PyTorch深度学习(28)视觉图像分割、检测、超分
视觉图像分割 Image Segmentation
时间序列 Informer 之前的时间信息/任务 LSTM RNN Transformer
图像分割:在原始图像中逐像素找到指定物体
对每个像素点二分类(做分类任务) 归属类别
图像检测:框选 预测坐标值
分割任务:逐像素点分类任务 对每个点做分类 如:人、天、草地、树 四分类
各个类别概率,属于哪个类型就用哪个颜色显示
语义分割
每个像素都打上标签,只区分类别,不区分类别中具体单位(只分大类,部分小类)
损失函数
惩罚——做什么是对的,什么是错了 衡量
逐像素交叉熵——希望将每个像素点都判断对
考虑样本均衡问题
MIOU指标
IoU(Intersection over Union,交并比)
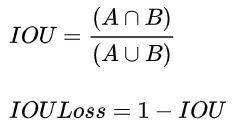
MIOU计算所有类别的平均值,一般当作分割任务评估指标 I/U I交集 U并集
U-Net
整体结构
编码解码过程 编码器:图像转特征 解码器:融合特征得到输出结果
简单使用应用广,最初是做医学方向
例如:输入图像有飞机、人、花、树四个类别,图像大小224×224×3
输出 224×224×4 是为了得到每个像素点的类别概率
每个点做类别的判断
上采样:插值(最近邻插值、线性插值、双线性插值、双三次插值高阶插值)、反卷积
特征拼接操作
U-Net++
拼接、多监督(不同位置增加损失函数)
特征融合,拼接更全面
与densenet思想一致
把能拼能凑的特征全用的升级版
Deep Supervision
多输出
损失由多个位置计算,再更新 多个中间位置增加损失函数
细胞数据、标签
[4, 3, 96, 96] 一次训练4张图,RGB通道数为3,高96, 宽96
实例分割
不光区分类别,还要区分类别中每一个个体(即分大类,也分小类)
行为识别
具体内容
针对视频
按照帧切为序列,每块100帧
采环境的特征,每25帧取一次,共4张
采动作的特征,每隔2帧提取,共50张
3D卷积——提特征——汇总分类任务——类别中是哪一个
判断人在干什么,做的事是类别中的一个事情
当前人的动作、环境
slowfast——动作fast、环境slow
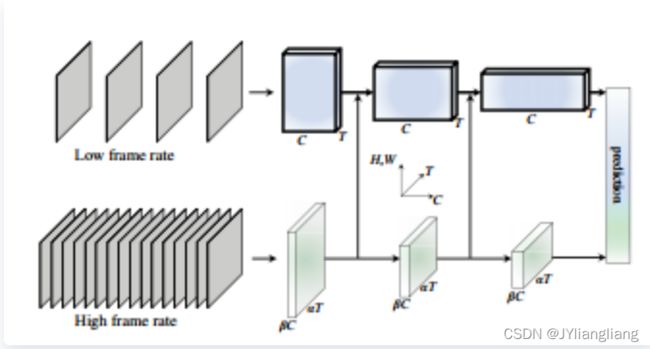
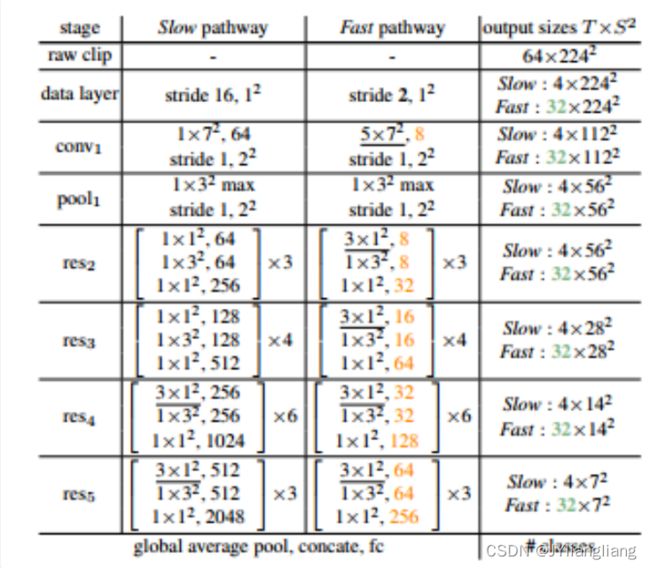
通用的行为识别框架(facebook),适用高频与低频特征,直接融合特征进行预测
基本思想:
- 动作在变,环境不变
- 如何获取动作信息
- 如何获取环境信息
- 如何融合
核心网络结构
- 分别获取高频与低频图像数据
- 分别进行特征提取
- 特征融合
- 预测
目标检测 Object Detection
内容
图像检测:框选 预测坐标值
定位,找到目标所在的位置
应用领域
DETR(Detection Transformer)目标检测,框选——边界特征重要
YOLO
optimal speed and accuracy of object Detection
本质思想:集百家之长,简化百家 速度块,准确率不高
贡献:
- 单GPU就能训练非常好,很多小模块都是以此为出发点
- 两大核心:从数据层面和网络设计层面来进行改善
- 消融实验:工作量大
- 全部实验都是单GPU训练



Bag of freebies(BOF)
- 只增加训练成本,但能显著提高精度,并不影响推理速度
- 数据增强:调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转
- 网络正则化的方法:Dropout、Dropblock等
- 类别不平衡,损失函数设计
Mosaic data augmentation 马赛克数据增强
- 参考CutMix,四张图像拼接成一张进行训练
- 简介增加batch
- 难点:确定中心点、拼接、标签 转换
数据增强
- Random Erase:用随机值或训练集的平均像素值替换图像的区域
- Hide and Seek:根据概率设置随机隐藏一些补丁
- Self-adversarial-training(SAT):通过引入噪音点来增加游戏难度
- Dropout 训练过程中,随机隐藏一些特征,能够识别
- DropBlock Dropout是随机选择点(b),现在隐藏多个区域
算法:快速理解——看源码
Label Smoothing 标签平滑
- 神经网络最大缺点:过拟合(觉得训练很好)
- 例如原来标签为(0, 1):[0,1]×(1-0.1)+0.1/2=[0.05,0.95]


BOS(Bag of specials)
- 增加稍许推断代价,但可以提高模型精度的方法
- 网络细节部分加入很多改进,引入了各种能让特征提取更好的方法
- 注意力机制,网络细节设置,特征金字塔等
目标检测回归损失函数
参考:目标检测回归损失函数——IOU、GIOU、DIOU、CIOU、EIOU - 知乎
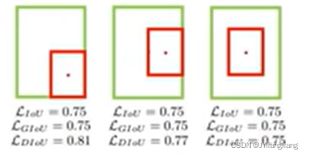
IOU Loss:没有相交则IOU=0无法梯度计算,相同的IOU却反映不出实际情况

GIOU Loss:引入了最小封闭形状C(C可以把A, B包含在内)
针对IOU Loss缺点:
- 无法优化两个框不相交的情况
- 无法反映两个框如何相交的

引入了最小封闭形状C(C可以把A,B包含在内),在不重叠情况下能让预测框尽可能朝着真实框前进
存在问题:
GIOU仍然严重依赖IOU,因此在两个垂直方向,误差很大,基本很难收敛,这就是GIoU不稳定的原因。
DIOU Loss
- DIOU与IOU、GIOU一样具有尺度不变性;
- DIOU与GIOU一样在与目标框不重叠时,仍然可以为边界框提供移动方向;
- DIOU可以直接最小化两个目标框的距离,因此比GIOU Loss收敛快得多;
- DIOU在包含两个框水平/垂直方向上的情况回归很快,而GIOU几乎退化为IOU;

其中分子计算预测框与真实框的中心点欧式距离d,分母是能覆盖预测框与真实框的最小Box的对角线长度c,直接优化距离,速度更快,并解决GIOU的问题
存在问题:
虽然DIOU能够直接最小化预测框和真实框的中心点距离加速收敛,但是Bounding box的回归还有一个重要的因素纵横比暂未考虑。
CIOU Loss
CIOU在DIOU的基础上将Bounding box的纵横比考虑进损失函数中,进一步提升了回归精度。
CIOU的惩罚项是在DIOU的惩罚项基础上加了一个影响因子αv,这个因子把预测框纵横比拟合真实框的纵横比考虑进去。惩罚项公式如下:

损失函数必须考虑三个几何因素:重叠面积、中心点距离、长宽比
其中α可以当作权重参数

存在问题:
纵横比权重的设计还不太明白,是否有更好的设计方式有待更新。
ELOU Loss
CIOU Loss虽然考虑了边界框回归的重叠面积、中心点距离、纵横比。但是通过其公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性。针对这一问题,有学者在CIOU的基础上将纵横比拆开,提出了EIOU Loss,并且加入Focal聚焦优质的锚框


存在问题:
针对边界框回归任务,在之前基于CIOU损失的基础上提出了两个优化方法:
- 将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度;
- 引入了Focal Loss优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对BBox 回归的优化贡献,使回归过程专注于高质量锚框。
不足之处或许在于Focal的表达形式是否有待改进。
DIOU-NMS损失
之前使用NMS来决定是否删除一个框,现在改用DIOU-NMS

SOFT-NMS

目标检测网络结构
SPPNet(Spatial Pyramid Pooling)
三个不同池化层,结果拼接 特征多样性(每条路径将自己的特征提取好后汇总)
- V3中为了更好满足不同输入大小,训练的时候要改变输入数据的大小
- SPP其实就是用最大池化来满足最终输入特征一致即可

CSPNet(Cross Stage Partial Network)
保留一半,剩下一半进行卷积;每一个block按照特征图的channel维度拆分成两部分
一份正常走网络,另一份直接concat到这个block的输出

CBAM
加入注意力机制 某些点权重较大 算出来的权重乘上当前点的特征得到实际的特征
V4中用SAM,空间注意力机制



空间注意力机制 速度相对更快 SAM


PAN(Path Aggregation Network)
自顶向下模式,将高层特征传下来

注意力机制:关注边界多或中心多;高度遮蔽、重叠
超分辨率 Super Resolution
基于深度学习的图像超分辨率重建
将低分辨率图像——>高分辨率图像
Deep Learning for Image Super-resolution: A Survey
- 基于插值的技术
- 最近邻元法
- 双线性内插法
- 三次内插法
基于重建的方法
概率论/集合论
- 凸集投影法(POCS)
- 贝叶斯分析方法
- 迭代反投影法(IBP)
- 后验概率方法
- 正规化法
- 混合方法
基于机器学习的方法(非深度学习)
- Example-based方法
- 领域嵌入方法
- 支持向量回归方法
- 稀疏表示法
监督学习的问题
原图 → 缩小 → 缩小图 → 通过模型重建 → 重建图 → 对比后调整模型 → 原图
I^y=F(Ix;θ) Ix低清图像 Iy超分图像 F超分模型 θ模型中参数
模型的学习目标
θ=argminθL(I^y, Iy)+λΦ(θ) L损失函数 Φ(θ)为正则项 λ为惩罚系数
图像处理
获得低分辨率图像
Ix=D(Iy;δ) D表示降级映射 δ为模型中参数
降级模型——简单下采样 Ix=(Iy)⬇s s表示下采样的倍数、
加入模糊与噪声的下采样Ix=(Iy卷积k)⬇s+n k为卷积核,n为噪声
影响图像因素:散焦、压缩失真、噪点、传感器噪声
评价超分图像的质量
- 客观:峰值信噪比、结构相似度
- 结构相似度:亮度Luminance+对比度Contrast+结构Structure(均值、方差、相关性)
- 主观:意见平均分
超分网络的结构分类
1、预上采样:低尺寸--upsample--目标尺寸--经过一系列卷积--输出图像
SRCNN
无需考虑输入图像和输出图像尺寸不匹配问题
缺点:在高维中计算,增加计算复杂度;产生虚假纹理,干扰训练
2、后上采样
低尺寸图像--经过一系列卷积--upsample--输出图像
降低计算复杂
缺点:过多信息缺失,不能适应不同放大倍数
3、逐步上采样
低尺寸图像--多个模块(每个模块包含:一系列卷积和upsample)--输出图像
降低学习难度,兼容放大倍数
缺点:训练难度较高
4、交替式上下采样
挖掘低清晰和高清晰图像的依赖关系
低尺寸图像--卷积--upsample downsample--......--upsample--输出图像
各种深度学习模型应用于SR
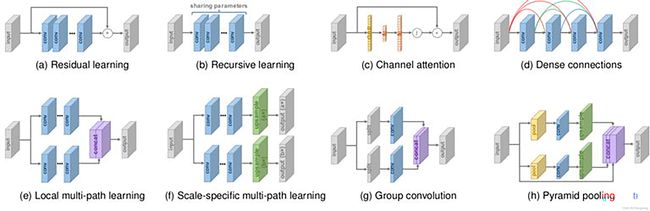
其他
图像复原 Image Restoration
图像增强 Image Enhancement
图像重建 Image Reconstruction
三维重建 3D Reconstruction
无人驾驶:点云 Point Cloud
无人驾驶需考虑周围物体