PaddlePaddle、Paddle Lite、Paddle Inference、FleetX
一、飞桨开源框架(PaddlePaddle)是一个易用、高效、灵活、可扩展的深度学习框架(本地训练学习推理)
飞桨(PaddlePaddle)是集深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需求,拥有活跃的开发者社区生态。提供丰富的官方支持模型集合,并推出全类型的高性能部署和集成方案供开发者使用。
二、Paddle Lite(跨平台轻量化本地推理)
面向端侧场景的轻量化推理引擎Paddle Lite,可以实现飞桨模型在x86/ARM平台下多种OS内的高效部署,同时支持在10种以上的GPU/NPU异构后端上进行推理加速和混合调度;通过Paddle Lite,您在不同端侧场景下的模型部署需求都可以被完美支持。
三、Paddle Inference(云端推理)
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。
由于能力直接基于飞桨的训练算子,因此Paddle Inference 可以通用支持飞桨训练出的所有模型。
Paddle Inference 功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
支持服务器端X86 CPU、NVIDIA GPU芯片,兼容Linux/Mac/Windows系统。支持所有飞桨训练产出的模型,完全做到即训即用。
四、FleetX(分布式训练)
FleetX 是飞桨分布式训练扩展包,为了可以让用户更快速了解和使用飞桨分布式训练特性,提供了大量分布式训练例子,可以查阅 FleetX/examples at develop · PaddlePaddle/FleetX · GitHub,以下章节的例子都可以在这找到,用户也可以直接将仓库下载到本地直接。
五、10分钟快速上手飞桨
1、安装
如果你已经安装好飞桨那么可以跳过此步骤。飞桨提供了一个方便易用的安装引导页面,你可以通过选择自己的系统和软件版本来获取对应的安装命令,具体可以点击快速安装查看。或者查看
Windows下的Conda安装并创建python环境_シ❤゛甜虾的个人博客-CSDN博客Anaconda是一个免费开源的Python和R语言的发行版本,用于计算科学,Anaconda致力于简化包管理和部署。Anaconda的包使用软件包管理系统Conda进行管理。Conda是一个开源包管理系统和环境管理系统,可在Windows、macOS和Linux上运行。下载Anaconda,然后进行安装https://www.anaconda.com/安装Anaconda后,以管理员运行CMD,创建python3.9的环境conda create -n paddle_env python=https://blog.csdn.net/g313105910/article/details/122447198?spm=1001.2014.3001.5501Windows下的PaddlePaddle安装_シ❤゛甜虾的个人博客-CSDN博客Windows下的Conda安装并创建python环境请查看Windows下的Conda安装并创建python环境_シ❤゛甜虾的个人博客-CSDN博客Anaconda是一个免费开源的Python和R语言的发行版本,用于计算科学,Anaconda致力于简化包管理和部署。Anaconda的包使用软件包管理系统Conda进行管理。Conda是一个开源包管理系统和环境管理系统,可在Windows、macOS和Linux上运行。下载Anaconda,然后进行安装https://www.anaconda.com/安https://blog.csdn.net/g313105910/article/details/122448982?spm=1001.2014.3001.5501
2、导入飞浆
进入python环境
activate paddle_env
导入飞浆
import paddle
print(paddle.__version__)查看版本

3、手写数字识别任务,加载内置数据集
import paddle.vision.transforms as T
transform = T.Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)4、运行
在PaddleDetection目录新建test.py加入如下代码
import paddle
print(paddle.__version__)
import paddle.vision.transforms as T
transform = T.Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 预计模型结构生成模型对象,便于进行后续的配置、训练和验证
model = paddle.Model(mnist)
# 模型训练相关配置,准备损失计算方法,优化器和精度计算方法
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 开始模型训练
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
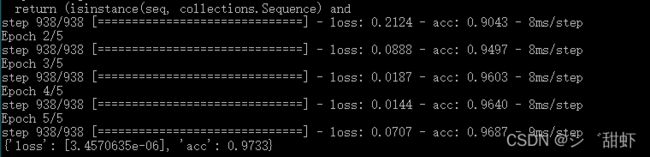
print(model.evaluate(val_dataset, verbose=0))执行python test.py运行结果如下