BEV感知的开源数据集分享
BEV感知系列分享是整数智能推出的一个全新分享系列,在这个系列中,我们将介绍BEV感知相关的算法和数据集等内容。BEV感知系列主要分为以下几篇文章:
-
BEV感知,是下一代自动驾驶感知算法风向吗?
-
BEV感知的开源数据集分享
-
更多干货正在更新中...
在本篇中,我们将介绍截止目前为止各大科研机构和企业推出的适用于BEV算法开发的自动驾驶数据集。
本篇介绍的数据集涵盖了真实世界的图像数据、点云数据和仿真构建的自动驾驶场景数据。所有这些数据集都提供了有价值的信息,研究人员可以利用这些数据集来帮助自动驾驶汽车开发BEV感知算法。
「本期划重点」
-
nuScenes:解决缺乏多模态数据集的问题
-
Waymo:以分片的TFRecord格式文件提供
-
Cam2BEV:语义分割BEV视角的仿真数据集
-
Argoverse2:同时包含6个城市的高清地图
-
CityScapes 3D:仅使用立体RGB图像进行标记
-
OpenLane:第一个真实世界的3D车道数据集
-
DeepAccident:第一个用于自动驾驶大规模事故数据集
-
Apollo Synthetic, AIODrive:用于自动驾驶的仿真数据集
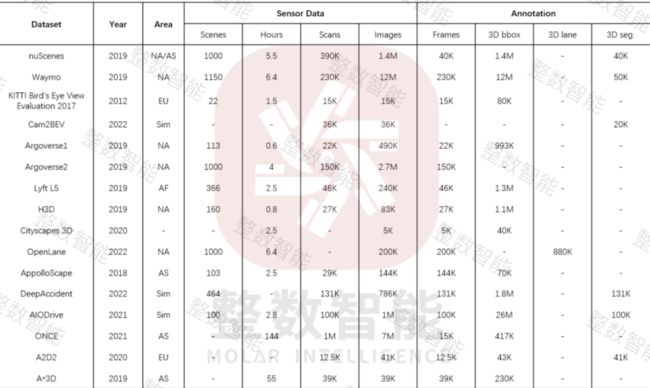
在City下面,“AS”代表亚洲,“EU”代表欧洲,“NA”代表北美,“Sim”代表模拟数据。在Sensor Data下,Scenes是指数据集的剪辑(对于不同的数据集,Scenes的长度是不同的),Scans指点云数据。在Annotation下,Frames表示3D bbox/ 3D lane注释帧的数量,3D bbox/ 3D lane表示3D bbox/ 3D lane注释实例的数量,3D seg.表示点云的分割注释帧数
01「nuScenes」
-
发布方:Motional
-
下载地址:
https://nuscenes.org/nuscenes#download
-
论文地址:
https://arxiv.org/pdf/1903.11027.pdf
-
发布时间:2019年
-
简介:自动驾驶中安全导航的一个关键部分是检测和跟踪车辆周围环境中的人。为了实现这一目标,现代自动驾驶汽车部署了几个传感器和复杂的检测和跟踪算法。这种算法越来越依赖于机器学习,这就促使人们需要基准数据集。虽然有大量的图像数据集用于此目的,但缺乏多模态数据集来展示与建立自动驾驶感知系统相关的全部挑战,nuScenes数据集就是来解决这个问题
-
特征
-
具有完整的传感器套件(1 x Lidar、5 x Radar、 6 x 摄像头、 IMU、GPS)
-
1000个场景,每个场景20秒
-
1,400,000张相机图像
-
390,000次激光雷达扫描
-
两个多元化城市:波士顿和新加坡,分别为左侧行驶和右侧行驶交通
-
140万个3D边界框,分为23个对象类别
-
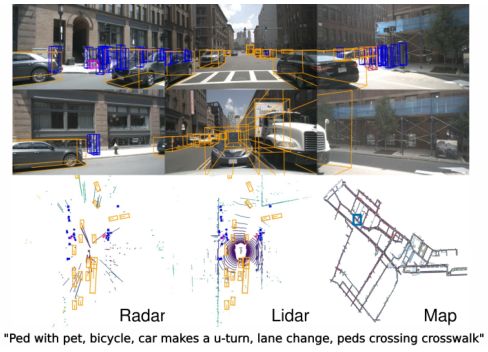 nuScenes数据集的例子,有6种不同的摄像头视图、激光雷达和雷达数据,以及人类注释的语义地图
nuScenes数据集的例子,有6种不同的摄像头视图、激光雷达和雷达数据,以及人类注释的语义地图
02「Waymo」
-
发布方:WAYMO
-
下载地址:
https://waymo.com/open/download/
-
论文地址:
https://arxiv.org/abs/1912.04838
-
发布时间:2019年
-
简介:数据集以分片的TFRecord格式文件提供,其中包含协议缓冲区数据。这些数据中训练集占70%,测试集占15%,验证集占15%。该数据集由103,354个片段组成,每个片段包含20秒的10Hz的物体轨迹和该片段所覆盖区域的地图数据。这些片段被进一步分割成9秒的窗口(1秒的历史数据和8秒的未来数据),有5秒的重叠。数据以两种形式提供。第一种形式是存储为情景协议缓冲区。第二种形式是将Scenario protos转换为tf.Example protos,包含用于建立模型的张量
-
特征
-
包含1200万个高质量、人工注释的3D ground truth框
-
包含1200万个用于激光雷达数据,以及用于相机图像的2D紧密拟合边界框
-
所有ground truth框都包含支持目标跟踪的轨迹标识符,约113k激光雷达物体轨迹和约250k相机图像轨迹
-
研究人员可以使用数据集提供的滚动快门感知投影库,从三维激光雷达方框中提取二维正交相机方框
-
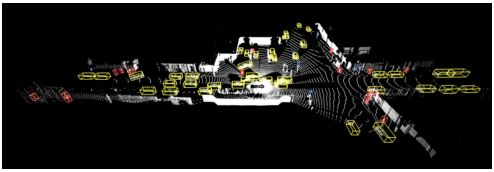 激光雷达标签的例子。黄色=车辆,红色=行人,蓝色=符号,粉色=自行车
激光雷达标签的例子。黄色=车辆,红色=行人,蓝色=符号,粉色=自行车
03「KITTI Bird's Eye View Evaluation 2017」
-
发布方:KITTI
-
下载地址:
http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=bev
-
官网地址:
http://www.cvlibs.net/datasets/kitti/index.php
-
发布时间:2017年
-
简介:针对鸟瞰数据的数据集,作者为一辆标准旅行车配备了两个高分辨率彩色和灰度摄像机,Velodyne激光扫描仪和GPS定位系统提供准确的地面实况。该数据集在中型城市卡尔斯鲁厄周围的农村地区和高速公路上驾车拍摄,每张图像最多可以看到15辆汽车和30名行人
-
特征
-
包含7481张训练图像和7518张测试图像以及相应的点云
-
共包括80.256个标记对象
-
为了评估,计算了精度-召回曲线
-

04「Cam2BEV」
-
发布方:RWTH Aachen University
-
下载地址:
https://gitlab.ika.rwth-aachen.de/cam2bev/cam2bev-data
-
论文地址:
https://ieeexplore.ieee.org/abstract/document/9294462
-
发布时间:2020年
-
简介:该数据集是在模拟环境中创建的仿真数据集,在模拟中,自我车辆配备了四个相同的虚拟广角相机覆盖全360度环绕视角,ground truth数据由虚拟无人机摄像机提供,BEV ground truth图像位于自我载体上方的中心,视野大约为70米 x 44米,输入和ground truth图像都以964px x 604px的分辨率记录
-
特征
-
针对可见区域考虑了9个不同的语义类(道路、人行道、人、汽车、卡车、公共汽车、自行车、障碍、植被)
-
图像以2Hz的频率记录
-
包含33000个用于训练的样本和3700个用于验证的样本
-
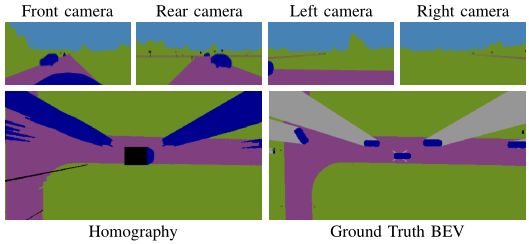 数据集中四个视角的摄像机图像和BEV视角
数据集中四个视角的摄像机图像和BEV视角
05「Argoverse1」
-
发布方:Argo AI
-
下载地址:
https://www.argoverse.org/av1.html
-
论文地址:
https://arxiv.org/abs/1911.02620
-
发布时间:2019年
-
简介:该数据集由匹兹堡和迈阿密的自动驾驶车队收集。包括7个摄像头的360°图像与重叠视野,从远程激光雷达获取的3D点云,进行6-DOF姿态,和3D轨迹标注
-
特征
-
包括超过300000个5秒跟踪场景,用于轨迹预测
-
第一个包含高清地图的自动驾驶数据集
-
包含290公里的地图车道,并包含几何和语义元数据
-
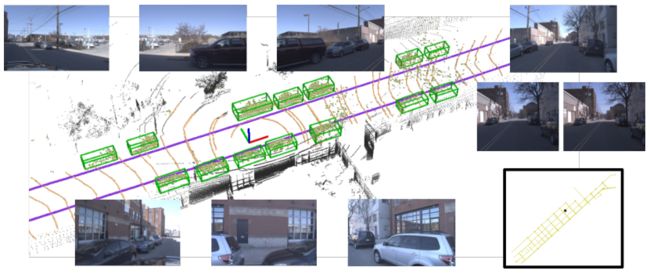 该数据集包含激光雷达测量序列,360°RGB视频,正面立体(中右),和6自由度定位。所有序列都与包含车道中心线(洋红色)、可驾驶区域(橙色)和地面高度的地图对齐。序列用3D长方体轨迹(绿色)进行注释。右下方显示了一个更宽的地图视图
该数据集包含激光雷达测量序列,360°RGB视频,正面立体(中右),和6自由度定位。所有序列都与包含车道中心线(洋红色)、可驾驶区域(橙色)和地面高度的地图对齐。序列用3D长方体轨迹(绿色)进行注释。右下方显示了一个更宽的地图视图
06「Argoverse2」
-
发布方:Argo AI
-
下载地址:
https://github.com/argoai/argoverse-api
-
论文地址:
https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/4734ba6f3de83d861c3176a6273cac6d-Abstract-round2.html
-
发布时间:2021年
-
简介:Argoverse 2是一组来自美国六个城市的开源自动驾驶数据和高清地图:奥斯汀、底特律、迈阿密、匹兹堡、帕洛阿尔托和华盛顿特区。这是同类数据中首批包含用于机器学习和计算机视觉的高清地图的数据版本之一。它集合了三个数据集用于自动驾驶领域的感知和预测研究,分别是带注释的传感器数据集,激光雷达数据集和运动预测数据集
-
特征
-
在所有三个数据集中每个场景都包含自己的3D车道和人行横道几何高清地图
-
由25万个不重叠的场景组成,从美国6个独特的城市驾驶环境中挖掘
-
共包含10种对象类型,其中动态和静态类别各有5种
-
每个场景包括一个本地矢量图和11秒(10Hz)的轨迹数据(2D位置、速度和方向),每种情景的前5秒记为观测窗口,后6秒记为预测窗口
-
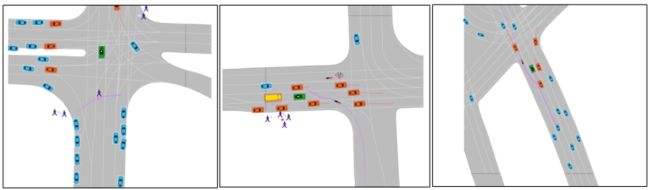 数据集中各种对象类型的混合(车辆、行人、公共汽车、骑自行车的人或骑摩托车的人),自主车辆用绿色表示
数据集中各种对象类型的混合(车辆、行人、公共汽车、骑自行车的人或骑摩托车的人),自主车辆用绿色表示
07「Lyft L5」
-
发布方:Woven Planet Level 5
-
下载地址:
https://level-5.global/data/prediction/
-
官网地址:
https://level-5.global/
-
发布时间:2020年
-
简介:该数据集拥有超过1000小时的数据,这些信息是由20辆自动驾驶汽车组成的车队在加利福尼亚帕洛阿尔托的一条固定路线上历时4个月收集的,数据集中包括自主车队遇到的汽车、骑行者、行人和其它交通代理的移动日志。这些日志来自通过发布方团队的感知系统处理的原始激光雷达、摄像头和雷达数据,非常适合训练运动预测模型
-
特征
-
数据集包括1000+交通代理移动小时数
-
包含170,000个场景,每个场景长25秒,捕捉自动驾驶汽车周围的环境,每个场景都在给定时间点对车辆周围环境的状态进行编码
-
包含有15242个标记元素的高清语义地图和该地区的高清鸟瞰图
-
 数据集中场景的例子,投影在鸟瞰图的栅格化语义地图上。自动驾驶车辆为红色,其它交通参与者为黄色,车道颜色表示行驶方向
数据集中场景的例子,投影在鸟瞰图的栅格化语义地图上。自动驾驶车辆为红色,其它交通参与者为黄色,车道颜色表示行驶方向
08「H3D」
-
发布方:Honda
-
下载地址:
http://usa.honda-ri.com/H3D
-
论文地址:
https://arxiv.org/abs/1903.01568
-
发布时间:2019年
-
简介:这是一个使用3D LiDAR扫描仪收集的大规模全环绕3D多目标检测和跟踪数据集。H3D具有独特的数据集规模,丰富的注释和复杂的场景,可以促进全环绕三维多目标检测和跟踪的研究
-
特征
-
包含160个拥挤和高度互动的交通场景
-
在27721帧中共有100万个标记实例
-
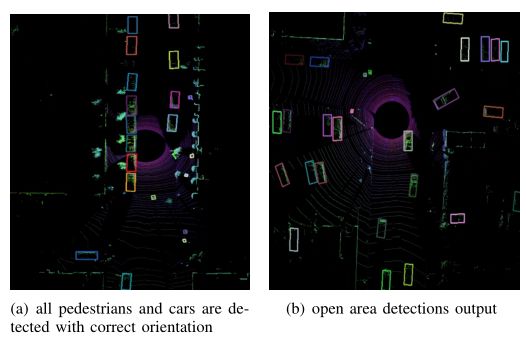 在BEV视角中的检测案例
在BEV视角中的检测案例
09「CityScapes 3D」
-
发布方:CITYSCAPES
-
下载地址:
https://www.cityscapes-dataset.com/cityscapes-3d-dataset-released/
-
论文地址:
https://arxiv.org/abs/2006.07864
-
发布时间:2020年
-
简介:CityScapes 3D具有适用于所有类型车辆的3D边界框注释以及3D检测任务的基准,与现有的数据集相比,该数据集的3D注释仅使用立体RGB图像进行标记,并捕获了所有9个自由度。与基于激光雷达的方法相比,这导致了RGB图像中像素精确地重投影和更高范围的注释。为了简化多任务学习,发布方提供了2D实例段与3D边界框的配对
-
特征
-
仅使用立体RGB图像获得地面ground truth注释
-
提供完整的3D方向标注,包括偏航、俯仰和滚转角度,已覆盖刚性物体的所有九个自由度
-
包含5000张图片,分为2975张用于训练,500张用于验收,1525张用于测试
-
 数据集中鸟瞰图标签辅助的例子
数据集中鸟瞰图标签辅助的例子
10「OpenLane」
-
发布方:上海人工智能实验室自动驾驶团队
-
下载地址:
https://github.com/OpenPerceptionX/OpenLane
-
论文地址:
https://arxiv.org/abs/2203.11089
-
发布时间:2022年
-
简介:OpenLane是第一个具有高质量标记和巨大多样性的大规模真实3D车道数据集。OpenLane是在Waymo Open数据集上构建,遵循相同的数据格式和评估管道。标注员注释了每一帧中的所有车道,由于复杂的车道拓扑结构,例如十字路口/回旋处,在OpenLane中一帧可以包含多达24个车道,大约25%的帧中有超过6个车道
-
特征
-
包含20万帧,超过88万个实例级车道,14个车道类别,以及场景标签和路径封闭对象标注
-
除了车道检测任务,数据集中还标注了(a)场景标签,如天气和位置;(b)最近路径对象(CIPO),定义为最关注的目标对象
-
 OpenLane的注释样本与其它车道数据集的比较
OpenLane的注释样本与其它车道数据集的比较
11「Apollo Synthetic」
-
发布方:appolo
-
下载地址:
https://developer.apollo.auto/synthetic.html
-
官网地址:
https://developer.apollo.auto/index.html
-
发布时间:2019年
-
简介:Apollo Synthetic是一个用于自动驾驶的仿真合成数据集。它包含27.3万个不同的来自各种高视觉保真度的虚拟场景,包括高速公路、城市、住宅、市中心、室内停车场环境。这些虚拟世界是用Unity 3D引擎创建的。合成数据集的最大优势是它提供了精确的地面真实数据。另一个好处是更多的环境变化,如一天中不同的时间,不同的天气条件,不同的交通/障碍,以及不同的路面质量。该数据集提供了大量的ground truth数据,二维/三维物体数据,语义/实例级分割,深度和三维车道线数据
-
特征
-
包括几乎所有的道路场景
-
更多的环境变化
-
提供大量的ground truth数据
-

12「DeepAccident」
 数据集种的图像示例
数据集种的图像示例
-
发布方:香港大学
-
下载地址:
https://hku-deepaccident.github.io/download.html
-
官网地址:
https://hku-deepaccident.github.io/index.html
-
发布时间:2022年
-
简介:DeepAccident数据集是首个用于自动驾驶的大规模事故数据集,包含全面的传感器集,支持各种自动驾驶任务。值得注意的是,对于每个场景都有四个数据收集车辆,两个设计用于相互碰撞,另外两个分别跟在后面。因此,DeepAccident还可以支持多车协同自动驾驶
-
特征
-
安装了64线LiDAR,并安装了六个1920x1080分辨率的摄像头,以提供360度的环境视野
-
数据集中有三种类型的坐标系统,包括世界坐标、车辆坐标和传感器坐标
-
记录了采集车100米范围内物体的位置、偏航角、大小和速度。对于高精地图,数据集中提供了范围内的地图信息,确保数据采集车在任何时间步都能获得100米范围内的地图,每个地图点都包含其位置、方向以及类型数据
-
包含21种类型,包括驾车、骑车、人行道、停车等
-
13「AIODrive」
-
发布方:卡内基梅隆大学
-
下载地址:
http://www.aiodrive.org/download.html
-
论文地址:
http://www.xinshuoweng.com/papers/AIODrive/arXiv.pdf
-
发布时间:2022年
-
简介:为了创新稳健的自动驾驶多传感器多任务感知系统,集合现有数据集的各种优势,作者提出AIODrive,这是一个综合的大规模数据集,提供了全面的传感器、注释和环境变化
-
特征
-
8种传感器模式(RGB, Stereo, Depth, LiDAR, SPAD-LiDAR, Radar, IMU, GPS)
-
所有主流感知任务(检测,跟踪,预测,分割,深度估计等)的注释
-
非分布驾驶场景(恶劣天气和照明,拥挤场景,高速驾驶,违反交通规则和车辆碰撞)
-
 2D-3D语义分割注释
2D-3D语义分割注释
14「ONCE」
-
发布方:华为
-
下载地址:
https://once-for-auto-driving.github.io/download.html#downloads
-
论文地址:
https://arxiv.org/abs/2106.11037
-
发布时间:2021年
-
简介:为了解决数据不足的问题,ONCE(One millionN sCenEs)数据集包含100万个三维场景和700万个相应的二维图像,从数量上看比最大的Waymo Open数据集多5倍,而且三维场景的记录时间为144个驾驶小时,比现有数据集长20倍,涵盖了更多不同的天气条件、交通条件、时间段和地区
-
特征
-
100万LiDAR帧,700万相机图像
-
200平方公里的驾驶区域,144小时驾驶时间
-
15000个完全注释的场景,有5个类别(汽车、公共汽车、卡车、行人、自行车)
-
多样的环境(白天/夜晚,晴天/雨天,城市/郊区)
-

15「A2D2」
-
发布方:奥迪
-
下载地址:
https://www.a2d2.audi/a2d2/en.html
-
论文地址:
https://arxiv.org/abs/2004.06320
-
发布时间:2021年
-
简介:该数据集包括同时记录的图像和3D点云,以及3D边界框、语义分割、实例分割和从汽车总线提取的数据。数据集总的传感器套件包括六个摄像头和五个激光雷达单元,提供360°覆盖,记录的数据进行时间同步和相互注册
-
特征
-
语义分割包含41280帧,包含38个类别
-
数据集中为12499帧提供了3D边界框,标注了14个与驾驶相关的类别
-
 A2D2数据可视化。从左起:语义分割,3D边界框,点云,单帧点云叠加在相机图像
A2D2数据可视化。从左起:语义分割,3D边界框,点云,单帧点云叠加在相机图像
16「A*3D」
-
发布方:Singapore University of Technology and Design
-
下载地址:
https://github.com/I2RDL2/ASTAR-3D(github链接,数据集仍有些问题需解决,需邮件联系作者获取)
-
论文地址:
https://arxiv.org/abs/1909.07541
-
发布时间:2019年
-
简介:由RGB和LiDAR数据组成,具有显著的场景、时间和天气多样性。该数据集由高密度图像(约等于KITTI数据集的10倍)、高遮挡、大量夜间帧(约等于nuScenes数据集的3倍)组成,填补了现有数据集的空白,将自动驾驶研究的任务边界推至更具挑战性的高度多样化的环境
-
特征
-
包含39K帧、7个类和230K 3D对象标注
-
在不同时间(白天,黑夜)和天气(太阳,云彩,雨)捕获
-
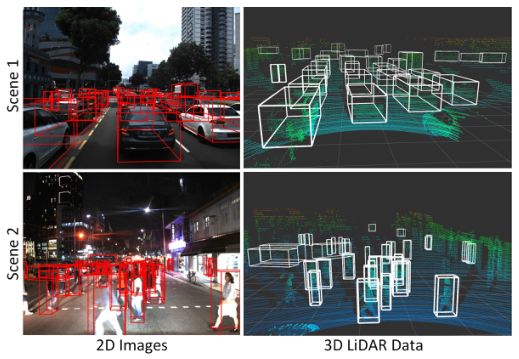 A*3D数据集中的数据样本,包含RGB图像和相应的激光雷达数据,这两组白天和晚上的场景展示了环境中较高的物体密度
A*3D数据集中的数据样本,包含RGB图像和相应的激光雷达数据,这两组白天和晚上的场景展示了环境中较高的物体密度