Redis-day4-哨兵监控Redis主从
文章目录
-
- 哨兵监控Redis主从
-
- 1.介绍
- 2.作用
- 3.工作方式
- 4.主从部署
-
- 1)准备主从环境
- 2)安装Redis
- 3)做主从
-
- 1> 修改端口号
- 2> 添加systemd管理
- 3> 添加到环境变量
- 4> 检测主从状态
- 4)启用连接主从
-
- 1> node1加入到master
- 2> node2加入到master
- 3> 主节点查看
- 5.哨兵部署
-
- 1)配置文件详解
- 2)配置哨兵
- 3)启动哨兵
- 4)故障转移
-
- 1> 查看当前节点信息
- 2> 干掉master节点
- 3> 复活master节点
- 6.三个定时任务
- 7.主观下线与客观下线
哨兵监控Redis主从
1.介绍
哨兵(sentinel),用于对主从结构中的每一台服务器进行监控,当主节点出现故障后,通过投票机制来挑选新的主节点,并且将所有的从节点连接到新的主节点上;前面的“主从”是提升 Redis 服务器稳定性的一种最基础的实现方式,但我们可以看到 master 节点仍然是一台,若主节点宕机,所有从服务器都不会有新的数据进来,如何让主节点也实现高可用,当主节点宕机的时候自动从从节点中选举一台节点提升为主节点就是哨兵实现的功能。
2.作用
- **监控:**监控主从节点运行情况。
- **通知:**当监控节点出现故障,哨兵之间进行通讯。
- **自动故障转移:**当监控到主节点宕机后,断开与宕机主节点连接的所有从节点,然后在从节点中以投票机制选取一个节点,作为主节点,将其他的从节点连接到这个最新的主节点,最后通知客户端最新的服务器地址。
3.工作方式
- 每个 Sentinel(哨兵) 以每秒钟一次的频率向它所知的 Master,Slave 以及其他 Sentinel 实例发送一个 ping 命令。
- 如果一个instance(实例)距离最后一次有效回复 ping 命令的时间超过 own-after-milliseconds 选项所指定 的值,则这个实例会被 Sentinel 标记为主观下线。
- 如果一个 Master 被标记为主观下线,则正在监视这个 Master 的所有 Sentinel 要以每秒一次的频率确认 Master 是否真的进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的限上限值)在指定的时间范围内确认 Master 的确进入了主观下 线状态,则 Master 会被标记为客观下线。
- 在一般情况下,每个 Sentinel 会以每 10 秒一次的频率向它已知的所有 Master、Slave 发送 info 命令。
- 当 Master 被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 info 命令的频率,会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel 同意 Master 已经下线,Master 的客观下线状态就会被移除。 若 Master 重新向Sentinel 的 ping 命令返回有效回复,Master 的主观下线状态就会被移除。
4.主从部署
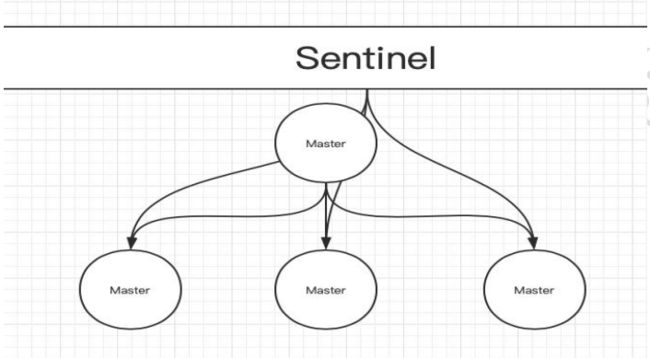
- 基于配置了Redis主从的基础上,部署哨兵
1)准备主从环境
| 主机 | IP | 主从角色 | 哨兵角色 |
|---|---|---|---|
| K8s-master1 | 192.168.12.11 | master、 | |
| K8s-node1 | 192.168.12.12 | slave | |
| K8s-node2 | 192.168.12.13 | slave |
2)安装Redis
- 所有节点执行
# 下载解压
wget https://download.redis.io/releases/redis-6.0.9.tar.gz
tar -xf redis-6.0.9.tar.gz -C /usr/local/
cd redis-6.0.9
# 安装依赖
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# 切换到 gcc7 版本
scl enable devtoolset-9 bash
# 编译安装、制作启动目录
make && make PREFIX=/usr/local/redis install
# 启动Redis(此时已生成redis目录)
/usr/local/redis/bin/redis-server
3)做主从
- 配置三节点配置文件(除了端口号不同,其余两条配置要一样)
- 更改端口为从节点对应的端口号
1> 修改端口号
- bind配置连接参考 https://my.oschina.net/u/4351575/blog/4133976
- 所有节点修改端口号,其余修改内容如下一样
- master1:6379
- node1:6381
- node2:6382
vim /usr/local/redis-6.0.9/redis.conf
port 6379 # 端口号
aclfile "/usr/local/redis/conf/users.aclfile" # 注释此行,避免从节点加入主节点时出现 down 问题
"user default on nopass ~* +@all" # 删除配置文件内提交过的密码行(一般在行末)
bind 0.0.0.0 # 0或注释掉则代表允许所有外来连接,若在本机测试则用127.0.0.1
2> 添加systemd管理
- 每台机器各准备一份,只是端口号不同
cat /usr/lib/systemd/system/redis.service
[Unit]
Description=Redis
After=network.target
[Service]
Type=forking
PIDFile=/var/run/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis-6.0.9/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
EXECStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
3> 添加到环境变量
方式一:推荐
# Redis
export PATH=$PATH:/usr/local/redis/bin
方式二:
# Redis
export REDIS_HOME=/usr/local/redis
PATH=$PATH:$REDIS_HOME/bin
4> 检测主从状态
# 重载、启动
systemctl reload
systemctl start redis
# 查看状态
[root@k8s-master1 ~]# netstat -lntp|grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 102260/redis-server
[root@k8s-node1 ~]# netstat -lntp|grep redis
tcp 0 0 192.168.12.12:6381 0.0.0.0:* LISTEN 102266/redis-server
[root@k8s-node2 ~]# netstat -lntp|grep redis
tcp 0 0 192.168.12.13:6382 0.0.0.0:* LISTEN 102272/redis-server
4)启用连接主从
- 修改redis.conf监听bind地址为主节点IP
- 加入到主节点
1> node1加入到master
127.0.0.1:6381> slave 192.168.12.11 6379
127.0.0.1:6381> info replication
master_link_status:up # up即为成功
2> node2加入到master
127.0.0.1:6382> slave 192.168.12.11 6379
127.0.0.1:6382> info replication
master_link_status:up # up即为成功
3> 主节点查看
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 # 已加入两台从节点
slave0:ip=127.0.0.1,port=6381,state=online,offset=1218,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=1218,lag=0
5.哨兵部署
基于上面的主从配置,可以配备哨兵来监控主从的状态
1)配置文件详解
Sentinel.conf 配置文件主要参数解析
# 端口
port 26379
# 是否后台启动
daemonize yes
# pid 文件路径
pidfile /var/run/redis-sentinel.pid
# 日志文件路径
logfile "/var/log/sentinel.log"
# 定义工作目录
dir /tmp
# 定义 Redis 主的别名, IP, 端口,这里的 2 指的是需要至少 2 个 Sentinel 认为主 Redis 挂了才最终会
采取下一步行为
# sentinel monitor [集群名称] [集群主节点 IP] [断开] [至少挂了从节点的个数]
sentinel monitor mymaster 127.0.0.1 6379 2
# 如果 mymaster 30 秒内没有响应,则认为其主观失效
sentinel down-after-milliseconds mymaster 30000
# 如果 master 重新选出来后,其它 slave 节点能同时并行从新 master 同步数据的台数有多少个,显然该值
越大,所有 slave 节点完成同步切换的整体速度越快,但如果此时正好有人在访问这些 slave,可能造成读取
失败,影响面会更广。最保守的设置为 1,同一时间,只能有一台干这件事,这样其它 slave 还能继续服务,
但是所有 slave 全部完成缓存更新同步的进程将变慢。
sentinel parallel-syncs mymaster 1
# 该参数指定一个时间段,在该时间段内没有实现故障转移成功,则会再一次发起故障转移的操作,单位毫秒
sentinel failover-timeout mymaster 180000
# 不允许使用 SENTINEL SET 设置 notification-script 和 client-reconfig-script。
sentinel deny-scripts-reconfig yes
[root@alvin-test-os sentinel]# grep -Ev "^$|#" sentinel26379.conf
2)配置哨兵
- 主节点master1:sentinel-26379.conf,IP指定为127本地回环
- 从节点node:IP指定为主节点的IP
cat > /usr/local/redis-6.0.9/sentinel-26379.conf <<EOF
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "/var/log/sentinel-26379.log"
dir "/tmp"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 2000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
EOF
- slave从节点node1:sentinel-26379.conf
cat > /usr/local/redis-6.0.9/sentinel-26381.conf <<EOF
port 26381
daemonize yes
pidfile "/var/run/redis-sentinel-26381.pid"
logfile "/var/log/sentinel-26379.log"
dir "/tmp"
sentinel monitor mymaster 192.168.12.11 6379 2
sentinel down-after-milliseconds mymaster 2000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
EOF
- slave从节点node2:sentinel-26379.conf
cat > /usr/local/redis-6.0.9/sentinel-26382.conf <<EOF
port 26382
daemonize yes
pidfile "/var/run/redis-sentinel-26382.pid"
logfile "/var/log/sentinel-26379.log"
dir "/tmp"
sentinel monitor mymaster 192.168.12.11 6379 2
sentinel down-after-milliseconds mymaster 2000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
EOF
3)启动哨兵
[root@k8s-master1 ~]# /usr/local/redis/bin/redis-sentinel /usr/local/redis-6.0.9/sentinel-26379.conf
[root@k8s-node1 ~]# /usr/local/redis/bin/redis-sentinel /usr/local/redis-6.0.9/sentinel-26381.conf
[root@k8s-node2 ~]# /usr/local/redis/bin/redis-sentinel /usr/local/redis-6.0.9/sentinel-26381.conf
# 查看启动
[root@k8s-master1 ~]# netstat -lntp|grep redis-sentine
tcp6 0 0 :::26379 :::* LISTEN 92468/redis-sentine
[root@k8s-node1 ~]# netstat -lntp|grep redis-sentine
tcp6 0 0 :::26381 :::* LISTEN 92557/redis-sentine
[root@k8s-node2 ~]# netstat -lntp|grep redis-sentine
tcp6 0 0 :::26382 :::* LISTEN 92578/redis-sentine
# 哨兵可通过独有端口进入查看加入状态,有runid说明已成功加入
[root@k8s-master1 ~]# redis-cli -p 26379
127.0.0.1:26379> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "0b96e4aefa4d2bb8978a9f443b5a08fa710e7ea3"
9) "flags"
10) "master"
4)故障转移
- 测试干掉主节点后,会不会自动切换主节点
1> 查看当前节点信息
- 可以看到,当前master为主节点,其余两个node为从节点
1.node1
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
2.node2
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
3.master1
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=190983,lag=1
slave1:ip=127.0.0.1,port=6382,state=online,offset=190983,lag=0
2> 干掉master节点
[root@k8s-master1 ~]# ps -elf | grep redis | grep 6379
5 S root 65578 00:00:09 /usr/local/redis/bin/redis-server 127.0.0.1:6379
5 S root 96909 00:00:05 /usr/local/redis/bin/redis-sentinel *:26379 [sentinel]
4 S polkitd 101652 00:00:51 redis-server *:6379
[root@k8s-master1 ~]# kill -9 65578
# 监控日志
[root@k8s-master1 ~]# tailf /var/log/sentinel-26379.log
# 被标记为主管下线
96909:X 07 May 2021 14:27:46.872 # +sdown master mymaster 127.0.0.1 6379
# 以达到两个,被标记为客观下线
96976:X 07 May 2021 14:27:46.882 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2
# 从节点依次对master 6379 进行状态探测
# 81 开始探测 79
96976:X 07 May 2021 14:27:47.952 # +promoted-slave slave 192.168.12.12 6381 @ mymaster 127.0.0.1 6379
96976:X 07 May 2021 14:27:47.952 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
# 82 开始探测 79
96976:X 07 May 2021 14:27:48.045 * +slave-reconf-sent slave 192.168.12.13 @ mymaster 127.0.0.1 6379
# 配置更新哨兵,探测失败选取新的主节点
96950:X 07 May 2021 14:27:48.046 # +config-update-from sentinel fafb1db42e030a147a64cfa051c9d2d0ad732b74 192.168.12.13 26382 @ mymaster 127.0.0.1 6379
# 选择新的master为6381
96976:X 07 May 2021 14:27:49.014 # +switch-master mymaster 127.0.0.1 6379 192.168.12.12 6381
# 将两个其他节点加入集群
# 将 node1 加入,成功
96976:X 07 May 2021 14:27:49.014 * +slave slave 192.168.12.12 @ mymaster 127.0.0.1 6381
# 将原master1加入,失败(已被杀死)
96976:X 07 May 2021 14:27:49.014 * +slave slave 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
# 将原master1下线
96909:X 07 May 2021 14:27:50.087 # +sdown slave 127.0.0.1:6379 @ mymaster 127.0.0.1 6381
3> 复活master节点
- 干掉master之后,哨兵会自动以投票的方式选取新的主节点,且将其他节点加入进来。
- 复活master后,会自动加入到新的master节点,且已变为从节点,故障转移成功!
# 启动
[root@k8s-master1 ~]# /usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
# 此时已变成slave节点,master节点为 6381
[root@k8s-master1 ~]# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
master_link_status:up
# 查看日志,已将6379加入到6381内
96909:X 07 May 2021 14:54:54.988 * +reboot slave 127.0.0.1:6379 @ mymaster 127.0.0.1 6381
96909:X 07 May 2021 14:54:54.988 * +convert-to-slave slave 127.0.0.1:6379 @ mymaster 127.0.0.1 6381
96909:X 07 May 2021 14:54:55.078 # -sdown slave 1127.0.0.1:6379 @ mymaster 127.0.0.1 6381
6.三个定时任务
- 每 10 秒每个 sentinel 会对 master 和 slave 执行 info 命令,这个任务达到两个目的: a) 发现 slave 节点 b) 确认主从关系
- 每 2 秒每个 sentinel 通过 master 节点的 channel 交换信息(pub/sub)。master 节点上有一个发布订阅的频 道(sentinel:hello)。sentinel 节点通过__sentinel__:hello 频道进行信息交换(对节点的"看法"和自身的信息), 达成共识。
- 每 1 秒每个 sentinel 对其他 sentinel 和 redis 节点执行 ping 操作(相互监控),这个其实是一个心跳检测, 是失败判定的依据
subscribe __sentinel__:hello # 自动不停探测
127.0.0.1:6381> subscribe __sentinel__:hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__sentinel__:hello"
3) (integer) 1
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26379,15e395ba9eb7854f4d4546993ec46feb518467b6,6,mymaster,127.0.0.1,6379,6"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26379,15e395ba9eb7854f4d4546993ec46feb518467b6,6,mymaster,127.0.0.1,6379,6"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26382,fafb1db42e030a147a64cfa051c9d2d0ad732b74,6,mymaster,127.0.0.1,6379,6"
1) "message"
···
7.主观下线与客观下线
- 主观下线
指的是单个 Sentinel 实例对服务器做出的下线判断,即单个 sentinel 认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。
-
客观下线
指的是多个 Sentinel 实例对服务器做出的下线判断,判断确认后,会将此服务器下线。