F代表了Frobenius范数。
其中Lc用来对minCUT进行评估,取值范围为[-1,0]。最小化Lc会鼓励强连接节点聚集在一起。 当分子=0时,Lc取最大值0,如果对于每对连接的节点(即,aij>0),簇分配是正交的(即
然而,Lc是一个非凸函数,其最小化可能导致局部极小或退化解。例如,给定一个连通图,一个平凡但最优的解决方案是将所有节点分配给同一个集群。作为连续松弛的结果,所有节点都平等地分配给所有簇。MP操作加剧了这个问题,其平滑效果使节点特征更加均匀。
为了规避这种退化解,正交性损失项Lo鼓励簇分配是正交的,并且簇具有相似的大小。 由于Lo中的两个矩阵具有F范数,很容易看出0≤Lo≤ 2。因此,这两项可以安全地求和,而无需重新缩放它们,这样可以减少时间和空间成本。IK可以被解释为(重新缩放的)聚类矩阵ST与S矩阵相乘,其中S为每个聚类精确分配N/K个点。在2017年Deep spectral clustering learning聚论文中已经证明类矩阵之间的Frobenius范数值不受聚类大小差异的影响,因此可用于优化聚类内方差。
引用作者原文:虽然传统的SC需要计算每个新样本的谱分解,但在这里,聚类分配是由神经网络计算的,该神经网络学习从节点特征空间到聚类分配空间的映射。由于神经网络参数与图的大小无关, 并且由于GNN中的MP操作在节点空间中是局部化的,并且与拉普拉斯谱无关,因此所提出的聚类方法在推理时适用于未看到的图。
这也提供了在小图上训练我们的网络的机会,然后使用它来对较大的图进行聚类。
总体来说,minCUT就是利用集群分配矩阵S生成图的粗化版本,并对其池化的误差进行计算。
————————————————————————————————————————————
将每个簇结合成一个点,粗化后的邻接矩阵和集合顶点特征分别计算为:
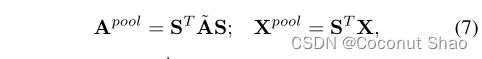
其中Apool为KxK的大小,可以看出将每个簇的节点融合为了一个节点并产生融合后的链接关系,其中aii代表簇中节点间边的权重加权和,aij代表簇i和簇j间的边加权和。Xpool为KxF,xij是i组元素中j特征的加权和,即代表每个簇内所有节点的特征融合为了一个特征。
Apool对应于计算损失时的Lc,tr’的max使其产生内部强链接,彼此弱链接的簇——对角占优的矩阵。但这也导致Apool自循环强,这会阻碍节点传播。我们对Apool进行对角线归零:

第二个归一化公式也是GNN中常见的处理方法。
用作者原文进行总结:通过联合优化Lu以及特定下游任务的任何监控损失,可以端到端地学习每个MinCutPool层的参数。与仅在正交矩阵空间内搜索可行解的SC方法相反,Lo只引入了在学习过程中可能部分违反的软约束。这使得GNN能够在Lu和监督损失之间找到最佳折衷,并使处理具有本质不平衡簇的图成为可能。
基于PyG实现图池化minCUT Pool
我们在选取数据集的时候,首先要注意选择多图数据集,而并非Cora这种单图数据集。池化针对的是图分类任务, 对于多图数据集(每个子图属于某一个类,一个图有一个标签),池化可以将每个子图的节点量不断缩小,最后坍缩成一个点来代表类别,与实际标签进行误差计算,并反向传播给参数更新,最后达到分类的任务效果。
而单图数据集的标签往往是与节点对应而不是与图对应, 每个节点有其自己的标签。如果对单图数据集做池化,会合并一部分节点,而这些节点往往具有不同的类别,那么合并后的节点将不再具有标签。
我们选择在PROTEINS数据集上进行论文优化部分的代码复现。PROTEINS数据集是蛋白质数据数据集,其中的1113个图表示蛋白质,图的标签分为2类,表示酶或者非酶.节点是蛋白质的二级结构,如果二级结构在氨基酸序列或者蛋白质三维空间中是邻居,那么节点之间有边存在。
通俗地讲,该数据集一共包含1113张无向图。PyG中PROTEINS数据集的具体的参数如下图:

在实现数据集引入和处理方面,本人主要使用了PyTorch Geometric这个库,这是我的大牛师兄推荐的一个比较简单的处理图问题的函数库,它的函数兼容性好并且操作相比于networkx较为简单(个人感觉哈),内置了大量数据集的自下载及其处理方式。具体介绍可以见官网:https://pytorch-geometric.readthedocs.io/en/latest/
导入需要的包
这里我们直接使用PyG内自带的GCN卷积核,这个类的输入为PyG格式的edge_index,而不需要提前转换成adj的邻接矩阵格式,可以说是数据集拿过来不用处理就可以做卷积,非常的便捷。
PyG中,DenseGraphConv可以对三个维度的图群进行卷积,这支持我们批量进行图卷积;dense_mincut_pool为PyG内置的minCUT层,返回的值为池化后的批量图节点特征矩阵,池化后的邻接矩阵,上面论文讲到的Lc和Lo。
它们的输入和输出在下面会进行具体的讲解。
from math import ceil
import torch
import torch.nn.functional as F
from torch.nn import Linear
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
from torch_geometric.nn import DenseGraphConv, GCNConv, dense_mincut_pool
from torch_geometric.utils import to_dense_adj, to_dense_batch
数据集导入和处理
我们选用PyG中内置的PROTEINS数据集,并对其进行训练集、测试集、验证集的划分。
第二行,我们计算出平均节点数量(由上面数据集图片可知为39)方便后面的维度计算。
第三行到第六行代码,我们将图进行了十等分,用于划分1113个图为训练、测试和数据(÷10代表划分8:1:1)。
最后,我们设置一次load20个图进行批量训练(神经网络通常以批量方式训练。PyG内置的DataLoader函数可以通过创建稀疏块对角邻接矩阵(由edge_index定义),并在节点维度上连接特征和目标矩阵,从而在小批量上实现并行化。这种组合允许在一个批次中的示例中有不同数量的节点和边)。
dataset = TUDataset(root='../tmp/PROTEINS', name='PROTEINS').shuffle()
average_nodes = int(dataset.data.x.size(0) / len(dataset))
n = (len(dataset) + 9) // 10
test_dataset = dataset[:n]
val_dataset = dataset[n:2 * n]
train_dataset = dataset[2 * n:]
test_loader = DataLoader(test_dataset, batch_size=20)
val_loader = DataLoader(val_dataset, batch_size=20)
train_loader = DataLoader(train_dataset, batch_size=20)
** 模型搭建 **
这里是本算法的核心部分,尤其要注意矩阵的维度,有利于模型的快速理解。
首先我们在初始化模型的同时按照论文设置了一系列卷积层、池化层和全连接层。由上面可以知道,平均节点数量为39,所以此处的num_nodes为20(第一处)和10(第二处)。
在调用该模型时,我们的输入有节点信息和边信息以及batch(尤其注意!这里的节点和边信息是20张图的)。我们假设输入的x有542个点,故x的尺寸为节点数x特征数542x3.
首先根据上面的论文,我们要先生成一个节点表示矩阵x并用x生成集群(社区/簇)分配矩阵s。minCUTPool可以利用他们生成图的粗化版本。 我们首先对输入的x经过一层图卷积(论文中为MLP,为了减少计算开销我们用一层线性层代替),得到节点表示矩阵x(由初始化卷积信息可得输出维度为32维,故x维度为542x32)。接着,我们对节点信息和边进行to_dense操作,使其转换由统一的节点和边矩阵转换为20个图的节点特征矩阵和邻接矩阵。 首先是对x进行to_dense操作,输出x为20x96x32,mask为20x96。x的20x96代表原本20个图中的542个点本来是集合的,现在转换在了各个图里,比如第一个96是第一个图的96个点,第二个96是第二个图的96个点。但是有的图的节点数比较少,这时就需要mask(里面由true和false构成)。比如,第10个图实际上只有40个点,但他的节点数维度为96,这时mask就会在对应维度用40个true和56个false来表示,这里的96个点只有40个有效。(这里的96可以理解为,这20个图中节点数最多的图有96个节点)同理,输出的adj邻接矩阵为20x96x96,代表了20个图分别的邻接矩阵。
转换完成后的x和adj都是具有三个维度,所有不可以使用只作用于二维矩阵的图卷积GCNConv进行卷积操作,后面的卷积都换成了DenseGraphConv。
我们对x进行全连接层操作得到集群分配矩阵s,由初始化的mlp1参数可得s的维度为20x96x20。然后我们将x,adj,s,mask带入PyG内置的minCUT Pool函数中,得到了池化后的节点特征矩阵x[20x20x32],邻接矩阵adj[20x20x20],以及返回的两个损失Lc和Lo。这表明minCUT Pool对20个图每个图的96个节点都池化为了20个节点,并且保持原有的特征维度32不变。即通过融合聚类后的节点生成了图的粗化版本。
然后我们再进行一次上述步骤,在第二次minCUT Pool池化后将20个点再次池化为10个点,特征矩阵x为[20x10x32],邻接矩阵adj[20x10x10],第二次的损失Lc和Lo。
然后我们需要根据池化后的特征,将每张图所属的类别(标签)预测出来。即每张图坍缩为一个点进行标签预测。 首先对x进行降维,通过mean函数对每个图的10个点求平均,使每个图具有32个特征。x此时维度为20x32。然后经过两层线性层即MLP进行概率预测,变为20x2,即输出每个图对应不同类别的概率(该数据集一共两个类别)。
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels, hidden_channels=32):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
num_nodes = ceil(0.5 * average_nodes)
self.mlp1 = Linear(hidden_channels, num_nodes)
self.conv2 = DenseGraphConv(hidden_channels, hidden_channels)
num_nodes = ceil(0.5 * num_nodes)
self.mlp2 = Linear(hidden_channels, num_nodes)
self.conv3 = DenseGraphConv(hidden_channels, hidden_channels)
self.lin1 = Linear(hidden_channels, hidden_channels)
self.lin2 = Linear(hidden_channels, out_channels)
def forward(self, x, edge_index, batch):
x = self.conv1(x, edge_index).relu()
x, mask = to_dense_batch(x, batch)
adj = to_dense_adj(edge_index, batch)
s = self.mlp1(x)
x, adj, mc1, o1 = dense_mincut_pool(x, adj, s, mask)
x = self.conv2(x, adj).relu()
s = self.mlp2(x)
x, adj, mc2, o2 = dense_mincut_pool(x, adj, s)
x = self.conv3(x, adj)
x = x.mean(dim=1) #20*32
x = self.lin1(x).relu()
x = self.lin2(x)
return F.log_softmax(x, dim=-1), mc1 + mc2, o1 + o2
模型训练函数
首先初始化模型参数和优化器。其次在训练函数中,每次使用20个图作为一个批量(batch)进行训练,得到输出的类别概率和Lc、Lo。将输出的类别概率和实际的标签带入nll_loss损失函数中计算误差并加上Lc(评估minCUT)和Lo(簇损失)作为整体的损失进行梯度求导和误差的反向传播 ,使模型中各个环节的参数进行更新。
每调用一次训练函数会对所有batch进行训练,即训练(所有图的数量/批量数batch)次。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net(dataset.num_features, dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4, weight_decay=1e-4)
def train(epoch):
model.train()
loss_all = 0
for data in train_loader:
data = data.to(device)
optimizer.zero_grad()
out, mc_loss, o_loss = model(data.x, data.edge_index, data.batch)
loss = F.nll_loss(out, data.y.view(-1)) + mc_loss + o_loss
loss.backward()
loss_all += data.y.size(0) * float(loss)
optimizer.step()
return loss_all / len(train_dataset)
模型测试函数
仍然是每次取一个批量20个图,并计算损失。但这里不进行误差的反向传播,因为是测试所以不需要梯度更新,而是直接使用预测概率中最大的值作为预测类别与实际的标签进行比较,观察在所有图上有多少图在训练后的分类正确——即用所有预测正确的图数量除以数据集所有图的数量。
@torch.no_grad()
def test(loader):
model.eval()
correct = 0
loss_all = 0
for data in loader:
data = data.to(device)
pred, mc_loss, o_loss = model(data.x, data.edge_index, data.batch)
loss = F.nll_loss(pred, data.y.view(-1)) + mc_loss + o_loss
loss_all += data.y.size(0) * float(loss)
correct += int(pred.max(dim=1)[1].eq(data.y.view(-1)).sum())
return loss_all / len(loader.dataset), correct / len(loader.dataset)
模型训练与测试
设置训练1000轮,每一轮依次调用训练函数进行训练,并在训练集上和验证集上进行精度测试。我们设置耐力系数为50,如果测试的损失小于目前已得到的最小损失,则说明此时的精度大于之前的精度,我们就在测试集上进行精度测试,获取在测试集上的精度(正确率)并重置耐力系数为50。 如果验证集的损失并没有大于目前已得到的最小损失,意味着测试的精度并没有大于目前已得到的最好精度,我们就没有必要在测试集进行测试了,而是对耐力系数进行减一。耐力系数50的作用即为确保如果50轮内没有更高的精度出现,即已经几乎达到最大精度了便停止训练,避免多余无用的训练。 比如在600——650这50轮内的训练始终没法进一步提高精度,便视为已经达到最高精度停止训练。
best_val_acc = test_acc = 0
best_val_loss = float('inf')
patience = start_patience = 50
for epoch in range(1, 1000):
train_loss = train(epoch)
_, train_acc = test(train_loader)
val_loss, val_acc = test(val_loader)
if val_loss < best_val_loss:
test_loss, test_acc = test(test_loader)
best_val_acc = val_acc
patience = start_patience
best_epoch = epoch
else:
patience -= 1
if patience == 0:
break
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.3f}, '
f'Train Acc: {train_acc:.3f}, Val Loss: {val_loss:.3f}, '
f'Val Acc: {val_acc:.3f}, Test Loss: {test_loss:.3f}, '
f'Test Acc: {test_acc:.3f}')
print(f'The Best Epoch: {best_epoch:03d},Test Loss: {test_loss:.3f}, Test Acc: {test_acc:.3f}')
输出结果部分截图为:

证明具有minCUT Pool的模型可以在较短时间内达到很高的精度。