【联邦学习】最优物联网联邦学习的多准则客户端选择模型
论文来源:FedMCCS: Multi Criteria Client Selection Model for Optimal IoT Federated Learning
联邦学习机制:由1个参数服务器和多个边缘节点组成,参数服务器负责收集各参加节点上传的梯度,根据优化算法对模型各参数进行更新,维护全局参数;参与节点独立地对本地拥有的敏感数据集进行学习。每轮学习结束后,节点将计算的梯度数据上传至参数服务器,由服务器进行汇总更新全局参数。然后节点从参数服务器下载更新后的参数,覆盖本地模型参数,进行下一轮迭代。

背景:参与FL流程的客户选择目前处于完全/准随机状态。然而,边缘环境中客户端设备的异构性及其有限的通信和计算资源可能无法完成训练任务,这可能导致许多的学习回合被丢弃影响模型的准确性。
在本文中,提出了FedMCCS,一种基于多标准的客户端选择方法,在联邦学习中。考虑客户端资源的所有CPU、内存、能耗和时间,以预测它们是否能够执行FL任务,对参与联邦学习的客户端进行有目的的选择。

首先,服务器为某个任务生成一个通用模型,然后选择随机的客户机与模型参数进行通信。选定的客户端数量等于[K ×C],其中K是客户端总数,C是一个超参数,它定义了每一轮中涉及的客户端比例。在更新和上传步骤中,每个选定的客户端使用其本地数据训练模型,并与服务器共享新生成的参数。一旦服务器接收到客户端的更新,它就开始对它们进行平均以获得增强的模型。如果没有收到足够的更新,并且报告了延迟,服务器将放弃这一轮。最后,重复这些步骤,直到达到期望的模型性能。
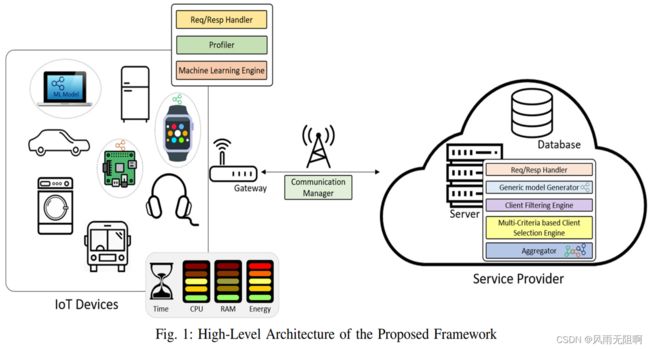
基于多标准的客户选择引擎(Multi-Criteria base Client Selection Engine):是我们系统中的主要模块。它允许选择每轮可用和高性能客户端(图中彩色设备)的最大数量,以便聚合它们的更新。所提出的选择算法采用多个标准(时间、CPU、内存和能量)来实现最大化目标。
FedMCCS:对客户端的选取由一下两部分组成
1、基于位置过滤客户端 + 2、制定客户端选择机制
首先,使用基于分层的抽样来过滤位于同一时区的客户。这涉及到选择所有能够联系到的同类客户来提出培训要求。
接着,将发起与被过滤的客户端的通信,以获取关于它们在先前的FL轮次中利用的资源。根据响应,基于线性回归的算法预测客户端是否有足够的CPU、内存和能量来执行训练任务。
FedMCCS算法

聚合:设备的有限资源可能导致许多系统崩溃。按照[1]中类似的结算方法,通过在每轮处理30%的无响应的选定客户端来补偿设备丢失。当超过30%的更新没有被接收到时,FL轮被认为被丢弃。否则,聚合成功执行。
基于多准则的FL客户端选择模型(FedMCCS)
问题定义:
形式上,设 = (_1,_2,… _)是所有客户端的集合,每个客户端具有一组m对{,},其中n是网络相关数据, ∈{normal正常,abnormal异常}是其标签。首先,求_ = (_1 ,_2 ,… _),其中_ ⊆ ,表示基于分层方法过滤的客户端,以将客户端分类到同类组中,这更好地表示整个集合。接下来,在由_ = (_1 ,_2 ,…,_),其中_ ⊆ _ ,j <=[K × C]。
我们的目标是根据Google在中获得的结果最大化客户端,表明当每轮聚合更多更新时,期望的准确性收敛得更快。
问题公式化:
将问题公式化为具有背包和其他约束的双层最大化,如下所示:
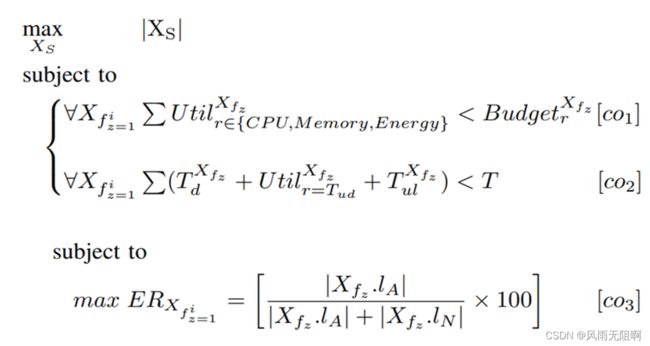
我们优先考虑具有最高事件率的客户,这导致较少的偏差,即使他们具有最大数量的异常样本。例如,如果客户端A有4000个样本,其中70个是异常的,而另一个客户端B有200个样本,其中50个是异常的,则我们优先考虑客户端B,因为其数据的事件率等于25%远高于客户端A的事件率,后者只有1.75%。
co1:每种设备类型的资源利用的有限预算,在某种程度上不会导致退出。我们根据每种设备类型的资源类型来定义动态预算。代表最大设备上任务消耗的这种预算允许完成训练过程直到完成。〖〗_(∈{,,})^(_ ) 表示在训练模型时客户端_的资源r的预测利用率,其中r表示CPU,Memory或Energy。〖〗_^(_ )是每种设备类型的资源预算。
co2:下载、更新和上传模型时不超过的定义阈值T。〖〗_=_表示训练模型时更新时间资源的预测利用率。而_^(_ )和_^(_ )分别表示客户端Xc下载和上传模型所需的时间。
co3:根据事件率选择所需的客户端数量。客户端具有非独立且不同分布的数据集,其中后者是根据每个客户端行为和与ML模型相关的应用的使用来生成的。因此,一些客户可能会产生分类不平衡的模型,大多数样本只属于一个类别。我们用ER表示客户端数据集的事件率,表示少数类分布的表示,而_∙_和_∙_分别代表客户端_的异常样本和正常样本。
定理1:我们的多准则FL客户选择问题是NP-hard的。
证明:我们公式化的最大化问题可以归结为经典的背包问题,其目标是以总重量小于或等于特定限制并且所选物品的总价值最大化的方式确定要包含在袋子中的物品。
现在给定客户选择问题的一个实例,我们将其转换为背包问题的一个实例,定义如下:
1、集合|_|如同背包问题中的麻袋
2、要选择的客户是背包问题中的项目
3、客户端通过其资源的权重(〖〗(∈{,,})^(_ ) },应该< 〖〗^(_ ))以及下载、更新和上传模型所需的总时间(∑(_^(_ )+ 〖〗(=_)^(_ )+ _^(_ )),应该< T),而客户端的值是它们的事件率(〖〗(_(_(=1)^ ) ))。这就像背包中的物品已经给出了重量和价值。
这种简化使得我们的客户选择问题是NP难的,采用基于贪婪算法的启发式客户选择


基于线性回归的资源利用预测:根据客户端在过去FL轮中的历史,服务器为训练时间、CPU、存储器和能量中的每一个估计预测函数。这个函数用等式表示。3表示输入变量x和输出变量_之间的线性关系。我们用x表示客户端的数据集大小,用_表示设备资源利用率〖〗_,其中r表示训练时间、CPU、内存或能量。

中αr和βr是模型的回归系数。
为了测量拟合优度——换句话说,资源利用率预测得有多好,我们在等式4中为n个历史记录中的每一个获得残差εr。残差越小,拟合越好。

目标是通过最小化导致最佳拟合线的残差来获得回归系数。残差最小化的一种常用方法是最小二乘回归,该方法通过n次记录的平方偏差之和的最小可能值找到αr和βr。因此,最小二乘回归倾向于最小化以下函数:
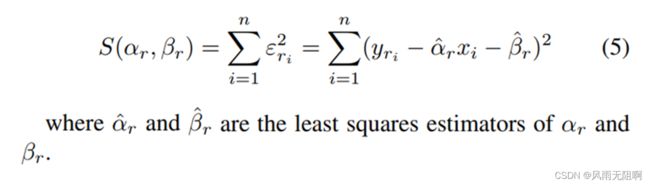

首先,使用基于分层的抽样来过滤位于同一时区的客户。这涉及到选择所有能够联系到的同类客户来提出培训要求。接下来,将发起与被过滤的客户端的通信,以获取关于它们在先前的FL轮次中利用的资源。根据响应,基于线性回归的算法预测客户端是否有足够的CPU、内存和能量来执行训练任务。计算模型下载、更新和上传的估计时间,并与服务器定义的接收所有更新的阈值进行比较。
基于分层的客户抽样,允许根据客户的位置形成同类客户群,以便筛选能够响应服务器请求的客户。
基于多标准的优化模型,允许最大化FL客户的数量,并有足够的资源和时间来完成培训任务,而不会中途退出。我们的方案还提供了基于线性回归的机制,用于预测正在进行的FL轮的CPU、存储器和能量的利用,以及模型参数的下载、更新和上传的预测时间。
训练集的最佳均衡分布,通过对事件率最高的可用客户端进行优先排序来优化客户端选择。
FedMCCS的优点:
(1)通信轮次减少了,
(2)每轮有更多的客户端选择,
(3)丢弃的轮次显著减少,
(4)网络开销最小化。