Transfomer各组件与Pytorch
参考视频
参考文章
文章目录
- 前言
-
- 结构图
- 关于Q K V的shape
- 字典反转和编码解码
- CrossEntropyLoss(ignore_index=0)
- ModuleList
- zeros(1, 0) vs. zeros(1) vs. zeros([])
- transformer_components
-
- 总体
-
- 应用
- 使用
- 分函数
-
- PositionalEncoding
- ScaledDotProductAttention
- MultiHeadAttention
- PoswiseFeedForwardNet
- EncoderLayer
- Encoder
- DecoderLayer
- Decoder
- get_attn_pad_mask
- get_attn_subsequence_mask
- Transformer
- make_data
- greedy_decode
前言
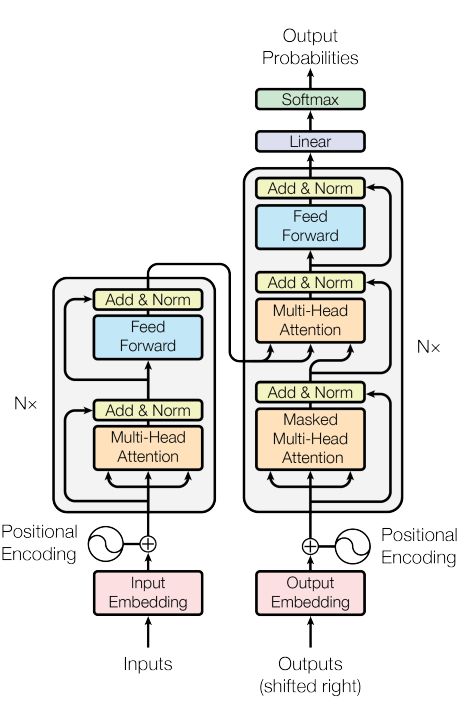
结构图
关于Q K V的shape
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Q [ l e n q , d q ] K [ l e n k , d k ] V [ l e n v , d v ] d q = d k , d v 可 以 不 与 它 们 相 等 l e n k = l e n v , s e l f − a t t e n t i o n l e n q = l e n k = l e n v , c r o s s − a t t e n t i o n l e n q 可 以 不 与 它 们 相 等 e n c o d e r 输 入 [ s r c _ l e n , d _ m o d e l ] d e c o d e r 输 入 [ t g t _ l e n , d _ m o d e l ] s e l f − a t t e n t i o n s r c _ l e n = l e n q = l e n k = l e n v 或 者 t g t _ l e n = l e n q = l e n k = l e n v c r o s s − a t t e n t i o n s r c _ l e n = l e n k = l e n v 且 t g t _ l e n = l e n q Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt d_k})V\\ Q\:[len_q,d_q]\\ K\:[len_k,d_k]\\ V\:[len_v,d_v]\\ d_q=d_k,d_v可以不与它们相等\\ len_k=len_v,self-attention\:len_q=len_k=len_v, cross-attention\:len_q可以不与它们相等\\\\ encoder输入[src\_len, d\_model]\:\:decoder输入[tgt\_len, d\_model]\\ self-attention\:src\_len=len_q=len_k=len_v或者tgt\_len=len_q=len_k=len_v\\\\ cross-attention\:src\_len=len_k=len_v且tgt\_len=len_q Attention(Q,K,V)=softmax(dkQKT)VQ[lenq,dq]K[lenk,dk]V[lenv,dv]dq=dk,dv可以不与它们相等lenk=lenv,self−attentionlenq=lenk=lenv,cross−attentionlenq可以不与它们相等encoder输入[src_len,d_model]decoder输入[tgt_len,d_model]self−attentionsrc_len=lenq=lenk=lenv或者tgt_len=lenq=lenk=lenvcross−attentionsrc_len=lenk=lenv且tgt_len=lenq
字典反转和编码解码
# 字典反转
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
tgt_vocab = {'P': 0, 'i': 1, 'have': 2, 'a': 3, 'good': 4, 'friend': 5, 'zero': 6, 'girl': 7, 'S': 8, 'E': 9, '.': 10}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
idx2word
Out[19]:
{0: 'P', 1: 'i', 2: 'have', 3: 'a', 4: 'good', 5: 'friend', 6: 'zero', 7: 'girl', 8: 'S', 9: 'E', 10: '.'}
# []和[[]]使用示例
sentence = 'S i have zero girl friend .'
[tgt_vocab[n] for n in sentence.split()]
Out[5]: [8, 1, 2, 6, 7, 5, 10]
[[tgt_vocab[n] for n in sentence.split()]]
Out[6]: [[8, 1, 2, 6, 7, 5, 10]]
# 句子str首先使用词库转化为int sequence并padding至指定长度,然后 使用nn.Embedding或查表 转化为embedding sequence(P S E也会转化)
# (encoder的输入包含P,decoder的输入包含P S E)
# embedding sequence输入encoder和decoder,输出embedding sequence
# decoder output embedding sequence经过Linear+Softmax,将embedding的维度变为词库的长度,其中最大值的位置即为预测值
# 通过最大值的位置embedding sequence转换为int sequence,使用词库再转换为str
import torch
def make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len):
"""
str->int sequence,并padding至指定长度
Args:
:param sentences: 输入数据[batch_size, 3]
:param src_vocab:源语言词库
:param src_len:enc_input max sequence length(编码器的输入 str->int sequence后需要padding至该长度)
:param tgt_vocab:目的语言词库
:param tgt_len:dec_input(=dec_output) max sequence length(解码器的输入 str->int sequence后需要padding至该长度)
Returns:
torch.LongTensor(enc_inputs): [batch_size, src_len]
torch.LongTensor(dec_inputs): [batch_size, tgt_len]
torch.LongTensor(dec_outputs): [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
enc_input.extend([src_vocab['P']] * (src_len - enc_input.__len__()))
dec_input.extend([tgt_vocab['P']] * (tgt_len - dec_input.__len__()))
dec_output.extend([tgt_vocab['P']] * (tgt_len - dec_output.__len__()))
enc_inputs.append(enc_input)
dec_inputs.append(dec_input)
dec_outputs.append(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
sentences = [
# 中文和英语的单词个数不要求相同
# enc_input dec_input dec_output
['我 有 一 个 好 朋 友', 'S i have a good friend .', 'i have a good friend . E'],
['我 有 零 个 女 朋 友', 'S i have zero girl friend .', 'i have zero girl friend . E']
]
src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3, '个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9}
tgt_vocab = {'P': 0, 'i': 1, 'have': 2, 'a': 3, 'good': 4, 'friend': 5, 'zero': 6, 'girl': 7, 'S': 8, 'E': 9, '.': 10}
src_len = 8 # enc_input max sequence length(编码器的输入 str->int sequence后需要padding至该长度)
tgt_len = 7 # dec_input(=dec_output) max sequence length(解码器的输入 str->int sequence后需要padding至该长度)
print(make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len))
# (tensor([[1, 2, 3, 4, 5, 6, 7, 0], [1, 2, 8, 4, 9, 6, 7, 0]]),
# tensor([[ 8, 1, 2, 3, 4, 5, 10], [ 8, 1, 2, 6, 7, 5, 10]]),
# tensor([[ 1, 2, 3, 4, 5, 10, 9], [ 1, 2, 6, 7, 5, 10, 9]]))
CrossEntropyLoss(ignore_index=0)
# 交叉熵损失,若第0类的预测值最高,则忽略该项的损失
criterion1 = nn.CrossEntropyLoss(ignore_index=0)
criterion2 = nn.CrossEntropyLoss()
out = torch.randn(2, 5)
label = torch.tensor([0,1])
criterion2(torch.unsqueeze(out[0], dim=0), torch.unsqueeze(label[0], dim=0))
Out[66]: tensor(1.8557)
criterion2(torch.unsqueeze(out[1], dim=0), torch.unsqueeze(label[1], dim=0))
Out[67]: tensor(3.3811)
criterion2(out, label)
Out[68]: tensor(2.6184)
(1.8557+3.3811) / 2
Out[69]: 2.6184
criterion1(out, label)
Out[70]: tensor(3.3811)
ModuleList
# t为含有10个线性层的列表
t = nn.ModuleList([nn.Linear(100, 10, True) for _ in range(10)])
print(t)
ModuleList(
(0): Linear(in_features=100, out_features=10, bias=True)
(1): Linear(in_features=100, out_features=10, bias=True)
(2): Linear(in_features=100, out_features=10, bias=True)
(3): Linear(in_features=100, out_features=10, bias=True)
(4): Linear(in_features=100, out_features=10, bias=True)
(5): Linear(in_features=100, out_features=10, bias=True)
(6): Linear(in_features=100, out_features=10, bias=True)
(7): Linear(in_features=100, out_features=10, bias=True)
(8): Linear(in_features=100, out_features=10, bias=True)
(9): Linear(in_features=100, out_features=10, bias=True)
)
zeros(1, 0) vs. zeros(1) vs. zeros([])
torch.zeros(1)
Out[15]: tensor([0.])
torch.zeros([])
Out[17]: tensor(0.)
torch.zeros(1, 0)
Out[16]: tensor([], size=(1, 0))
transformer_components
总体
应用
# transformer_components.py
import torch
import torch.nn as nn
import math
import numpy as np
def make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len):
"""
str->int sequence,并padding至指定长度
Args:
:param sentences: 输入数据[batch_size, 3]
:param src_vocab:源语言词库
:param src_len:enc_input max sequence length(编码器的输入 str->int sequence后需要padding至该长度)
:param tgt_vocab:目的语言词库
:param tgt_len:dec_input(=dec_output) max sequence length(解码器的输入 str->int sequence后需要padding至该长度)
Returns:
torch.LongTensor(enc_inputs): [batch_size, src_len]
torch.LongTensor(dec_inputs): [batch_size, tgt_len]
torch.LongTensor(dec_outputs): [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
enc_input.extend([src_vocab['P']] * (src_len - enc_input.__len__()))
dec_input.extend([tgt_vocab['P']] * (tgt_len - dec_input.__len__()))
dec_output.extend([tgt_vocab['P']] * (tgt_len - dec_output.__len__()))
enc_inputs.append(enc_input)
dec_inputs.append(dec_input)
dec_outputs.append(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
class PositionalEncoding(nn.Module):
"""
添加位置编码
"""
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
Args:
d_model: Embedding Size(token embedding和position编码的维度)
dropout: dropout
max_len: 可以处理的最大seq_len
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# pos x 2i x -ln10000 / d = pos x (-2i/d) x ln10000 = pos x ln[(1/10000)^(2i/d)] 比原论文公式多了一个ln,但不影响
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: shape [batch_size, seq_len, d_model]
Returns:
添加位置编码后的x shape [batch_size, seq_len, d_model]
"""
x = x + self.pe[:x.size(1), :]
return self.dropout(x)
class ScaledDotProductAttention(nn.Module):
"""
计算softmax(QK^T/sqrt(d_k))V
"""
def __init__(self, d_qk, d_v):
"""
Args:
d_qk: d_q/t_k
d_v: d_v
"""
super(ScaledDotProductAttention, self).__init__()
self.d_qk = d_qk
self.d_v = d_v
def forward(self, Q, K, V, attn_mask):
"""
Args:
Q: [batch_size, n_heads, len_q, d_qk]
K: [batch_size, n_heads, len_kv, d_qk]
V: [batch_size, n_heads, len_kv, d_v]
attn_mask: [batch_size, n_heads, len_q, len_kv] Ture/False
以cross-attention为例,K/V embedding sequence中的某些embedding是由padding符号对应而来的,不能对其计算注意力,
Q@K [len_q, len_kv]表示每个q对每个k的注意力,attn_mask的shape也为[len_q, len_kv]
将attn_mask中k是padding来的对应项标记为True,这样其中有几列全为True(即mask)
将Q@K中attn_mask对应位置为true的位置赋予极小值,然后经过softmax后该位置将变为0,即不考虑每个q对由padding符号对应而来的k的注意力
Returns:
context: [batch_size, n_heads, len_q, d_v]
atten: [batch_size, n_heads, len_q, len_kv] float
[len_q, len_kv]每行和为1 且 K被mask的位置为0
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_qk)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
class MultiHeadAttention(nn.Module):
"""
[Masked] Multi-Head Attention + Add&Norm
"""
def __init__(self, d_qk, d_v, d_model, n_heads):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
"""
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.d_qk = d_qk
self.d_v = d_v
self.n_heads = n_heads
self.W_Q = nn.Linear(d_model, d_qk * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_qk * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
Args:
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_kv, d_model]
input_V: [batch_size, len_kv, d_model]
attn_mask: [batch_size, len_q, len_kv]
Returns:
output: [batch_size, len_q, d_model]
attn: [batch_size, n_heads, len_q, len_kv]
"""
residual, batch_size = input_Q, input_Q.size(0)
# Q: [batch_size, n_heads, len_q, d_qk]
Q = self.W_Q(input_Q).view(batch_size, -1, self.n_heads, self.d_qk).transpose(1, 2)
# K: [batch_size, n_heads, len_kv, d_qk]
K = self.W_K(input_K).view(batch_size, -1, self.n_heads, self.d_qk).transpose(1, 2)
# V: [batch_size, n_heads, len_kv, d_v]
V = self.W_V(input_V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2)
# attn_mask: [batch_size, len_q, len_kv] -> [batch_size, n_heads, len_q, len_kv]
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1)
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_kv]
context, attn = ScaledDotProductAttention(self.d_qk, self.d_v)(Q, K, V, attn_mask)
# context: [batch_size, n_heads, len_q, d_v] -> [batch_size, len_q, n_heads * d_v]
context = context.transpose(1, 2).reshape(batch_size, -1, self.n_heads * self.d_v)
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(self.d_model)(output + residual), attn
class PoswiseFeedForwardNet(nn.Module):
"""
Feed Forward + Add&Norm
"""
def __init__(self, d_model, d_ff):
"""
Args:
d_model: Embedding Size
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(PoswiseFeedForwardNet, self).__init__()
self.d_model = d_model
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
Args:
inputs: [batch_size, seq_len, d_model]
Returns:
outputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(self.d_model)(output + residual)
class EncoderLayer(nn.Module):
"""
EncoderLayer
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.pos_ffn = PoswiseFeedForwardNet(d_model, d_ff)
def forward(self, enc_inputs, enc_self_attn_mask):
"""
Args:
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask)
Returns:
enc_outputs: [batch_size, src_len, d_model]
attn: [batch_size, n_heads, src_len, src_len]
"""
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn
def get_attn_pad_mask(seq_q, seq_k, k_vocab):
"""
seq_q为查询一方的int sequence,seq_k为被查询一方的int sequence,其中均可能包含padding(本程序中为padding对应的数字0)
seq_q对seq_k注意力矩阵的大小为[len1, len2],
seq_q不应该对seq_k中的padding产生注意力,所以构造一个同样为[len1, len2]的矩阵,将其中seq_k为padding的位置标记为True,
这样该矩阵中后几列为True,在后面计算注意力矩阵时将为True的位置置为0,即不考虑对seq_k中padding位置的注意力
Args:
seq_q: [batch_size, len1] 此时的内容为int sequence
seq_k: [batch_size, len2] 此时的内容为int sequence
k_vocab: seq_k所使用的字典
Returns:
[batch_size, len1, len2]
"""
batch_size, len1 = seq_q.size()
batch_size, len2 = seq_k.size()
pad_attn_mask = seq_k.data.eq(k_vocab['P']).unsqueeze(1)
return pad_attn_mask.expand(batch_size, len1, len2)
def get_attn_subsequence_mask(seq):
"""
decoder input sequence,前面的embedding不应该看到后面的embedding的信息,所以应该mask
Args:
seq: [batch_size, tgt_len]
Returns:
subsequence_mask: [batch_size, tgt_len, tgt_len] 右上三角矩阵(不包括主对角线)为1,其他为0(1位置为遮盖)
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
class Encoder(nn.Module):
"""
int sequence -> embedding sequence
add positional encoding
N * Encoder Layer (notice enc_self_attn_mask)
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab):
"""
Args:
d_qk: d_q/q_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
n_layers: EncoderLayer的层数
src_vocab: 源语言词库
"""
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(len(src_vocab), d_model) # token Embedding
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer(d_qk, d_v, d_model, n_heads, d_ff) for _ in range(n_layers)])
self.src_vocab = src_vocab
def forward(self, enc_inputs):
"""
Args:
enc_inputs: [batch_size, src_len]
Returns:
enc_outputs: [batch_size, src_len, d_model]
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
"""
# int sequence -> embedding sequence
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
# 添加位置编码
enc_outputs = self.pos_emb(enc_outputs) # [batch_size, src_len, d_model]
# Encoder输入序列的pad mask矩阵
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs, self.src_vocab) # [batch_size, src_len, src_len]
# 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系)
enc_self_attns = []
for layer in self.layers:
# 上一个block的输出enc_outputs作为当前block的输入
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
class DecoderLayer(nn.Module):
"""
Decoder Layer
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.dec_enc_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.pos_ffn = PoswiseFeedForwardNet(d_model, d_ff)
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
Args:
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
Returns:
dec_outputs: [batch_size, tgt_len, d_model]
dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
"""
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask) # 这里的Q,K,V全是Decoder自己的输入
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask) # Attention层的Q(来自decoder) 和 K,V(来自encoder)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn # dec_self_attn, dec_enc_attn这两个是为了可视化的
class Decoder(nn.Module):
"""
int sequence -> embedding sequence
add positional encoding
N * Dncoder Layer (notice dec_self_attn_mask = dec_self_attn_pad_mask + dec_self_attn_subsequence_mask
dec_enc_attn_mask)
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
n_layers: EncoderLayer的层数
src_vocab: 源语言词库
tgt_vocab: 目标语言词库
"""
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(len(tgt_vocab), d_model) # Decoder输入的embed词表
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer(d_qk, d_v, d_model, n_heads, d_ff) for _ in range(n_layers)])
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
Args:
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len] 用来计算mask
enc_outputs: [batch_size, src_len, d_model]
Returns:
dec_outputs: [batch_size, tgt_len, d_model]
dec_self_attn: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [n_layers, batch_size, h_heads, tgt_len, src_len]
"""
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs) # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs, self.tgt_vocab) # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0) # [batch_size, tgt_len, tgt_len]; torch.gt比较两个矩阵的元素,大于则返回1,否则返回0
# 这个mask主要用于encoder-decoder attention层
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs, self.src_vocab) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
class Transformer(nn.Module):
"""
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab):
super(Transformer, self).__init__()
self.encoder = Encoder(d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab)
self.decoder = Decoder(d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab)
self.projection = nn.Linear(d_model, len(tgt_vocab), bias=True)
def forward(self, enc_inputs, dec_inputs):
"""
Args:
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
Returns:
dec_logits: [batch_size*tgt_len, len(tgt_vocab)]
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
dec_self_attn: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [n_layers, batch_size, h_heads, tgt_len, src_len]
"""
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
# [batch_size, tgt_len, d_model] -> [batch_size, tgt_len, len(tgt_vocab)]
dec_logits = self.projection(dec_outputs)
dec_logits = dec_logits.view(-1, dec_logits.size(-1))
return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
def greedy_decoder(model, enc_input, tgt_vocab):
"""
顺序解码,测试时使用
Args:
model: 模型
enc_input: [1, src_len]
tgt_vocab: 目标语言词库
Returns:
"""
# 编码器编码
# [1, src_len, d_model]
enc_outputs, enc_self_attns = model.encoder(enc_input)
# tensor([], size=(1, 0), dtype=torch.int64)
dec_input = torch.zeros(1, 0).type_as(enc_input.data)
# 首先存入开始符号S
next_symbol = tgt_vocab['S']
terminal = False
while not terminal:
# 预测阶段:dec_input序列会一点点变长(每次添加一个新预测出来的单词)
# torch.tensor([[next_symbol]], dtype=enc_input.dtype).shape Out[4]: torch.Size([1, 1])
# dec_input [1, src_len_cur]
dec_input = torch.cat([dec_input, torch.tensor([[next_symbol]], dtype=enc_input.dtype)], -1)
# dec_input [1, src_len_cur, d_model]
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
# projected [1, src_len_cur, len(tgt_vocab)]
projected = model.projection(dec_outputs)
# prob [len(tgt_vocab)] [1]=.indices
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
# 增量更新(我们希望重复单词预测结果是一样的)
# 我们在预测是会选择性忽略重复的预测的词,只摘取最新预测的单词拼接到输入序列中
next_word = prob.data[-1]
next_symbol = next_word
if next_symbol == tgt_vocab["E"]:
terminal = True
# 截去start_symbol
greedy_dec_predict = dec_input[:, 1:]
return greedy_dec_predict
使用
from transformer_components import *
import torch.optim as optim
import torch.utils.data as Data
epochs = 20
src_len = 8 # enc_input max sequence length(编码器的输入 str->int sequence后需要padding至该长度)
tgt_len = 7 # dec_input(=dec_output) max sequence length(解码器的输入 str->int sequence后需要padding至该长度)
# Transformer Parameters
d_model = 512 # Embedding Size(token embedding和position编码的维度)
d_ff = 2048 # FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的),当然最后会再接一个projection层
d_qk = d_v = 64 # d_q=d_k,d_v可以不与它们相等(这里为了方便取d_k=d_v)
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
# ====================================================================================================
# 数据处理
sentences = [
# 中文和英语的单词个数不要求相同
# enc_input dec_input dec_output
['我 有 一 个 好 朋 友', 'S i have a good friend .', 'i have a good friend . E'],
['我 有 零 个 女 朋 友', 'S i have zero girl friend .', 'i have zero girl friend . E']
]
# 中文词库
# Padding Should be Zero
src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3, '个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9}
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
# 英文词库
tgt_vocab = {'P': 0, 'i': 1, 'have': 2, 'a': 3, 'good': 4, 'friend': 5, 'zero': 6, 'girl': 7, 'S': 8, 'E': 9, '.': 10}
tgt_idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len)
class MyDataSet(Data.Dataset):
"""自定义DataLoader"""
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
# ====================================================================================================
# Transformer模型
model = Transformer(d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab)
criterion = nn.CrossEntropyLoss(ignore_index=tgt_vocab['P'])
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99) # 用adam的话效果不好
# ====================================================================================================
# 训练
for epoch in range(epochs):
for enc_inputs, dec_inputs, dec_outputs in loader:
"""
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
"""
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
# dec_outputs.view(-1):[batch_size * tgt_len * tgt_vocab_size]
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ==========================================================================================
# 预测
# 测试集
sentences = [
# enc_input dec_input dec_output
['我 有 零 个 女 朋 友', '', '']
]
enc_inputs, dec_inputs, dec_outputs = make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len)
enc_input = enc_inputs[0]
print("\n"+"="*30)
greedy_dec_predict = greedy_decoder(model, enc_input.view(1, -1), tgt_vocab)
print(enc_inputs, '->', greedy_dec_predict.squeeze())
print([src_idx2word[t.item()] for t in enc_input], '->', [tgt_idx2word[n.item()] for n in greedy_dec_predict.squeeze()])
分函数
PositionalEncoding
class PositionalEncoding(nn.Module):
"""
添加位置编码
"""
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
Args:
d_model: Embedding Size(token embedding和position编码的维度)
dropout: dropout
max_len: 可以处理的最大seq_len
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# pos x 2i x -ln10000 / d = pos x (-2i/d) x ln10000 = pos x ln[(1/10000)^(2i/d)] 比原论文公式多了一个ln,但不影响
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: shape [batch_size, seq_len, d_model]
Returns:
添加位置编码后的x shape [batch_size, seq_len, d_model]
"""
x = x + self.pe[:x.size(1), :]
return self.dropout(x)
ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
"""
计算softmax(QK^T/sqrt(d_k))V
"""
def __init__(self, d_qk, d_v):
"""
Args:
d_qk: d_q/t_k
d_v: d_v
"""
super(ScaledDotProductAttention, self).__init__()
self.d_qk = d_qk
self.d_v = d_v
def forward(self, Q, K, V, attn_mask):
"""
Args:
Q: [batch_size, n_heads, len_q, d_qk]
K: [batch_size, n_heads, len_kv, d_qk]
V: [batch_size, n_heads, len_kv, d_v]
attn_mask: [batch_size, n_heads, len_q, len_kv] Ture/False
以cross-attention为例,K/V embedding sequence中的某些embedding是由padding符号对应而来的,不能对其计算注意力,
Q@K [len_q, len_kv]表示每个q对每个k的注意力,attn_mask的shape也为[len_q, len_kv]
将attn_mask中k是padding来的对应项标记为True,这样其中有几列全为True(即mask)
将Q@K中attn_mask对应位置为true的位置赋予极小值,然后经过softmax后该位置将变为0,即不考虑每个q对由padding符号对应而来的k的注意力
Returns:
context: [batch_size, n_heads, len_q, d_v]
atten: [batch_size, n_heads, len_q, len_kv] float
[len_q, len_kv]每行和为1 且 K被mask的位置为0
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_qk)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
MultiHeadAttention
class MultiHeadAttention(nn.Module):
"""
[Masked] Multi-Head Attention + Add&Norm
"""
def __init__(self, d_qk, d_v, d_model, n_heads):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
"""
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.d_qk = d_qk
self.d_v = d_v
self.n_heads = n_heads
self.W_Q = nn.Linear(d_model, d_qk * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_qk * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
Args:
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_kv, d_model]
input_V: [batch_size, len_kv, d_model]
attn_mask: [batch_size, len_q, len_kv]
Returns:
output: [batch_size, len_q, d_model]
attn: [batch_size, n_heads, len_q, len_kv]
"""
residual, batch_size = input_Q, input_Q.size(0)
# Q: [batch_size, n_heads, len_q, d_qk]
Q = self.W_Q(input_Q).view(batch_size, -1, self.n_heads, self.d_qk).transpose(1, 2)
# K: [batch_size, n_heads, len_kv, d_qk]
K = self.W_K(input_K).view(batch_size, -1, self.n_heads, self.d_qk).transpose(1, 2)
# V: [batch_size, n_heads, len_kv, d_v]
V = self.W_V(input_V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2)
# attn_mask: [batch_size, len_q, len_kv] -> [batch_size, n_heads, len_q, len_kv]
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1)
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_kv]
context, attn = ScaledDotProductAttention(self.d_qk, self.d_v)(Q, K, V, attn_mask)
# context: [batch_size, n_heads, len_q, d_v] -> [batch_size, len_q, n_heads * d_v]
context = context.transpose(1, 2).reshape(batch_size, -1, self.n_heads * self.d_v)
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(self.d_model)(output + residual), attn
PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):
"""
Feed Forward + Add&Norm
"""
def __init__(self, d_model, d_ff):
"""
Args:
d_model: Embedding Size
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(PoswiseFeedForwardNet, self).__init__()
self.d_model = d_model
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
Args:
inputs: [batch_size, seq_len, d_model]
Returns:
outputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(self.d_model)(output + residual)
EncoderLayer
class EncoderLayer(nn.Module):
"""
EncoderLayer
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.pos_ffn = PoswiseFeedForwardNet(d_model, d_ff)
def forward(self, enc_inputs, enc_self_attn_mask):
"""
Args:
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask)
Returns:
enc_outputs: [batch_size, src_len, d_model]
attn: [batch_size, n_heads, src_len, src_len]
"""
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn
Encoder
注意其中使用了 源语言字典src_vocab
class Encoder(nn.Module):
"""
int sequence -> embedding sequence
add positional encoding
N * Encoder Layer (notice enc_self_attn_mask)
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab):
"""
Args:
d_qk: d_q/q_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
n_layers: EncoderLayer的层数
src_vocab: 源语言词库
"""
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(len(src_vocab), d_model) # token Embedding
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer(d_qk, d_v, d_model, n_heads, d_ff) for _ in range(n_layers)])
self.src_vocab = src_vocab
def forward(self, enc_inputs):
"""
Args:
enc_inputs: [batch_size, src_len]
Returns:
enc_outputs: [batch_size, src_len, d_model]
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
"""
# int sequence -> embedding sequence
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
# 添加位置编码
enc_outputs = self.pos_emb(enc_outputs) # [batch_size, src_len, d_model]
# Encoder输入序列的pad mask矩阵
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs, self.src_vocab) # [batch_size, src_len, src_len]
# 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系)
enc_self_attns = []
for layer in self.layers:
# 上一个block的输出enc_outputs作为当前block的输入
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
DecoderLayer
class DecoderLayer(nn.Module):
"""
Decoder Layer
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
"""
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.dec_enc_attn = MultiHeadAttention(d_qk, d_v, d_model, n_heads)
self.pos_ffn = PoswiseFeedForwardNet(d_model, d_ff)
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
Args:
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
Returns:
dec_outputs: [batch_size, tgt_len, d_model]
dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
"""
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask) # 这里的Q,K,V全是Decoder自己的输入
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask) # Attention层的Q(来自decoder) 和 K,V(来自encoder)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn # dec_self_attn, dec_enc_attn这两个是为了可视化的
Decoder
注意其中使用了 源语言字典src_vocab 和 目标语言字典tgt_vocab
class Decoder(nn.Module):
"""
int sequence -> embedding sequence
add positional encoding
N * Dncoder Layer (notice dec_self_attn_mask = dec_self_attn_pad_mask + dec_self_attn_subsequence_mask
dec_enc_attn_mask)
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab):
"""
Args:
d_qk: d_q/d_k
d_v: d_v
d_model: Embedding Size
n_heads: number of heads in Multi-Head Attention
d_ff: FeedForward dimension (d_model->d_ff->d_model,线性层是用来做特征提取的)
n_layers: EncoderLayer的层数
src_vocab: 源语言词库
tgt_vocab: 目标语言词库
"""
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(len(tgt_vocab), d_model) # Decoder输入的embed词表
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer(d_qk, d_v, d_model, n_heads, d_ff) for _ in range(n_layers)])
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
Args:
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len] 用来计算mask
enc_outputs: [batch_size, src_len, d_model]
Returns:
dec_outputs: [batch_size, tgt_len, d_model]
dec_self_attn: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [n_layers, batch_size, h_heads, tgt_len, src_len]
"""
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs) # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs,
self.tgt_vocab) # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0) # [batch_size, tgt_len, tgt_len]; torch.gt比较两个矩阵的元素,大于则返回1,否则返回0
# 这个mask主要用于encoder-decoder attention层
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs, self.src_vocab) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
get_attn_pad_mask
注意其中使用了被查询一侧的 字典k_vocab
def get_attn_pad_mask(seq_q, seq_k, k_vocab):
"""
seq_q为查询一方的int sequence,seq_k为被查询一方的int sequence,其中均可能包含padding(本程序中为padding对应的数字0)
seq_q对seq_k注意力矩阵的大小为[len1, len2],
seq_q不应该对seq_k中的padding产生注意力,所以构造一个同样为[len1, len2]的矩阵,将其中seq_k为padding的位置标记为True,
这样该矩阵中后几列为True,在后面计算注意力矩阵时将为True的位置置为0,即不考虑对seq_k中padding位置的注意力
Args:
seq_q: [batch_size, len1] 此时的内容为int sequence
seq_k: [batch_size, len2] 此时的内容为int sequence
k_vocab: seq_k所使用的字典
Returns:
[batch_size, len1, len2]
"""
batch_size, len1 = seq_q.size()
batch_size, len2 = seq_k.size()
pad_attn_mask = seq_k.data.eq(k_vocab['P']).unsqueeze(1)
return pad_attn_mask.expand(batch_size, len1, len2)
get_attn_subsequence_mask
def get_attn_subsequence_mask(seq):
"""
decoder input sequence,前面的embedding不应该看到后面的embedding的信息,所以应该mask
Args:
seq: [batch_size, tgt_len]
Returns:
subsequence_mask: [batch_size, tgt_len, tgt_len] 右上三角矩阵(不包括主对角线)为1,其他为0(1位置为遮盖)
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
Transformer
注意其中使用了 源语言字典src_vocab 和 目标语言字典tgt_vocab
class Transformer(nn.Module):
"""
"""
def __init__(self, d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab):
super(Transformer, self).__init__()
self.encoder = Encoder(d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab)
self.decoder = Decoder(d_qk, d_v, d_model, n_heads, d_ff, n_layers, src_vocab, tgt_vocab)
self.projection = nn.Linear(d_model, len(tgt_vocab), bias=True)
def forward(self, enc_inputs, dec_inputs):
"""
Args:
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
Returns:
dec_logits: [batch_size*tgt_len, len(tgt_vocab)]
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
dec_self_attn: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_enc_attn: [n_layers, batch_size, h_heads, tgt_len, src_len]
"""
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
# [batch_size, tgt_len, d_model] -> [batch_size, tgt_len, len(tgt_vocab)]
dec_logits = self.projection(dec_outputs)
dec_logits = dec_logits.view(-1, dec_logits.size(-1))
return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
make_data
注意其中使用了 源语言字典src_vocab 和 目标语言字典tgt_vocab
def make_data(sentences, src_vocab, src_len, tgt_vocab, tgt_len):
"""
str->int sequence,并padding至指定长度
Args:
:param sentences: 输入数据[batch_size, 3]
:param src_vocab:源语言词库
:param src_len:enc_input max sequence length(编码器的输入 str->int sequence后需要padding至该长度)
:param tgt_vocab:目的语言词库
:param tgt_len:dec_input(=dec_output) max sequence length(解码器的输入 str->int sequence后需要padding至该长度)
Returns:
torch.LongTensor(enc_inputs): [batch_size, src_len]
torch.LongTensor(dec_inputs): [batch_size, tgt_len]
torch.LongTensor(dec_outputs): [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
enc_input.extend([src_vocab['P']] * (src_len - enc_input.__len__()))
dec_input.extend([tgt_vocab['P']] * (tgt_len - dec_input.__len__()))
dec_output.extend([tgt_vocab['P']] * (tgt_len - dec_output.__len__()))
enc_inputs.append(enc_input)
dec_inputs.append(dec_input)
dec_outputs.append(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
greedy_decode
def greedy_decoder(model, enc_input, tgt_vocab):
"""
顺序解码,测试时使用
Args:
model: 模型
enc_input: [1, src_len]
tgt_vocab: 目标语言词库
Returns:
"""
# 编码器编码
# [1, src_len, d_model]
enc_outputs, enc_self_attns = model.encoder(enc_input)
# tensor([], size=(1, 0), dtype=torch.int64)
dec_input = torch.zeros(1, 0).type_as(enc_input.data)
# 首先存入开始符号S
next_symbol = tgt_vocab['S']
terminal = False
while not terminal:
# 预测阶段:dec_input序列会一点点变长(每次添加一个新预测出来的单词)
# torch.tensor([[next_symbol]], dtype=enc_input.dtype).shape Out[4]: torch.Size([1, 1])
# dec_input [1, src_len_cur]
dec_input = torch.cat([dec_input, torch.tensor([[next_symbol]], dtype=enc_input.dtype)], -1)
# dec_input [1, src_len_cur, d_model]
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
# projected [1, src_len_cur, len(tgt_vocab)]
projected = model.projection(dec_outputs)
# prob [len(tgt_vocab)] [1]=.indices
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
# 增量更新(我们希望重复单词预测结果是一样的)
# 我们在预测是会选择性忽略重复的预测的词,只摘取最新预测的单词拼接到输入序列中
next_word = prob.data[-1]
next_symbol = next_word
if next_symbol == tgt_vocab["E"]:
terminal = True
# 截去start_symbol
greedy_dec_predict = dec_input[:, 1:]
return greedy_dec_predict