深度学习笔记--线性代数,概率论,数值计算
目录
线性代数
范数
L2
L1
Frobenius范数
特殊类型的矩阵和向量
特征分解eigendecomposition
奇异值分解SVD
概率论
概率分布
条件概率(conditional probability)
期望、方差和协方差
常用概率分布
贝叶斯定理(Bayes' Rule)
信息论
基本思想
自信息
香农熵
KL散度
交叉熵 ( cross-entropy )
数值计算
线性代数
范数
⼀个向量的范数告诉我们⼀个向量有多⼤。这⾥考虑的⼤⼩(size)概念不涉及维度,⽽是分量的⼤⼩
在线性代数中,向量范数是将向量映射到标量的函数f。给定任意向量x,向量范数要满⾜⼀些属性。第⼀个性质是:如果我们按常数因⼦α缩放向量的所有元素,其范数也会按相同常数因⼦的绝对值缩放:
最后⼀个性质要求范数最⼩为0,当且仅当向量全由0组成。

范数是将向量映射到非负值的函数。直观上来说,向量 x的范数衡量从原点到点 x 的距离。
L2
当p=2时,L2 范数称为欧几里得范数 (Euclidean norm),它表示从原点出发到向量 x 确定的点的欧几里得距离。
为了方便计算, 我们也常常用 L2 norm的平方,可计算为向量转置与自身的乘积 xTx 。平方L2 范数在数学和计算上都比L2 范数本身更方便。例如,平方L2 范数对 x 中每个元素的导数只取决于对应的元素,而L2 范数对每个元素的导数和整个向量相关。
pytorch中:torch.norm(u) u是一个向量
L1
但是在很多情况下,平方L2 范数也可能不受欢迎,因为它在原点附近增长得十分缓慢。在某些机器学习应用中,区分恰好是零的元素和非零但值很小的元素是很重要的。在这些情况下,我们转而使用在各个位置斜率相同,同时保持简单的数学形式的函数:L1 范数
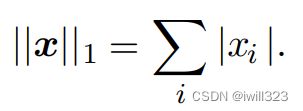
当机器学习问题中零和非零元素之间的差异非常重要时,通常会使用L1范数。每当 x 中某个元素从0增加ε ,对应的L1 范数也会增加ε。L1 范数经常作为表示非零元素数目的替代函数
L2范数对权重向量的⼤分量施加了巨⼤的惩罚,这使得我们的学习算法偏向于在⼤量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。相⽐之下, L1惩罚会导致模型将权重集中在⼀⼩部分特征上,⽽将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要。
比如我们常常想减小模型非零变量的数量以防止过拟合,也就是很多变量变为零,而将大部分权重放在某些有意义的变量上,这时候由于L2 在变量接近零时跟随的改变较小,会出现很多趋近于零而不为零的变量,而 L1 norm由于跟随于每个变量的变动是恒定的,使得零元素和非零但趋近于零的变量仍对该项有显著贡献,在目标是减小这一项的过程中会使很多变量归零(注意是归零而不仅仅是较小接近零),从而更有效的减少过拟合。
pytorch中:torch.abs(u).sum() u是一个向量
Frobenius范数
有时候我们可能也希望衡量矩阵的大小。在深度学习中,最常见的做法是使用Frobenius范数 (Frobenius norm),类似于向量的L2 范数。Frobenius范数满⾜向量范数的所有性质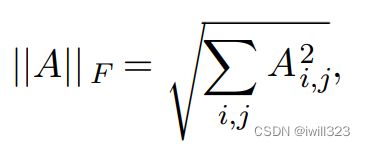
torch.norm(u) u是一个矩阵
特殊类型的矩阵和向量
对角矩阵 (diagonal matrix)只在主对角线上含有非零元素,其他位置都是零。用diag(ν)表示对角元素由向量ν中元素给定的一个对角方阵。并非所有的对角矩阵都是方阵。长方形的矩阵也有可能是对角矩阵。
对称 (symmetric)矩阵是转置和自己相等的矩阵
单位向量 (unit vector)是具有单位范数 (unit norm)的向量。 L2norm等于1
正交矩阵 (orthogonal matrix)指行向量和列向量是分别标准正交的方阵,即转置与它自身的矩阵乘积是单位矩阵
特征分解eigendecomposition
方阵 A 的特征向量 (eigenvector)是指与 A 相乘后相当于对该向量进行缩放的非零向量ν: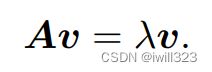
其中标量λ称为这个特征向量对应的特征值 (eigenvalue)
如果ν是A的特征向量,那么任何缩放后的向量也是A的特征向量。此外,sν和ν有相同的特征值。基于这个原因,通常我们只考虑单位特征向量
假设我们将矩阵A的所有特征向量连成一个矩阵V: V=[v(1),...,v(n)] ,而对应特征值连成一个向量 λ=[λ1,...,λn]T ,那么矩阵A就可以表示为它的特征分解形式:
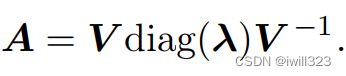
将矩阵分解 (decompose)成特征值和特征向量,可以帮助我们分析矩阵的特定性质。
左图是一族单位向量,并且标出了矩阵A的特征向量v1和v2。将矩阵A和这些单位向量相乘,得到的向量族如右图。矩阵A实际上是将空间在其特征向量的方向上各自拉伸了对应的特征值(λ)的尺度
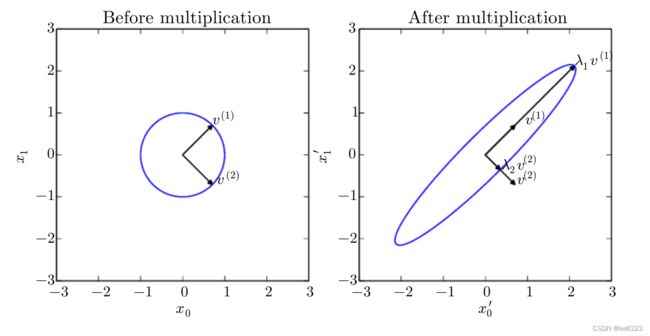
不是每一个矩阵都可以分解成特征值和特征向量。我们通常只需要分解一类有简单分解的矩阵。具体来讲,每个实对称矩阵都可以分解成实特征向量(正交矩阵)和实特征值
奇异值分解SVD
奇异值分解(singularvaluedecomposition,SVD),是将矩阵分解为奇异向量(singularvector)和奇异值(singularvalue)。每个实数矩阵都有一个奇异值分解,但不一定都有特征分解。例如,非方阵的矩阵没有特征分解,这时我们只能使用奇异值分解
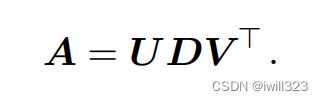
假设 A 是一个m×n的矩阵,那么 U 是一个m×m的矩阵, D 是一个m×n的矩阵, V 是一个n×n矩阵。矩阵 U 和 V 都定义为正交矩阵,而矩阵 D 定义为对角矩阵。注意,矩阵 D 不一定是方阵。
对角矩阵 D 对角线上的元素称为矩阵 A 的奇异值 (singular value)。矩阵 U 的列向量称为左奇异向量 (left singular vector),矩阵 V 的列向量称右奇异向量 (right singular vector)。
概率论
随机变量(random variable):某一变量可能随机的取不同数值。随机变量可以是离散的也可以是连续的。
概率分布
- 概率分布:对随机变量取不同数值的可能性的一种描述。
- 概率质量函数(probability mass function,简称PMF):离散型随机变量出现概率的映射。用大写字母P来表示
- 联合概率分布 (joint probability distribution):多个变量的概率分布。P(x=x,y=y)表示x=x和y=y同时发生的概率。我们也可以简写为P(x,y)。
- x∼P(x): ∼符号说明随机变量遵循的分布。
- 概率密度函数 (probability density function,PDF): 连续型随机变量的概率分布。概率密度函数P(x)并没有直接对特定的状态给出概率,相对的,它给出了落在面积为δx的无限小的区域内的概率为P(x)δx,可以对概率密度函数求积分来获得点集的真实概率质量
- 边缘概率分布 (marginal probability distribution): 知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布。这种定义在子集上的概率分布被称为边缘概率分布。例如,假设有离散型随机变量x和y,并且我们知道P(x,y)。可以依据下面的求和法则 (sum rule)来计算P(x):

对于连续型变量,我们需要用积分替代求和

- 求和法则(sum rule):B的概率相当于计算A的所有可能选择,并将所有选择的联合概率聚合在一起:

这也称为边际化(marginalization)。 边际化结果的概率或分布称为边际概率(marginal probability) 或边际分布(marginal distribution)。
- 独立性:如果两个随机变量A和B是独立的,意味着事件A的发生跟B事件的发生无关。根据贝叶斯定理,得到P(A∣B)=P(A)。在所有其他情况下,我们称A和B依赖。 由于P(A∣B)=P(A,B)/P(B)=P(A)等价于P(A,B)=P(A)P(B), 因此两个随机变量是独立的,当且仅当两个随机变量的联合分布是其各自分布的乘积。 同样地,给定另一个随机变量C时,两个随机变量A和B是条件独立的(conditionally independent), 当且仅当P(A,B∣C)=P(A∣C)P(B∣C)。
条件概率(conditional probability)
- 某个事件在给定其他事件发生时出现的概率。将给定x=x,y=y发生的条件概率记为P(y=y|x=x)。这个条件概率可以通过下面的公式计算
条件概率只在P(x=x)>0时有定义。我们不能计算给定在永远不会发生的事件上的条件概率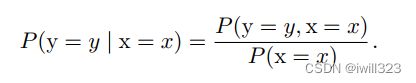
- 条件概率的链式法则:任何多维随机变量的联合概率分布,都可以分解成只有一个变量的条件概率相乘的形式:

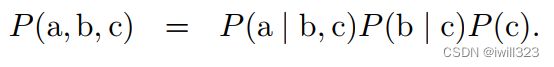
- 独立性和条件独立性:两个随机变量x和y,如果它们的概率分布可以表示成两个因子的乘积形式,并且一个因子只包含x,另一个因子只包含y,我们就称这两个随机变量是相互独立的
期望、方差和协方差
- 期望:对于某一个关于x的函数f(x),假设x的分布为P(x),对于离散的x,f(x)的平均值即其期望

- 方差 (variance):随机变量函数的方差衡量的是:当从该随机变量分布中采样不同值x时, 函数值偏离该函数的期望的程度
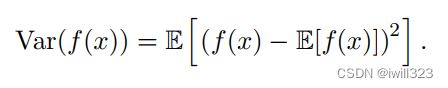
- 协方差 (covariance)给出了两个变量线性相关性的强度以及这些变量的尺度:
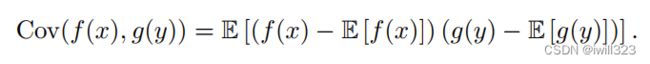
协方差的绝对值如果很大,则意味着变量值变化很大,并且它们同时距离各自的均值很远。如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值,反之亦然。
协方差矩阵的对角元是方差。
协方差和相关性:相关系数 (correlation)将每个变量的贡献归一化,只衡量变量的相关性而不受各个变量尺度大小的影响
联系:如果两个变量相互独立,那么它们的协方差为零;如果两个变量的协方差不为零,那么它们一定是相关的。
区别:两个变量如果协方差为零,它们之间一定没有线性关系。独立性是比零协方差的要求更强,因为独立性还排除了非线性的关系。两个变量相互依赖,但是具有零协方差是可能的。此处书上有一个例子(略)
常用概率分布
- Bernoulli分布:当随机变量只能取0和1两种结果,则其分布为伯努利分布
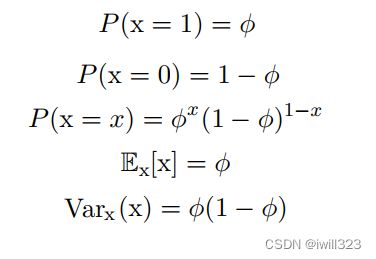
- 多项式分布(Multinoulli Distribution):当随机变量可以取k个不同值时的分布称为多项式分布,伯努利分布可以看做k=2时的多项式分布
- 正态分布:

是x的期望, σ 是x的标准差。
采用正态分布在很多应用中都是一个明智的选择。当我们由于缺乏关于某个实数上分布的先验知识而不知道该选择怎样的形式时, 正态分布是默认的比较好的选择,其中有两个原因。
第一,我们想要建模的很多分布的真实情况是比较接近正态分布的。中心极限定理 (central limit theorem)说明很多独立随机变量的和近似服从正态分布。这意味着在实际中,很多复杂系统都可以被成功地建模成正态分布的噪声,即使系统可以被分解成一些更结构化的部分。
第二,在具有相同方差的所有可能的概率分布中,正态分布在实数上具有最大的不确定性。因此,我们可以认为正态分布是对模型加入的先验知识量最少的分布
- 多维正态分布:正态分布推广到n维空间
- 指数分布:在深度学习中,我们经常会需要一个在x=0点处取得边界点(sharppoint)的分布。为了实现这一目的,我们可以使用指数分布(exponentialdistribution)

- 混合分布:组合一些简单的概率分布来定义新的概率分布。高斯混合模型是概率密度的万能近似器 (universal approximator),在这种意义下,任何平滑的概率密度都可以用具有足够多组件的高斯混合模型以任意精度来逼近
贝叶斯定理(Bayes' Rule)
在已知P(y|x)时计算P(x|y)
其中
![]()
信息论
基本思想
信息论的核⼼思想是量化数据中的信息内容
- 非常可能发生的事件信息量要比较少,并且极端情况下,确保能够发生的事件应该没有信息量。
- 较不可能发生的事件具有更高的信息量。
- 独立事件应具有增量的信息。例如,投掷的硬币两次正面朝上传递的信息量,应该是投掷一次硬币正面朝上的信息量的两倍
自信息
为了满足上述3个性质,我们定义一个事件x=x 的自信息
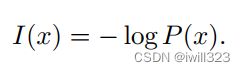
用log来表示自然对数,其底数为e。定义的I(x)单位是奈特 (nats)。一奈特是以 1/e 的概率观测到一个事件时获得的信息量.使用底数为2的对数,单位是比特(bit)或者香农 (shannons);通过比特度量的信息只是通过奈特度量信息的常数倍。
香农熵
自信息只处理单个的输出。我们可以用香农熵 (Shannon entropy)来对整个概率分布中的不确定性总量进行量化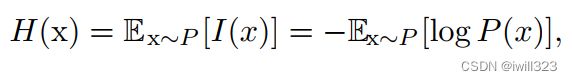
另一种形式:
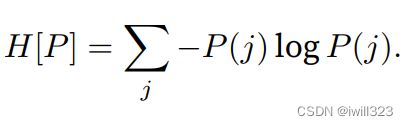
一个分布的香农熵是指遵循这个分布的事件所产生的期望信息总量。香农熵越大,则描述该系统所需的比特数越大,而对于确定性的非随机的系统,其香农熵很小。当x是连续的,香农熵被称为微分熵(differential entropy)
可以把熵H(P)想象为“知道真实概率的人所经历的惊异程度”,想象⼀下,我们有⼀个要压缩的数据流。如果我们很容易预测下⼀个数据,那么这个数据就很容易压缩,因为这个数据信息量很小。但是,如果我们不能完全预测每⼀个数据,那么我们有时可能会感到”惊异”。在观察⼀个事件 j 时赋予它(主观)概率P(j),当我们赋予⼀个事件较低的概率时,我们的惊异会更大,该事件的信息量也就更⼤。香农熵量化了这种惊异程度,是当分配的概率真正匹配数据⽣成过程时的信息量的期望。
KL散度
如果对于同一个随机变量x有两个单独的概率分布P(x)和Q(x),可以使用KL散度 (Kullback-Leibler divergence)来衡量这两个分布的差异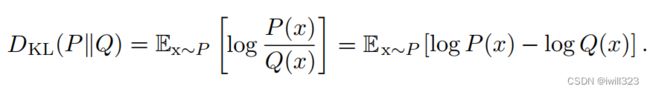
它表示了假如我们采取某种编码方式使编码Q分布所需的比特数最少,那么编码P分布所需的额外的比特数。假如P和Q分布完全相同,则其KL divergence 为零。
KL散度有很多有用的性质,最重要的是,它是非负的。KL散度为0,当且仅当P和Q在离散型变量的情况下是相同的分布,或者在连续型变量的情况下是“几乎处处”相同的。因为KL散度是非负的并且衡量的是两个分布之间的差异,它经常被用作分布之间的某种距离。然而,它并不是真的距离,因为它不是对称的。
交叉熵 ( cross-entropy )
交叉熵从P到Q,记为H(P, Q)。交叉熵和KL散度很像,但是缺少左边一项: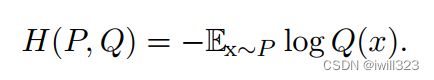
由于第一项H(P)并不包含Q,相对于Q求交叉熵最小与求KL divergence最小化的问题是等价的。
交叉熵是⼀个衡量两个概率分布之间差异的很好的度量,它测量给定模型编码数据所需的⽐特数。可以把交叉熵想象为“主观概率为Q的观察者在看到根据概率P生成的数据时的预期惊异”。当P = Q时,交叉熵达到最低。在这种情况下,从P到Q的交叉熵是H(P, P) = H(P)。
简⽽⾔之,我们可以从两⽅⾯来考虑交叉熵分类⽬标:(i)最⼤化观测数据的似然;(ii)最⼩化传达标签所需的惊异。
数值计算
- 梯度 (gradient)是相对一个向量求导的导数:f的导数是包含所有偏导数的向量,梯度的第i个元素是f关于xi 的偏导数
- 方向导数:在 u (单位向量)方向的方向导数是函数f在 u 方向的斜率
- 梯度下降: 梯度向量指向上坡,负梯度向量指向下坡。在负梯度方向上移动可以减小f。这被称为最速下降法 (method of steepest descent)或梯度下降 (gradient descent).最速下降在梯度的每一个元素为零时收敛(或在实践中,很接近零时)
- Jacobian和Hessian矩阵:有时我们需要计算输入和输出都为向量的函数的所有偏导数。包含所
有这样的偏导数的矩阵被称为Jacobian 矩阵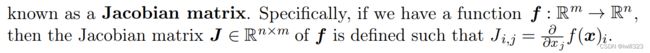
- Hessian 矩阵: 多维输入时二阶导数,可以将其看做梯度的雅可比矩阵
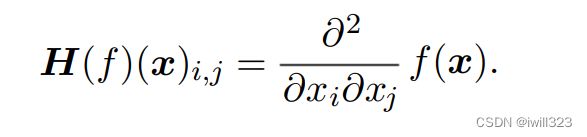
二阶导数是一种对曲线曲率的测量,告诉我们一阶导数将如何随着输入的变化而改变,而一阶梯度下降算法无法利用包含在Hessian矩阵中的曲率信息,它并不知道应该优先探索导数长期为负的方向。如下图所示,梯度下降把时间浪费于在峡谷壁反复下降,因为在每个点来看,红线指示的方向变化最大,于是选择走红线。由于步长有点大,有越过函数底部的趋势,因此需要在下一次迭代时在对面的峡谷壁下降,于是下降速度很慢。
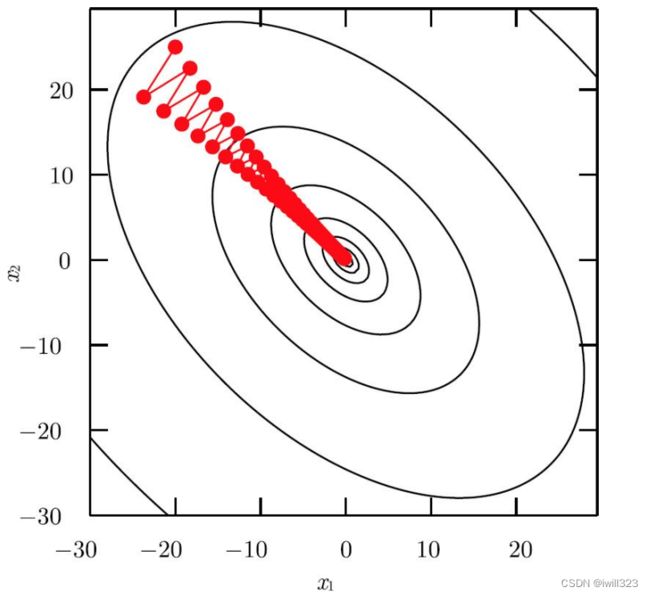
我们如何选取合适的学习率也成了一个难题,某些方向上曲率大,就会产生在曲线的两个山坡上来回振动而不能一直趋近山坳的现象,限制了我们只能选取很小的学习率。
Hessian 矩阵可以用于二阶最优化算法,根据一些资料,计算Hessian 矩阵要使用整个数据集,计算量巨大,很少有人使用。
- 约束优化:有时候,在 x 的所有可能值下最大化或最小化一个函数f(x)不是我们所希望的。相反,我们可能希望在 x 的某些集合中找f(x)的最大值或最小值。集合 内的点 x 称为可行 (feasible)点。可以利用KKT(全称是Karush-Kuhn-Tucker)算法将有限制条件的极值问题转化为无限制条件的极值问题,然后我们就可以用之前处理无限制条件的极值问题的方法来解决这个问题
假设x面临的是等式约束和不等式约束:
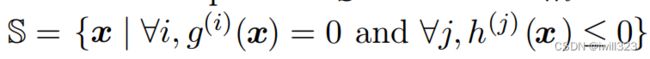
对每一个约束分别引入λ和α,定义一个新的拉格朗日式子
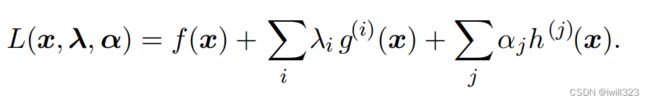
现在,我们可以通过优化无约束的广义Lagrangian解决约束最小化问题,即求出
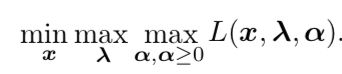
则其得到的极值点与目标是
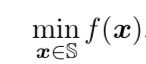
相同的。
拉格朗日式子取极值的必要条件

KKT算法这部分具体参考:线性代数——深度学习花书第二章 - 知乎