PyTorch的各个组件和实战
文章目录
-
- 张量
-
- 张量简介
- 创建tensor
- 张量的操作
- 广播机制
- 自动求导
- 并行计算简介
- PyTorch的各个组件
-
- 基本配置
- 数据读入
- 模型构建
-
- 神经网络的构造
- 神经网络中常见的层
- 模型初始化
- 损失函数
- 训练和评估
- 可视化
- 优化器
- Fashion-Minist多分类实战
-
- 基本配置
-
- 导入必要的包
- 配置超参数和训练环境
- 数据读入和加载
-
- 设计转换器
- 读入csv格式的数据,自行构建Dataset类
- 使用DataLoader类加载数据
- 数据可视化,验证我们读入的数据是否正确
- 模型设计
- 设定损失函数
- 设定优化器
- 训练和测试(验证)
-
- 训练
- 测试(验证)
张量
张量简介
- 0维张量:标量
- 1维张量:向量
- 2维张量:矩阵
- n维张量(如3维张量彩色图片RGB)
一些存储在各种类型张量的公用数据集类型:
- 3维 = 时间序列
- 4维 = 图像(不止包括width, height, channel,一般还包括图片数量即样本数sample_size)
- 5维 = 视频
创建tensor
| Tensor(sizes) | 基础构造函数 |
|---|---|
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成steps份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
- 可以通过
dtype设置数据类型。
张量的操作
加法操作
x+y#方式1
torch.add(x,y)#方式2
y.add_(x)#方式3,把x+y赋给y
索引操作(类似于numpy)
- 索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用
.copy()等方法。
维度变换
- 改变一个 tensor 的大小或者形状:
.view()(共享内存)- 如果需要改变维度的同时开辟新的内存:用
.clone()方法构建张量副本,然后用.view()方法进行维度变换。
取值操作
- 可以使用
.item()来获取tensor内部某个元素的精确值
广播机制
同numpy
自动求导
如果设置tensor的requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用.backward()来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
- 注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数(即 y.backward() 和 y.backward(torch.tensor(1.)) 等价);否则,需要传入一个与 y 同形的tensor。
- 要阻止一个张量被跟踪历史,可以调用
.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。 - 还有一个类对于
autograd的实现非常重要:Function。Tensor 和 Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是None)。 .requires_grad_(...)可以原地改变现有张量的requires_grad标志。如果没有指定的话,默认输入的这个标志是False。- 注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
- 如果我们想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么我们可以对
tensor.data进行操作。
并行计算简介
- 在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
- CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。而在PyTorch使用 CUDA 表示要开始要求我们的模型或者数据开始使用GPU了——在编写程序中,当我们使用了
cuda()时,其功能是让我们的模型或者数据迁移到GPU当中,通过GPU开始计算。 - 常见的并行的方法
- 网络结构分布到不同的设备中(Network partitioning)
- 同一层的任务分布到不同数据中(Layer-wise partitioning)
- 不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)(主流)
PyTorch的各个组件
基本配置
- 导包
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
import torch.optim as optimizer
- 设置一些基本的超参数
batch_size=20#batch size
lr=1e-4#初始学习率(初始)
max_epochs=100#训练次数
#GPU设置
#方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ["CUDA_VISIBLE_DEVICES"]="0"
#方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device=torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
数据读入
- Dataset+DataLoader
Dataset
- 方法一:使用pytorch自带的Dataset类如
datasets.ImageFolder() - 方法二:自己定义Dataset类
DataLoader
batch_size:每次读入的样本数num_workers:有多少个进程用于读取数据shuffle:是否将读入的数据打乱drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
模型构建
神经网络的构造
- PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活。Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。
神经网络中常见的层
自定义层:
- 不含模型参数的层
- 含模型参数的层
常见的层:
- 全连接层
- 卷积层
- 池化层
- 循环层
模型示例:
- LeNet
- AlexNet
模型初始化
-
torch.nn.init提供了常用的初始化方法,如:torch.nn.init.uniform_(tensor, a=0.0, b=1.0)torch.nn.init.normal_(tensor, mean=0.0, std=1.0)torch.nn.init.constant_(tensor, val)torch.nn.init.ones_(tensor)torch.nn.init.zeros_(tensor)torch.nn.init.eye_(tensor)
-
通常使用
isinstance()来进行判断模块属于什么类型,对于不同的类型层,我们就可以设置不同的权值初始化的方法。 -
人们常常将各种初始化方法定义为一个
initialize_weights()的函数并在模型初始后进行使用。
损失函数
- 二分类交叉熵损失函数
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction=‘mean’)- 功能:计算二分类任务时的交叉熵(Cross Entropy)函数。
- 交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean’)- 功能:计算交叉熵(Cross Entropy)函数。
- L1损失函数
torch.nn.L1Loss(size_average=None, reduce=None, reduction=‘mean’)- 功能: 计算输出 y 和真实标签 target 之间的差值的绝对值。
- MSE损失函数
torch.nn.MSELoss(size_average=None, reduce=None, reduction=‘mean’)- 功能:计算输出 y 和真实标签 target 之差的平方。
- 平滑L1 (Smooth L1)损失函数
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction=‘mean’, beta=1.0)- 功能:L1的平滑输出,其功能是减轻离群点带来的影响。
- 目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction=‘mean’)- 功能:泊松分布的负对数似然损失函数。
- KL散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction=‘mean’, log_target=False)- 功能:计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
- MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction=‘mean’)- 功能:计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
- 多标签边界损失函数
torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction=‘mean’)- 功能:对于多标签分类问题计算损失函数。
- 二分类损失函数
torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction=‘mean’)torch.nn.(size_average=None, reduce=None, reduction=‘mean’)- 功能: 计算二分类的 logistic 损失。
- 多分类的折页损失
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction=‘mean’)- 功能:计算多分类的折页损失。
- 三元组损失
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction=‘mean’)- 功能: 计算三元组损失。
- HingEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction=‘mean’)- 功能:对输出的embedding结果做Hing损失计算。
- 余弦相似度
torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction=‘mean’)- 功能:对两个向量做余弦相似度。
- CTC损失函数
torch.nn.CTCLoss(blank=0, reduction=‘mean’, zero_infinity=False)- 功能:用于解决时序类数据的分类。
训练和评估
- 设置模型的状态:如果是训练状态,那么模型的参数应该支持反向传播的修改;如果是验证/测试状态,则不应该修改模型参数。
model.train() # 训练状态
model.eval() # 验证/测试状态
- 训练过程
读取数据
for data, label in train_loader:
之后将数据放到GPU上用于后续计算,此处以.cuda()为例
data, label = data.cuda(), label.cuda()
开始用当前批次数据做训练时,应当先将优化器的梯度置零:
optimizer.zero_grad()
之后将data送入模型中训练:
output = model(data)
根据预先定义的criterion计算损失函数:
loss = criterion(output, label)
将loss反向传播回网络:
loss.backward()
使用优化器更新模型参数:
optimizer.step()
- 验证/测试的流程基本与训练过程一致,不同点在于:
- 需要预先设置torch.no_grad,以及将model调至eval模式
- 不需要将优化器的梯度置零
- 不需要将loss反向回传到网络
- 不需要更新optimizer
可视化
- 分类的ROC曲线
- 卷积网络中的卷积核
- 训练/验证过程的损失函数曲线
优化器
- 优化器是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签。
torch.optim提供了多种优化器,如:- torch.optim.ASGD
- torch.optim.Adadelta
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.AdamW
- torch.optim.Adamax
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
- torch.optim.SparseAdam
- 以上这些优化算法均继承于
Optimizer
Fashion-Minist多分类实战
基本配置
导入必要的包
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
import torch.optim as optimizer
import torchvision
配置超参数和训练环境
batch_size=256# batch size
num_workers=0# 对于Windows用户,这里应设置为0,否则会出现多线程错误
lr=1e-4# 初始学习率(初始)
max_epochs=18# 训练次数
#GPU设置
#方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ["CUDA_VISIBLE_DEVICES"]="0"
#方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device=torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
数据读入和加载
设计转换器
from torchvision import transforms
image_size=28
data_transform=transforms.Compose([
# Converts a torch.*Tensor of shape C x H x W or a numpy ndarray of shape H x W x C to a PIL Image while preserving the value range。
transforms.ToPILImage(),# 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要。
# 调整PILImage对象的尺寸,注意不能是用io.imread或者cv2.imread读取的图片,这两种方法得到的是ndarray。下一行表示将图片短边缩放至image_size,长宽比保持不变。
transforms.Resize(image_size),
# Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor。
transforms.ToTensor()
])
读入csv格式的数据,自行构建Dataset类
train_df=pd.read_csv("./dataset/fashion-mnist/fashion-mnist_train.csv")
test_df=pd.read_csv("./dataset/fashion-mnist/fashion-mnist_test.csv")
print(train_df.head())
结果:

class FMDataset(Dataset):
def __init__(self,df,transform=None):
self.df=df
self.transform=transform
# df.values:Return a Numpy representation of the DataFrame。
self.images=df.iloc[:,1:].values.astype(np.uint8)
self.labels=df.iloc[:,0].values
def __len__(self):
return len(self.images)
def __getitem__(self,idx):
# Converts 784 to a numpy ndarray of shape H x W x C。
image=self.images[idx].reshape(28,28,1)
label=int(self.labels[idx])
# 把image transform一下,注意返回tensor类型
if self.transform is not None:
image=self.transform(image)
else:
image=torch.tensor(image/255.,dtype=torch.float)
# Converts label to a torch.*Tensor
label=torch.tensor(label,dtype=torch.long)
return image,label
train_data=FMDataset(train_df,data_transform)
test_data=FMDataset(test_df,data_transform)
使用DataLoader类加载数据
train_loader=DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=num_workers,drop_last=True)
test_loader=DataLoader(test_data,batch_size=batch_size,shuffle=False,num_workers=num_workers)
数据可视化,验证我们读入的数据是否正确
import matplotlib.pyplot as plt
image,label=next(iter(train_loader))
print(image.shape,label.shape)# torch.Size([batch_size,C,H,W]),torch.Size([batch_size])
plt.imshow(image[0][0],cmap="gray")
结果:

模型设计
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# torch.nn.Sequential是一个有序的容器,该类将按照传入构造器的顺序,依次创建相应的函数,并记录在Sequential类对象的数据结构中,同时以神经网络模块为元素的有序字典也可以作为传入参数。
self.conv=nn.Sequential(
# torch.nn.Conv2d(in_channels, out_channels, kernel_size)
nn.Conv2d(1,32,5),
nn.ReLU(),
# nn.MaxPool2d(kernel_size,stride),stride不指定则默认和kernel_size大小一致。
nn.MaxPool2d(2,stride=2),
# 在训练过程的前向传播中,nn.Dropout(p)让每个神经元以一定概率p处于不激活的状态,以达到减少过拟合的效果。
nn.Dropout(0.3),
nn.Conv2d(32,64,5),
nn.ReLU(),
nn.MaxPool2d(2,stride=2),
nn.Dropout(0.3)
)
self.fc=nn.Sequential(
# nn.Linear(in_features,out_features)
# in_features的数量决定的参数的个数;out_features的数量决定了全连接层中神经元的个数,因为每个神经元只有一个输出。
nn.Linear(64*4*4,512),
nn.ReLU(),
nn.Linear(512,10)
)
def forward(self,x):
x=self.conv(x)
x=x.view(-1,64*4*4)
x=self.fc(x)
# x = nn.functional.normalize(x)
return x
model=Net()
model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法。
结果:

设定损失函数
- 使用torch.nn模块自带的CrossEntropy损失。
- PyTorch会自动把整数型的label转为one-hot型,用于计算CE loss。
- 这里需要确保label是从0开始的,同时模型不加softmax层(使用logits计算),这也说明了PyTorch训练中各个部分不是独立的,需要通盘考虑。
criterion=nn.CrossEntropyLoss()
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])
设定优化器
optimizer=optimizer.Adam(model.parameters(),lr=1e-3)
训练和测试(验证)
两者的主要区别:
- 模型状态设置
- 是否需要初始化优化器
- 是否需要将loss传回到网络
- 是否需要每步更新optimizer
训练
- 清空所有已优化变量的梯度。
- 前向传播:向模型输入,计算预测输出。
- 计算损失。
- 反向传播:计算损失相对于模型参数的梯度。
- 执行一个优化步骤(参数更新)。
- 更新平均训练损失。
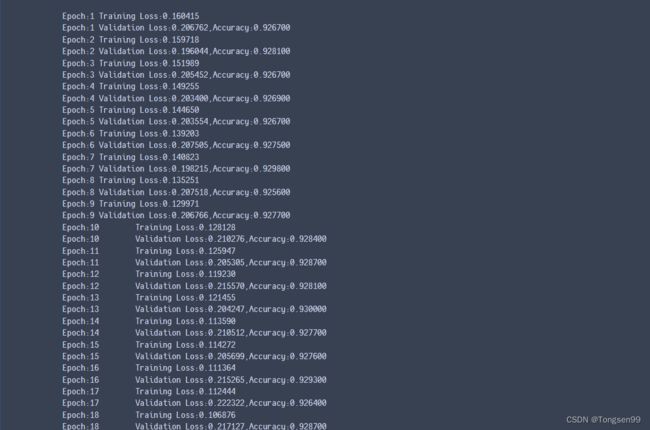
def train(epoch):
# prep model for training
model.train()
train_loss=0
for data,label in train_loader:
data,label=data.cuda(),label.cuda()
optimizer.zero_grad()
output=model(data)
loss=criterion(output,label)
loss.backward()
optimizer.step()
# 除了loss.backward()之外的loss调用都写成loss.item()
train_loss+=loss.item()*data.size(0)
train_loss=train_loss/len(train_loader.dataset)
print("Epoch:{}\tTraining Loss:{:.6f}".format(epoch,train_loss))
测试(验证)
- model.eval()会将模型中的所有层级设为评估模式(不修改模型参数),这样会影响到丢弃层等层级。
def val(epoch):
model.eval()
val_loss=0
gt_labels=[]
pred_labels=[]
with torch.no_grad():
for data,label in test_loader:
data,label=data.cuda(),label.cuda()
output=model(data)
# torch.argmax(input, dim=None, keepdim=False)返回指定维度最大值的序号。
preds=torch.argmax(output,1)
# 输出数据去cuda,转为numpy,因为计算预测acc、auc这类型的评估参数时,实在cpu上进行的,所以模型evaluate时,需要将loss之类的转到cpu上。
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss=criterion(output,label)
val_loss+=loss.item()*data.size(0)
val_loss=val_loss/len(test_loader.dataset)
gt_labels,pred_labels=np.concatenate(gt_labels),np.concatenate(pred_labels)
acc=np.sum(gt_labels==pred_labels)/len(pred_labels)
print("Epoch:{}\tValidation Loss:{:.6f},Accuracy:{:6f}".format(epoch,val_loss,acc))
for epoch in range(1,max_epochs+1):
train(epoch)
val(epoch)
结果:
参考:DataWhale——深入浅出的PyTorch