pytorch入门学习笔记
pytorch入门学习笔记一
-
- 前述
- 一些函数
- 正式建立一个神经网络
-
- 直接用numpy写
- 改成pytorch形式
- 创建Tensor操作
- pytorch维度变换操作
-
- View & reshape
- Squeeze & unsqueeze
- Expand
- repeat
- 矩阵的转置
- Broadcasting(自动扩展)
- 拼接与拆分
- 基本运算
- 统计属性
-
- 求范数
- 返回最大元素的索引
- 返回top-k的元素
- 求第k小的元素
- where 语句与condition
- gather查表语句
- Loss的梯度
- Visdom可视化工具的使用
- Regularization
- 学习率衰减
- Early Stopping, Dropout
- 实现二维卷积神经网络
- 池化层与采样
- nn.Module
-
- save and load
- 自定义数据集处理
-
- Step1:Load data
- LSTM的使用
前述
在这里我省略了安装anacanda和pytorch的过程,直接默认我们已经配置好了环境,如果没有配置好环境的,可以参考b站视频:
B站pytorch深度学习入门(环境配置)
其中还涉及到一些从清华镜像网站下载package的过程,为了加快速度,具体参考博客:
Anaconda清华镜像源的使用及安装Pytorch失败问题解决
所以接下来,直接进入pytorch的正式学习。
在这里还要推荐一个B站的外翻系列视频(字幕凑合看着吧)
2019高效入门pytorch视频教程【字幕版】
pytorch 入门学习
一些函数
numpy ndarray是一个普通的n维array,它不知道任何关于深度学习或者梯度的知识,也不知道计算图(computation graph),只是一种用来计算数学运算的数据结构。
import torch
torch.cuda.is_avaliable()
去确认我们的cuda工具包是否支持我们的NVIDIA的GPU进行计算or训练,如果返回true证明可以。
numpy.random.rand(d0,d1,d2,…,dn)
- rand函数会根据给定维度生成[0,1)之间的数据,包含0,不包含1
- dn中的是维度
- 返回值为指定维度的array
numpy.random.randn(d0,d1,d2,…,dn)
- randn函数返回的是具有标准正态分布的一组样本
- dn中的是维度
- 返回值为指定维度的array
numpy中的arange()函数:
numpy.arange(start, stop, step, dtype = None)
- start:开始位置,默认为0
- stop:结束位置(结束位置的那个数不包含在内)
- step:步长
- dtype:输出数组类型,如果未给出,则根据其他输入判断数据类型
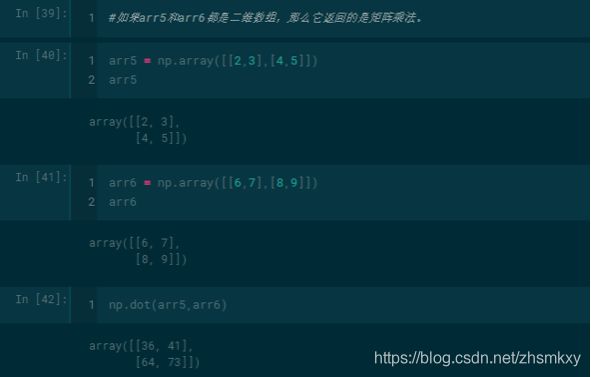
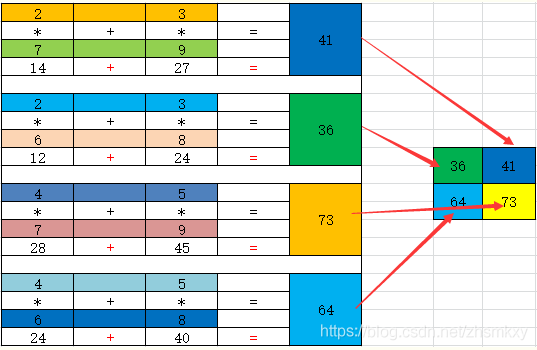
numpy库中的dot()函数
- 一维数组的dot函数运算:


- 二维数组矩阵之间的dot函数运算得到的乘积是矩阵乘积
正式建立一个神经网络
直接用numpy写
import torch
import numpy as np
#用numpy构建两层神经网络
N,D_in,H,D_out=64,1000,100,10
# 随机创建一些训练数据
x=np.random.randn(N,D_in)
y=np.random.randn(N,D_out)
w1=np.random.randn(D_in,H)
w2=np.random.randn(H,D_out)
learning_rate=1e-6
for t in range(500):
# forward pass
h=x.dot(w1) # N*H x.dot(w1)=x*w1
h_relu=np.maximum(h,0) #N*H the definition of relu function
y_pred=h_relu.dot(w2) #N*D_out
#computer loss
loss=np.square(y_pred-y).sum()
print(t,loss)
#backward pass
grad_y_pred=2.0*(y_pred-y)
grad_w2=h_relu.T.dot(grad_y_pred)
grad_h_relu=grad_y_pred.dot(w2.T)
grad_h=grad_h_relu.copy()
grad_h[h<0]=0
grad_w1=x.T.dot(grad_h)
#compute the gradient
w1-=learning_rate*grad_w1
w2-=learning_rate*grad_w2
#update weight of w1 and w2
对代码的解读:
上面是最基础的一个两层的神经网络,该神经网络为了简便,舍去了bias项。我们第一层的w1的维数是(D_in,H),在这个例子中就是(1000,100),把一个1000维的输入变成一个100维的,h_relu可以理解为x2,w2的维数是(H,D_out),在这个例子中就是(100,10),把一个100维的输入变成一个10维的输入。然后N=64就是说我们有64个训练数据,这64个训练数据作为一个batch块一同输入到网络中。网络的loss用的是L2损失,这没什么好说的。其次就是在某些地方的转置上,比如grad_w2=h_relu.T.dot(grad_y_pred),h_relu是(64,100),grad_y_pred是(64,10),因为grad_w2要和w2的维数一样,才能进行update weight,所以h_relu得转置一下,才能和grad_y_pred相乘。剩下的grad_h_relu=grad_y_pred.dot(w2.T)也是一样的道理。但这里又变成grad_y_pred*w2.T所以还需要注意一下顺序。relu函数的local gradient,如果输入大于0,则为1,如果小于则为0。

运行结果可以看出最后收敛了,接下来我们把numpy写的函数改成用pytorch写的函数。
改成pytorch形式
import torch
import numpy as np
#用numpy构建两层神经网络
N,D_in,H,D_out=64,1000,100,10
# 随机创建一些训练数据
x=torch.randn(N,D_in)
y=torch.randn(N,D_out)
w1=torch.randn(D_in,H)
w2=torch.randn(H,D_out)
learning_rate=1e-6
for t in range(500):
# forward pass
h=x.mm(w1) # N*H x.dot(w1)=x*w1
h_relu=h.clamp(min=0) #N*H the definition of relu function
y_pred=h_relu.mm(w2) #N*D_out
#computer loss
loss=(y_pred-y).pow(2).sum().item()
print(t,loss)
#backward pass
grad_y_pred=2.0*(y_pred-y)
grad_w2=h_relu.t().mm(grad_y_pred)
grad_h_relu=grad_y_pred.mm(w2.t())
grad_h=grad_h_relu.clone()
grad_h[h<0]=0
grad_w1=x.t().mm(grad_h)
#compute the gradient
w1-=learning_rate*grad_w1
w2-=learning_rate*grad_w2
#update weight of w1 and w2
注解:
- np.random…randn要改成torch.randn
- .dot()要改成.mm() matrix multiplication
- np.maximum要改成h.clamp (clamp函数是将input张量的每个元素压缩到[min max],并返回结果到一个新张量)
- .T的转置要改为.t()
- .copy()要改成.clone()
创建Tensor操作
注意torch中在创建tensor时,一般有两种表达形式torch.tensor()和torch.Tensor(),第二项包扣torch.FloatTensor()等。
# 针对torch.tensor的几点说明
# 如果要创建一个标量,例如标量1
a=torch.tensor(1) #a.shape torch.size([])
b=torch.tensor((1)) #b.shape torch.size([])
# torch.tensor一般传入的是数据,而不是尺寸
c=torch.tensor([1]) #c.shape torch.size([1]) 此时c就是一个向量了 c.dim()为1,但与此同时a.dim和b.dim都为0
#针对torch.Tensor的几点说明
#torch.Tensor一般传入的是尺寸,()中不用加括号,直接写dim ,比如(d1,d2,d3)
d=torch.tensor(1) #意思是随机创建一个dim为1的tensor,此时d.shape为torch.size([1])
综上,一般用torch.tensor创建标量以及传入具体数据以转换成tensor。一般用torch.Tensor创建任意尺寸的tensor
pytorch维度变换操作
View & reshape
pytorch以前的维度变换函数就是View,但是后来为了numpy对应起来,才增加了reshape函数。
a=torch.rand(4,1,28,28)
tensor([[0.8738, 0.0485, 0.1898, ..., 0.1908, 0.9856, 0.0528],
[0.7603, 0.1995, 0.2293, ..., 0.2763, 0.3755, 0.5434],
[0.1683, 0.6585, 0.8554, ..., 0.5000, 0.8116, 0.5478],
[0.8665, 0.0071, 0.9416, ..., 0.8682, 0.1769, 0.0599]])
a.view(4*28,28).shape
torch.Size([112, 28])
a.view(4*1,28,28).shape
torch.Size([4, 28, 28])
b=a.view(4,784)
b.view(4,28,28,1) #logic Bug
数据的存储/维度顺序非常重要,需要时刻记住
(4,1,28,28)≠(4,28,28,1)
Squeeze & unsqueeze
a.shape #torch.Size([4,1,28,28])
a.unsqueeze(0).shape #torch.Size([1,4,1,28,28])
a.unsqueeze(-1).shape #torch.Size([4,1,28,28,1])
a.unsqueeze(4).shape #torch.Size([4,1,28,28,1])
a=torch.tensor([1.2,2.3]) #torch.Size([2])
a.unsqueeze(-1) #torch.Size([2,1])
a.unsqueeze(0) #torch.Size([1,2])
b=torch.rand(32)
f=torch.rand(4,32,14,14)
b.unsqueeze(1).unsqueeze(2).unsqueeze(0) # b.shape torch.Size([1,32,1,1])
Expand
对于原来维度是1的维度,可以扩展,对于原来维度不是1的维度,比如想从3扩展到M,是不可行的,因为没有给出策略。
a=torch.rand(4,32,14,14)
b=torch.rand(1,32,1,1)
b.expend(4,32,14,14).shape #torch.Size([4,32,14,14])
b.expend(-1,32,-1,-1).shape #torch.Size([1,32,1,1]) -1 表示这个维度保持不变
b.expend(-1,32,-1,-4).shape #这样之前也可以编译,但-4没有任何意义,之后Facebook修复了这个bug
repeat
主动复制内存数据。传入参数表示在这个维度上复制几次数据。

矩阵的转置
.t() 矩阵的转置
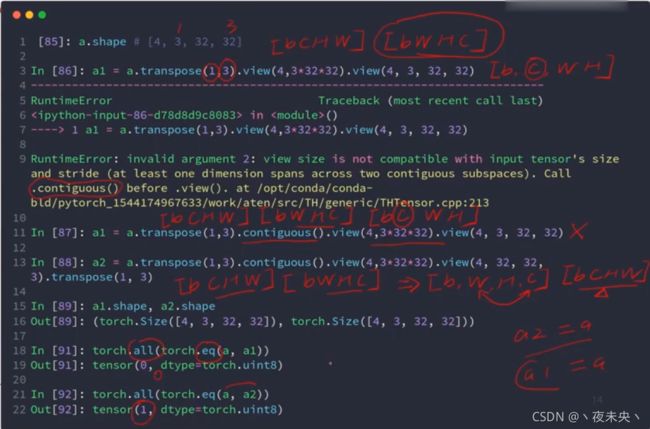
view会导致维度顺序变模糊,所以需要人为跟踪
验证两个数据是否相等:
torch.all(torch.eq(a,b)) #a b相等则返回1,a b不等则返回0
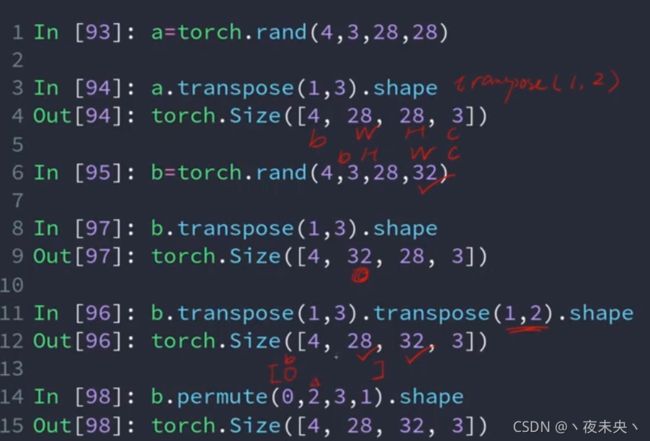
如果我们想要做一种操作,这个操作是只把某一维度提前,其他维度按顺序不变,那么如果使用transpose函数,则需要至少用两次transpose,而如果直接用permute函数,则可以直接把某个维度放在指定的位置上。如下图所示:
Broadcasting(自动扩展)
根据我们的需要调用unsqueeze和expend。举个例子,我们有shape为[4,32,8]的一个数据,现在要给这个数据加一个数值为5的标量,由于矩阵相加要求维度相同,所以怎么加的问题就需要用到Broadcasting了。

拼接与拆分
四个函数:Cat,Stack,Split,chunk
cat只会在原有维度上进行拼接,stack在拼接的时候会创建新的维度。对于cat来说,在拼接的维度上可以不一样,但是在其他维度必须一样。对于stack来说,在所有维度上必须一样。
split是按长度进行拆分,chunk是按数量进行拆分
基本运算
- 相加:torch.add(a,b)
- 相减:torch.sub(a,b)
- 相乘:torch.mul(a,b)
- 相除:torch.div(a,b)
- 矩阵相乘:torch.mm(a,b) torch.matmul(a,b) a@b
- pytorch中w的第一个维度代表channel的out维度,第二个维度代表channel的in维度,所以x@w时,真正写代码需要写[email protected]()
- .t()只适用于二维,高维要用transpose
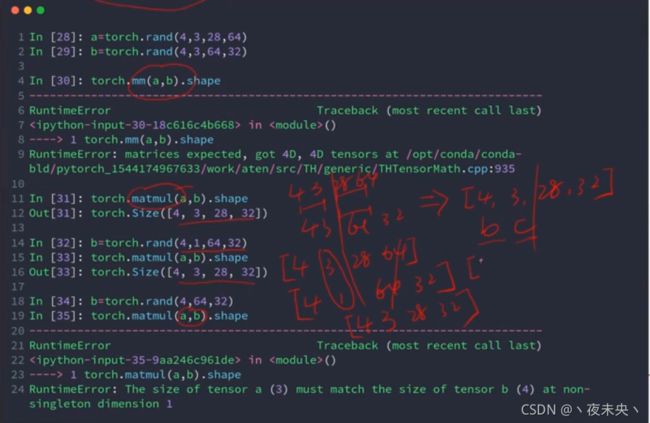
- 下面第二个例子,符合broadcast的运算机制就会自动调用
- 平方 .pow()
- 开根:.sqrt()
- 指数:.exp()
- .log() 默认以e为底

- .floor() 向下取整,.ceil()向上取整 a.trunc()整数和小数分开的整数部分,.frac()整数和小数分开的小数部分
- .clamp() 把某一个数据,限制在某一个数内,比如.clamp(a,10),a中小于10的都看作10。
统计属性
求范数

返回最大元素的索引
a.argmax(dim=),返回在哪个维度上的最大元素的索引。
这个函数还有一个参数,就是keepdim,如果keepdim为true则返回最大值元素的位置时保持原来的维度不变。如果为false(默认为false),则比如(4,10)的数据让返回dim=1的最大元素的位置,返回的数据只是一个[4]的数据,而不是[4,1]。
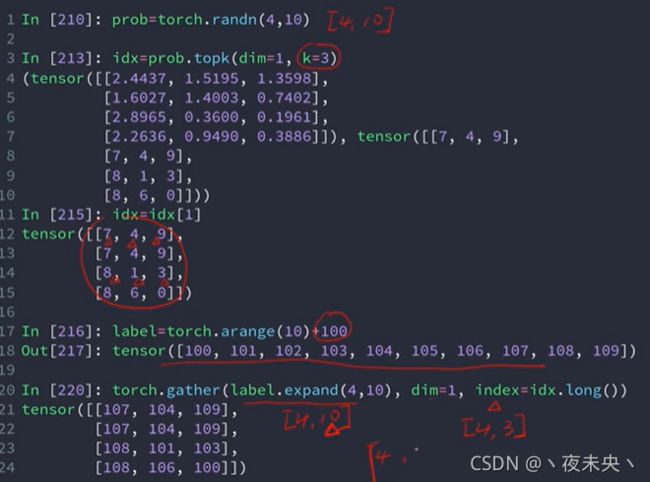
返回top-k的元素
a.topk(n,dim=,largest=),n代表返回top-n的元素,dim代表在哪个维度,largest为true代表返回最大元素,largest为false代表返回最小元素。
求第k小的元素
a.kthvalue()
where 语句与condition
where语句的执行是放在了GPU上的,往往能代替使用两个for循环去给某个tensor根据条件赋值的操作,比较麻烦的是condition条件的生成。
gather查表语句
Loss的梯度
当我们先给一个变量w赋了初值之后,可以在传入参数里设置required_grad表示需要求导,也可以赋值之后,w.requires_grad_()表示需要求导。

上面这个图,意思是一开始赋值之后w不需要求导,紧接着建立了动态图,mse=F.mse_loss(torch.ones(1),xw)。后面修改了w之后,如果要顺利运行,还需要再建图,重新执行,mse=F.mse_loss(torch.ones(1),xw),这就是pytorch的动态图建立与tensorflow静态图建立的区别。
Visdom可视化工具的使用
直接pip install visdom成功的,在linux环境下运行不会报错,在windows环境下运行,会报错,建议直接去官方下载源码。
visdom官方源码地址
然后到下载文件的目录下面,在命令行运行 pip install -e . 命令
使用技巧:
from visdom import Visdom
viz =Vizdom()
viz.line([0.],[0.].win='train_loss',opts=dict(title='train loss'))
viz.line([loss.item()],[global_step],win='train_loss',update='append')
Regularization
Reduce Overfitting:
- More data
- Constraint model complexity
- Dropout
- Data argumentation
- Early stopping



学习率衰减



每30个epoch,learning rate减小为原来的0.1。
Early Stopping, Dropout


实现二维卷积神经网络

nn.Conv2d还是一个类。
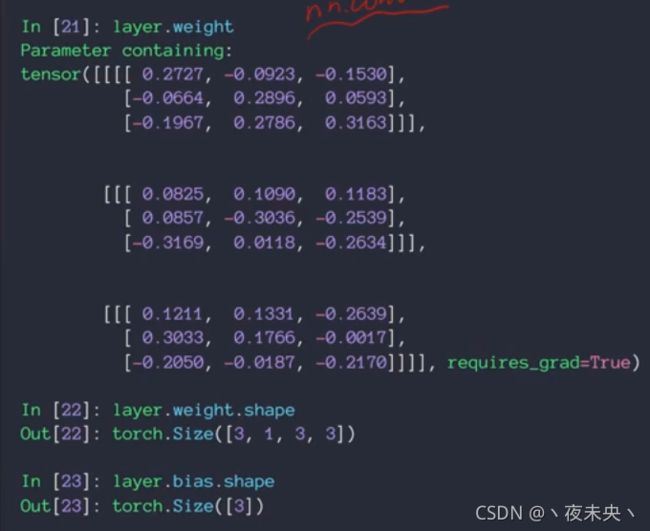
layer.weight.shape 的四个维度分别表示,kernal的数量,输入的input的channel数量,以及kenal的size(两维)。
池化层与采样
下采样:

上采样:
Relu:
Batch Norm:
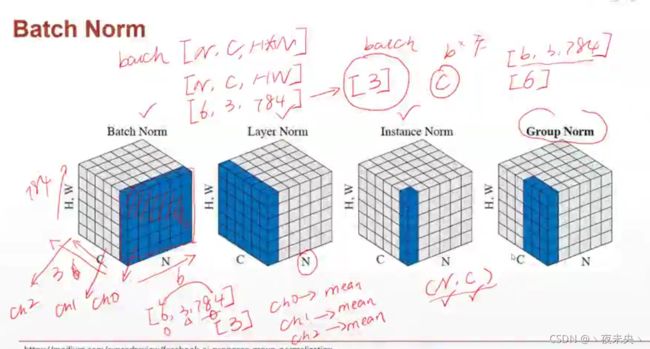

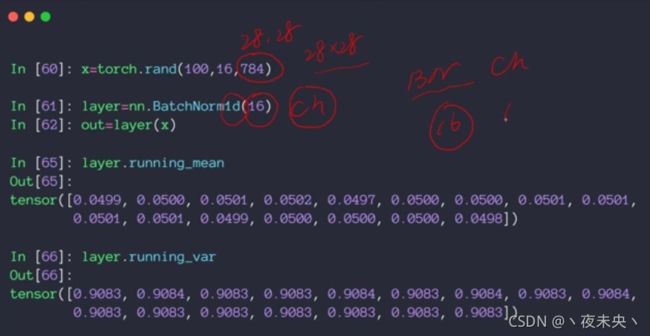
调用这个BatchNorm1d,只需要传入通道数即可。


weight得到的是 γ \gamma γ,bias得到的是 β \beta β,并不是得到 μ \mu μ和 σ 2 \sigma ^2 σ2
可以用vars(layers)得到这一层所有的参数去看到。
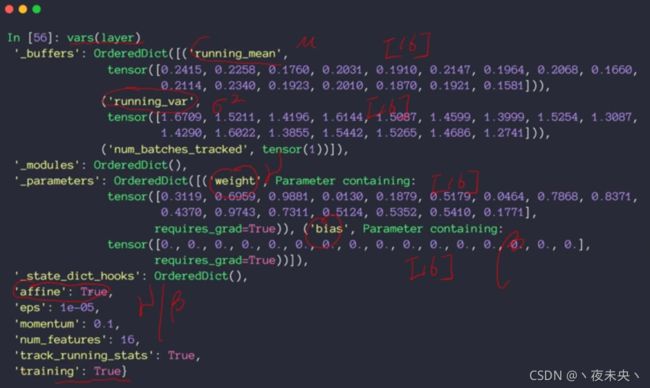
BN层在train和test时执行的过程是不一样。所以test时一定要设置成.eval()状态。
nn.Module
所有网络层的一个父类。提供了很多已经写好的API,比如Linear,ReLU,Sigmoid,Conv2d,ConvTransposed2d,Dropout等等。
save and load

自定义数据集处理
Step1:Load data
- Inherit from torch.utils.data.Dataset
- __len__
- __getitem__
class NumbersDataset(Dataset):
def __init__(self,training=True):
if training:
self.samples = list(range(1,1001))
else:
self.samples = list (range(1001,1501))
def __len__(self):
return len(self.samples)
def __getitem__(self,idx):
return self.samples[idx]
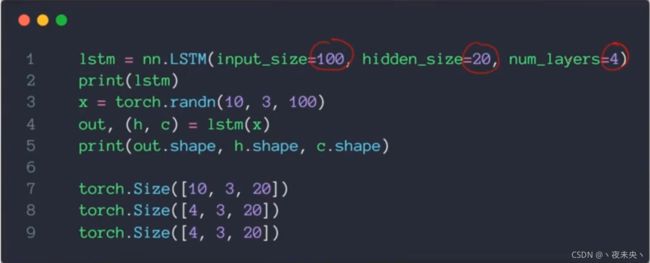
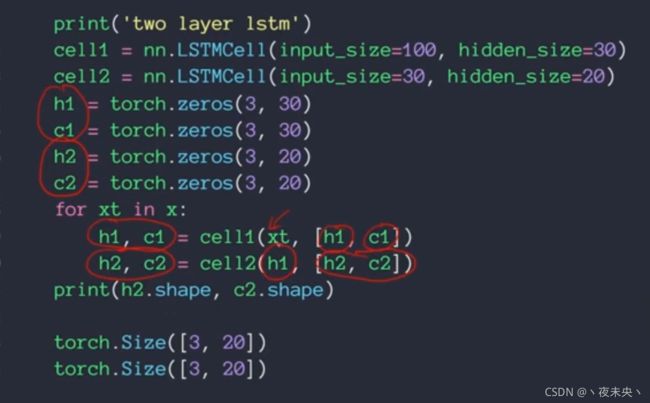
LSTM的使用